Vad är LRU Cache?
Algoritmer för cacheersättning är effektivt utformade för att ersätta cachen när utrymmet är fullt. De Senast använda (LRU) är en av dessa algoritmer. Som namnet antyder när cacheminnet är fullt, LRU väljer den data som har använts minst nyligen och tar bort den för att göra utrymme för den nya datan. Prioriteten för datan i cachen ändras i enlighet med behovet av den datan, dvs om vissa data hämtas eller uppdateras nyligen så skulle prioriteten för den datan ändras och tilldelas högsta prioritet, och prioriteten för datan minskar om den kvarstår oanvända operationer efter operationer.
Innehållsförteckning
- Vad är LRU Cache?
- Operationer på LRU-cache:
- LRU-cache fungerar:
- Sätt att implementera LRU-cache:
- LRU-cacheimplementering med hjälp av Queue och Hashing:
- LRU-cacheimplementering med dubbellänkad lista och hashing:
- LRU-cache-implementering med Deque & Hashmap:
- LRU-cache-implementering med Stack & Hashmap:
- LRU-cache med hjälp av Counter Implementation:
- LRU-cacheimplementering med hjälp av Lazy Updates:
- Komplexitetsanalys av LRU-cache:
- Fördelar med LRU-cache:
- Nackdelar med LRU-cache:
- Real-World Application av LRU Cache:
LRU Algoritm är ett standardproblem och det kan ha variationer efter behov, till exempel i operativsystem LRU spelar en avgörande roll eftersom den kan användas som en sidbytesalgoritm för att minimera sidfel.
Operationer på LRU-cache:
- LRUCache (Kapacitet c): Initiera LRU-cache med positiv storlekskapacitet c.
- få (nyckel) : Returnerar värdet på Key ' k' om den finns i cachen annars returnerar den -1. Uppdaterar även dataprioriteten i LRU-cachen.
- put (nyckel, värde): Uppdatera nyckelns värde om den nyckeln finns. Annars lägger du till nyckel-värdepar i cachen. Om antalet nycklar överskrider kapaciteten för LRU-cachen, avvisa den senast använda nyckeln.
LRU-cache fungerar:
Låt oss anta att vi har en LRU-cache med kapacitet 3, och vi skulle vilja utföra följande operationer:
- Lägg (nyckel=1, värde=A) i cachen
- Lägg (nyckel=2, värde=B) i cachen
- Lägg (nyckel=3, värde=C) i cachen
- Hämta (nyckel=2) från cachen
- Hämta (nyckel=4) från cachen
- Lägg (nyckel=4, värde=D) i cachen
- Lägg (nyckel=3, värde=E) i cachen
- Hämta (nyckel=4) från cachen
- Lägg (nyckel=1, värde=A) i cachen
Ovanstående operationer utförs en efter en som visas i bilden nedan:
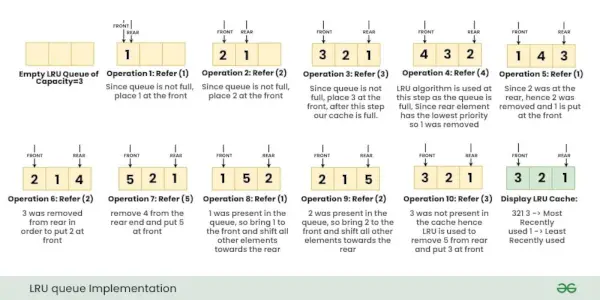
Detaljerad förklaring av varje operation:
- Sätt (nyckel 1, värde A) : Eftersom LRU-cachen har tom kapacitet=3, behövs ingen ersättning och vi sätter {1 : A} överst, dvs. {1 : A} har högsta prioritet.
- Sätt (nyckel 2, värde B) : Eftersom LRU-cachen har tom kapacitet=2, finns det återigen inget behov av någon ersättning, men nu har {2 : B} högsta prioritet och prioritet av {1 : A}-minskning.
