En markör i SQL Server är en d atabase-objekt som låter oss hämta varje rad åt gången och manipulera dess data . En markör är inget annat än en pekare till en rad. Det används alltid tillsammans med en SELECT-sats. Det är vanligtvis en samling av SQL logik som går igenom ett förutbestämt antal rader en efter en. En enkel illustration av markören är när vi har en omfattande databas med arbetarregister och vill beräkna varje arbetares lön efter avdrag för skatter och ledighet.
SQL-servern Markörens syfte är att uppdatera data rad för rad, ändra dem eller utföra beräkningar som inte är möjliga när vi hämtar alla poster samtidigt . Det är också användbart för att utföra administrativa uppgifter som SQL Server-databassäkerhetskopiering i sekventiell ordning. Markörer används främst i utvecklings-, DBA- och ETL-processer.
Den här artikeln förklarar allt om SQL Server-markören, såsom markörens livscykel, varför och när markören används, hur man implementerar markörer, dess begränsningar och hur vi kan ersätta en markör.
Markörens livscykel
Vi kan beskriva livscykeln för en markör in i fem olika avsnitt som följer:
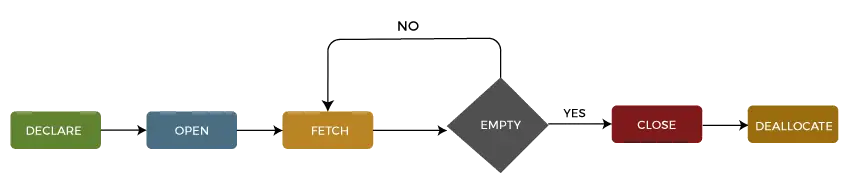
1: Ange markör
Det första steget är att deklarera markören med hjälp av följande SQL-sats:
byt namn på katalogen linux
DECLARE cursor_name CURSOR FOR select_statement;
Vi kan deklarera en markör genom att ange dess namn med datatypen CURSOR efter nyckelordet DECLARE. Sedan kommer vi att skriva SELECT-satsen som definierar utdata för markören.
2: Öppna markören
Det är ett andra steg där vi öppnar markören för att lagra data som hämtats från resultatuppsättningen. Vi kan göra detta genom att använda följande SQL-sats:
OPEN cursor_name;
3: Hämta markör
Det är ett tredje steg där rader kan hämtas en efter en eller i ett block för att utföra datamanipulation som att infoga, uppdatera och ta bort operationer på den för närvarande aktiva raden i markören. Vi kan göra detta genom att använda följande SQL-sats:
FETCH NEXT FROM cursor INTO variable_list;
Vi kan också använda @@FETCHSTATUS funktion i SQL Server för att få status för den senaste FETCH-satsmarkören som kördes mot markören. De HÄMTA satsen lyckades när @@FETCHSTATUS ger noll utdata. De MEDAN uttalande kan användas för att hämta alla poster från markören. Följande kod förklarar det tydligare:
WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM cursor_name; END;
4: Stäng markören
Det är ett fjärde steg där markören ska stängas efter att vi avslutat arbetet med en markör. Vi kan göra detta genom att använda följande SQL-sats:
CLOSE cursor_name;
5: Avallokera markören
Det är det femte och sista steget där vi kommer att radera markördefinitionen och släppa alla systemresurser som är associerade med markören. Vi kan göra detta genom att använda följande SQL-sats:
DEALLOCATE cursor_name;
Användning av SQL Server Cursor
Vi vet att relationsdatabashanteringssystem, inklusive SQL Server, är utmärkta för att hantera data på en uppsättning rader som kallas resultatuppsättningar. Till exempel , vi har ett bord produkttabell som innehåller produktbeskrivningarna. Om vi vill uppdatera pris av produkten, sedan nedan ' UPPDATERING' fråga kommer att uppdatera alla poster som matchar villkoret i ' VAR' klausul:
UPDATE product_table SET unit_price = 100 WHERE product_id = 105;
Ibland behöver applikationen bearbeta raderna på ett enkelt sätt, d.v.s. på rad för rad snarare än hela resultatuppsättningen på en gång. Vi kan göra denna process genom att använda markörer i SQL Server. Innan du använder markören måste vi veta att markörerna är mycket dåliga i prestanda, så den bör alltid användas endast när det inte finns något alternativ förutom markören.
