Som vi vet kan den övervakade maskininlärningsalgoritmen i stort sett klassificeras i regression och klassificeringsalgoritmer. I regressionsalgoritmer har vi förutspått utdata för kontinuerliga värden, men för att förutsäga de kategoriska värdena behöver vi klassificeringsalgoritmer.
Vad är klassificeringsalgoritmen?
Klassificeringsalgoritmen är en övervakad inlärningsteknik som används för att identifiera kategorin av nya observationer på basis av träningsdata. I klassificering lär sig ett program av den givna datamängden eller observationerna och klassificerar sedan nya observationer i ett antal klasser eller grupper. Till exempel, Ja eller Nej, 0 eller 1, Spam eller Inte Spam, katt eller hund, etc. Klasser kan kallas som mål/etiketter eller kategorier.
solig deol
Till skillnad från regression är utdatavariabeln för klassificering en kategori, inte ett värde, såsom 'grönt eller blått', 'frukt eller djur', etc. Eftersom klassificeringsalgoritmen är en övervakad inlärningsteknik kräver den märkta indata, vilket betyder att den innehåller indata med motsvarande utgång.
I klassificeringsalgoritmen mappas en diskret utdatafunktion(y) till indatavariabel(x).
y=f(x), where y = categorical output
Det bästa exemplet på en ML-klassificeringsalgoritm är Spamdetektor för e-post .
Huvudmålet med klassificeringsalgoritmen är att identifiera kategorin för en given datamängd, och dessa algoritmer används huvudsakligen för att förutsäga utdata för kategoridata.
Klassificeringsalgoritmer kan förstås bättre med hjälp av diagrammet nedan. I diagrammet nedan finns två klasser, klass A och klass B. Dessa klasser har egenskaper som liknar varandra och skiljer sig från andra klasser.
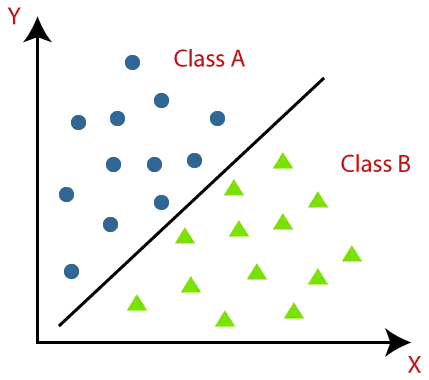
Algoritmen som implementerar klassificeringen på en datauppsättning är känd som en klassificerare. Det finns två typer av klassificeringar:
Exempel: JA eller NEJ, MAN eller KVINNA, SPAM eller INTE SPAM, KATT eller HUND, etc.
Exempel: Klassificeringar av typer av grödor, Klassificering av typer av musik.
Elever i klassificeringsproblem:
I klassificeringsproblemen finns det två typer av elever:
Exempel: K-NN algoritm, Case-based resonemang
Typer av ML-klassificeringsalgoritmer:
Klassificeringsalgoritmer kan ytterligare delas in i kategorin huvudsakligen två:
- Logistisk tillbakagång
- Stöd Vector Machines
- K-Närmaste grannar
- Kärna SVM
- Na�ve Bayes
- Beslutsträdsklassificering
- Slumpmässig skogsklassificering
Obs: Vi kommer att lära oss ovanstående algoritmer i senare kapitel.
Utvärdera en klassificeringsmodell:
När vår modell är klar är det nödvändigt att utvärdera dess prestanda; antingen är det en klassificerings- eller regressionsmodell. Så för att utvärdera en klassificeringsmodell har vi följande sätt:
1. Loggförlust eller kors-entropiförlust:
- Den används för att utvärdera prestandan hos en klassificerare, vars utdata är ett sannolikhetsvärde mellan 0 och 1.
- För en bra binär klassificeringsmodell bör värdet av logförlust vara nära 0.
- Värdet på stockförlust ökar om det förutsagda värdet avviker från det faktiska värdet.
- Den lägre stockförlusten representerar modellens högre noggrannhet.
- För binär klassificering kan korsentropi beräknas som:
?(ylog(p)+(1?y)log(1?p))
Där y = faktisk uteffekt, p = förutspådd uteffekt.
2. Förvirringsmatris:
- Förvirringsmatrisen ger oss en matris/tabell som utdata och beskriver modellens prestanda.
- Det är också känt som felmatrisen.
- Matrisen består av förutsägelser resulterar i en sammanfattad form, som har ett totalt antal korrekta förutsägelser och felaktiga förutsägelser. Matrisen ser ut som nedanstående tabell:
| Faktiskt positivt | Faktiskt negativt | |
|---|---|---|
| Förutspått positivt | Riktigt positiv | Falskt positivt |
| Förutspått negativ | Falskt negativ | Riktigt negativ |

3. AUC-ROC-kurva:
sträng konvertera till int i java
- ROC-kurva står för Mottagarens funktionskurva och AUC står för Område under kurvan .
- Det är en graf som visar klassificeringsmodellens prestanda vid olika trösklar.
- För att visualisera prestandan hos flerklassklassificeringsmodellen använder vi AUC-ROC-kurvan.
- ROC-kurvan plottas med TPR och FPR, där TPR (True Positive Rate) på Y-axeln och FPR (False Positive Rate) på X-axeln.
Användningsfall av klassificeringsalgoritmer
Klassificeringsalgoritmer kan användas på olika platser. Nedan följer några populära användningsfall av klassificeringsalgoritmer:
- Upptäcka skräppost via e-post
- Taligenkänning
- Identifiering av cancertumörceller.
- Läkemedelsklassificering
- Biometrisk identifiering etc.