- Sätt (nyckel 3, värde C) : Det finns fortfarande 1 tomt utrymme ledigt i cachen, lägg därför {3 : C} utan någon ersättning, märk nu att cachen är full och den nuvarande prioritetsordningen från högsta till lägsta är {3:C}, {2:B }, {1:A}.
- Hämta (nyckel 2) : Returnera nu värdet på key=2 under denna operation, eftersom key=2 används, är den nya prioritetsordningen nu {2:B}, {3:C}, {1:A}
- Hämta (nyckel 4): Observera att nyckel 4 inte finns i cachen, vi returnerar '-1' för denna operation.
- Sätt (nyckel 4, värde D) : Observera att cachen är FULL, använd nu LRU-algoritmen för att avgöra vilken nyckel som senast användes. Eftersom {1:A} hade minst prioritet, ta bort {1:A} från vår cache och placera {4:D} i cachen. Observera att den nya prioritetsordningen är {4:D}, {2:B}, {3:C}
- Sätt (nyckel 3, värde E) : Eftersom key=3 redan fanns i cachen med värdet=C, så kommer denna operation inte att resultera i att någon nyckel tas bort, snarare kommer den att uppdatera värdet på key=3 till ' OCH' . Nu kommer den nya prioritetsordningen att bli {3:E}, {4:D}, {2:B}
- Hämta (nyckel 4) : Returnera värdet för nyckel=4. Nu kommer ny prioritet att bli {4:D}, {3:E}, {2:B}
- Sätt (nyckel 1, värde A) : Eftersom vår cache är FULL, så använd vår LRU-algoritm för att avgöra vilken nyckel som användes senast, och eftersom {2:B} hade minst prioritet, ta bort {2:B} från vår cache och lägg in {1:A} i cache. Nu är den nya prioritetsordningen {1:A}, {4:D}, {3:E}
Sätt att implementera LRU-cache:
LRU-cache kan implementeras på en mängd olika sätt, och varje programmerare kan välja ett annat tillvägagångssätt. Men nedan är vanliga metoder:
- LRU använder Queue och Hashing
- LRU använder Dubbelt länkad lista + hashing
- LRU använder Deque
- LRU använder Stack
- LRU använder Motimplementering
- LRU använder Lazy Updates
LRU-cacheimplementering med hjälp av Queue och Hashing:
Vi använder två datastrukturer för att implementera en LRU-cache.
- Kö implementeras med hjälp av en dubbellänkad lista. Den maximala storleken på kön kommer att vara lika med det totala antalet tillgängliga ramar (cachestorlek). De senast använda sidorna kommer att vara nära framsidan och de senast använda sidorna kommer att vara nära baksidan.
- En Hash med sidnumret som nyckel och adressen till motsvarande könod som värde.
När en sida refereras kan den önskade sidan finnas i minnet. Om det finns i minnet måste vi ta bort noden på listan och föra den längst fram i kön.
Om den önskade sidan inte finns i minnet tar vi med den i minnet. Med enkla ord lägger vi till en ny nod längst fram i kön och uppdaterar motsvarande nodadress i hashen. Om kön är full, det vill säga alla ramar är fulla, tar vi bort en nod från den bakre delen av kön och lägger till den nya noden längst fram i kön.
Illustration:
Låt oss överväga operationerna, Hänvisar nyckel x med i LRU-cachen: { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
Notera: Till en början finns ingen sida i minnet.Nedan bilder visar steg för steg exekvering av ovanstående operationer på LRU-cachen.
Algoritm:
- Skapa en klass LRUCache med deklarera en lista av typen int, en oordnad karta av typen
- I referensfunktionen för LRUCache
- Om detta värde inte finns i kön, skjut det här värdet framför kön och ta bort det sista värdet om kön är full
- Om värdet redan finns, ta bort det från kön och skjut det längst fram i kön
- I displayfunktionen skriver ut LRUCache med hjälp av kön som börjar framifrån
Nedan är implementeringen av ovanstående tillvägagångssätt:
C++
strängformatering java
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>dq;> > >// store references of key in cache> >unordered_map<>int>, list<>int>>::iterator> ma;> >int> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>' '>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
>
C
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->pageNumber = pageNumber;> > >// Initialize prev and next as NULL> >temp->prev = temp->nästa = NULL;> > >return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->räkna = 0;> >queue->front = kö->bak = NULL;> > >// Number of frames that can be stored in memory> >queue->numberOfFrames = numberOfFrames;> > >return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->kapacitet = kapacitet;> > >// Create an array of pointers for referring queue nodes> >hash->array> >= (QNode**)>malloc>(hash->kapacitet *>sizeof>(QNode*));> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->array[i] = NULL;> > >return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->count == kö->antal ramar;> }> > // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->bak == NULL;> }> > // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->främre == kö->bak)> >queue->front = NULL;> > >// Change rear and remove the previous rear> >QNode* temp = queue->bak;> >queue->bak = kö->bak->föregående;> > >if> (queue->bak)> >queue->bak->nästa = NULL;> > >free>(temp);> > >// decrement the number of full frames by 1> >queue->räkna--;> }> > // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->array[queue->rear->pageNumber] = NULL;> >deQueue(queue);> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->nästa = kö->front;> > >// If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->bak = kö->fram = temp;> >else> // Else change the front> >{> >queue->front->prev = temp;> >queue->front = temp;> >}> > >// Add page entry to hash also> >hash->array[pageNumber] = temp;> > >// increment number of full frames> >queue->räkna++;> }> > // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->array[sidnummer];> > >// the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->front) {> >// Unlink rquested page from its current location> >// in queue.> >reqPage->prev->next = reqPage->next;> >if> (reqPage->nästa)> >reqPage->next->prev = reqPage->prev;> > >// If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->bak) {> >queue->rear = reqPage->prev;> >queue->bak->nästa = NULL;> >}> > >// Put the requested page before current front> >reqPage->nästa = kö->front;> >reqPage->prev = NULL;> > >// Change prev of current front> >reqPage->nästa->föregående = reqPage;> > >// Change front to the requested page> >queue->front = reqPage;> >}> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->front->pageNumber);> >printf>(>'%d '>, q->front->nästa->pageNumber);> >printf>(>'%d '>, q->front->next->next->pageNumber);> >printf>(>'%d '>, q->front->next->next->next->pageNumber);> > >return> 0;> }> |
>
>
Java
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>' '>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
Python3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
C#
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>dubbelkö;> > >// store references of key in cache> >private> HashSet<>int>>hashSet;> > >// maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();> >hashSet =>new> HashSet<>int>>();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>' '>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
Javascript
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
>
LRU-cache-implementering med dubbellänkad lista och hashing :
Tanken är väldigt grundläggande, d.v.s. fortsätt att sätta in elementen vid huvudet.
- om elementet inte finns i listan, lägg till det i huvudet på listan
- om elementet finns i listan, flytta elementet till huvudet och flytta det återstående elementet i listan
Observera att nodens prioritet kommer att bero på nodens avstånd från huvudet, ju närmast noden är huvudet, högre prioritet har den. Så när Cache-storleken är full och vi behöver ta bort något element, tar vi bort elementet intill svansen av den dubbelt länkade listan.
LRU-cache-implementering med Deque & Hashmap:
Deque-datastrukturen tillåter infogning och radering från fronten såväl som från slutet, den här egenskapen möjliggör implementering av LRU eftersom frontelementet kan representera högprioritetselement medan slutelementet kan vara lågprioritetselementet, d.v.s. minst nyligen använt.
Arbetssätt:
- Få Operation : Kontrollerar om nyckeln finns i cachens hashkarta och följ nedanstående fall på deque:
- Om nyckel hittas:
- Objektet anses vara nyligen använt, så det flyttas till framsidan av deque.
- Värdet som är associerat med nyckeln returneras som ett resultat av
get>drift.- Om nyckeln inte hittas:
- returnera -1 för att indikera att ingen sådan nyckel finns.
- Put Operation: Kontrollera först om nyckeln redan finns i cachens hashkarta och följ nedanstående fall på dequen
- Om nyckel finns:
- Värdet som är kopplat till nyckeln uppdateras.
- Objektet flyttas till framsidan av dequet eftersom det nu är det senast använda.
- Om nyckeln inte finns:
- Om cachen är full betyder det att ett nytt föremål måste infogas och det senast använda föremålet måste vräkas. Detta görs genom att ta bort objektet från slutet av dequen och motsvarande post från hashkartan.
- Det nya nyckel-värdeparet infogas sedan i både hashkartan och framsidan av dequen för att indikera att det är det senast använda föremålet
LRU-cache-implementering med Stack & Hashmap:
Att implementera en LRU (Last Recently Used) cache med hjälp av en stackdatastruktur och hash kan vara lite knepigt eftersom en enkel stack inte ger effektiv åtkomst till det senast använda objektet. Du kan dock kombinera en stack med en hashkarta för att uppnå detta effektivt. Här är en metod på hög nivå för att implementera det:
- Använd en Hash-karta : Hashkartan lagrar nyckel-värdeparen i cachen. Nycklarna kommer att mappas till motsvarande noder i stacken.
- Använd en stack : Stacken kommer att behålla ordningen på nycklar baserat på deras användning. Det senast använda föremålet kommer att vara längst ner i stapeln, och det senast använda föremålet kommer att vara överst
Detta tillvägagångssätt är inte så effektivt och används därför inte ofta.
nätverk och typer
LRU-cache med hjälp av Counter Implementation:
Varje block i cachen kommer att ha sin egen LRU-räknare där värdet på räknaren tillhör {0 till n-1} , här' n ' representerar storleken på cachen. Blocket som ändras under blockersättningen blir MRU-blocket, och som ett resultat ändras dess räknarvärde till n – 1. Räknarvärdena som är större än det åtkomliga blockets räknarvärde minskas med ett. De återstående blocken är oförändrade.
| Värdet av Conter | Prioritet | Använd status |
|---|---|---|
| 0 | Låg | Senast använda |
| n-1 | Hög | Senast använd |
LRU-cacheimplementering med hjälp av Lazy Updates:
Att implementera en LRU (Least Recently Used) cache med lata uppdateringar är en vanlig teknik för att förbättra effektiviteten i cachens operationer. Lata uppdateringar innebär att spåra i vilken ordning objekt nås utan att omedelbart uppdatera hela datastrukturen. När en cachemiss inträffar kan du sedan bestämma om du vill utföra en fullständig uppdatering eller inte baserat på vissa kriterier.
Komplexitetsanalys av LRU-cache:
- Tidskomplexitet:
- Put() operation: O(1) d.v.s. tiden som krävs för att infoga eller uppdatera nytt nyckel-värdepar är konstant
- Get() operation: O(1) dvs tiden som krävs för att få värdet på en nyckel är konstant
- Hjälputrymme: O(N) där N är cachens kapacitet.
Fördelar med LRU-cache:
- Snabb åtkomst : Det tar O(1) tid att komma åt data från LRU-cachen.
- Snabb uppdatering : Det tar O(1) tid att uppdatera ett nyckel-värdepar i LRU-cachen.
- Snabb borttagning av senast använda data : Det tar O(1) att ta bort det som inte har använts nyligen.
- Ingen smäll: LRU är mindre mottaglig för thrashing jämfört med FIFO eftersom den tar hänsyn till sidornas användningshistorik. Den kan upptäcka vilka sidor som används ofta och prioritera dem för minnesallokering, vilket minskar antalet sidfel och disk I/O-operationer.
Nackdelar med LRU-cache:
- Det kräver stor cachestorlek för att öka effektiviteten.
- Det kräver ytterligare datastruktur för att implementeras.
- Hårdvaruhjälpen är hög.
- I LRU är feldetektering svårt jämfört med andra algoritmer.
- Det har begränsad acceptans.
Real-World Application av LRU Cache:
- I databassystem för snabba frågeresultat.
- I operativsystem för att minimera sidfel.
- Textredigerare och IDE:er för att lagra ofta använda filer eller kodavsnitt
- Nätverksroutrar och switchar använder LRU för att öka effektiviteten i datornätverk
- I kompilatoroptimeringar
- Verktyg för textprediktion och autokomplettering