Markören använder samma teknik som vi använder loopar som FOREACH, FOR, WHILE, DO WHILE för att iterera ett objekt i taget i alla programmeringsspråk. Därför kan det väljas eftersom det tillämpar samma logik som programmeringsspråkets loopingprocess.
Typer av markörer i SQL Server
Följande är de olika typerna av markörer i SQL Server listade nedan:
- Statiska markörer
- Dynamiska markörer
- Endast framåt-markörer
- Keyset Cursors

Statiska markörer
Resultatuppsättningen som visas av den statiska markören är alltid densamma som när markören först öppnades. Eftersom den statiska markören kommer att lagra resultatet i tempdb , de är alltid skrivskyddad . Vi kan använda den statiska markören för att flytta både framåt och bakåt. Till skillnad från andra markörer är den långsammare och förbrukar mer minne. Som ett resultat kan vi bara använda den när rullning är nödvändig och andra markörer inte är lämpliga.
Den här markören visar rader som togs bort från databasen efter att den öppnades. En statisk markör representerar inga INSERT-, UPDATE- eller DELETE-operationer (såvida inte markören stängs och öppnas igen).
Dynamiska markörer
De dynamiska markörerna är motsatta de statiska markörerna som gör att vi kan utföra datauppdatering, radering och infogning medan markören är öppen. Det är rullningsbar som standard . Den kan upptäcka alla ändringar som gjorts i raderna, ordningen och värdena i resultatuppsättningen, oavsett om ändringarna sker inuti markören eller utanför markören. Utanför markören kan vi inte se uppdateringarna förrän de har begåtts.
Endast framåt-markörer
Det är den förinställda och snabbaste markörtypen bland alla markörer. Det kallas en framåtriktad markör eftersom det går bara framåt genom resultatuppsättningen . Den här markören stöder inte rullning. Den kan bara hämta rader från början till slutet av resultatuppsättningen. Det tillåter oss att utföra infogning, uppdatering och radering. Här är effekten av infogning, uppdatering och borttagning som görs av användaren som påverkar rader i resultatuppsättningen synliga när raderna hämtas från markören. När raden hämtades kan vi inte se ändringarna som gjorts på rader genom markören.
De framåtriktade markörerna är tre kategoriserade i tre typer:
- Forward_Only Keyset
- Forward_Only Static
- Snabbspola

Keyset drivna markörer
Denna markörfunktionalitet ligger mellan en statisk och en dynamisk markör om dess förmåga att upptäcka förändringar. Den kan inte alltid upptäcka ändringar i resultatuppsättningens medlemskap och ordning som en statisk markör. Den kan upptäcka förändringar i resultatuppsättningens radvärden som en dynamisk markör. Det kan bara flytta från första till sista och sist till första raden . Ordningen och medlemskapet är fasta när den här markören öppnas.
Den styrs av en uppsättning unika identifierare som är samma som nycklarna i nyckeluppsättningen. Nyckeluppsättningen bestäms av alla rader som kvalificerade SELECT-satsen när markören först öppnades. Den kan också upptäcka eventuella ändringar i datakällan, vilket stöder uppdaterings- och raderingsåtgärder. Den är rullbar som standard.
Implementering av exempel
Låt oss implementera markörexemplet i SQL-servern. Vi kan göra detta genom att först skapa en tabell med namnet ' kund ' med hjälp av följande uttalande:
java få aktuellt datum
CREATE TABLE customer ( id int PRIMARY KEY, c_name nvarchar(45) NOT NULL, email nvarchar(45) NOT NULL, city nvarchar(25) NOT NULL );
Därefter kommer vi att infoga värden i tabellen. Vi kan köra nedanstående sats för att lägga till data i en tabell:
INSERT INTO customer (id, c_name, email, city) VALUES (1,'Steffen', '[email protected]', 'Texas'), (2, 'Joseph', '[email protected]', 'Alaska'), (3, 'Peter', '[email protected]', 'California'), (4,'Donald', '[email protected]', 'New York'), (5, 'Kevin', '[email protected]', 'Florida'), (6, 'Marielia', '[email protected]', 'Arizona'), (7,'Antonio', '[email protected]', 'New York'), (8, 'Diego', '[email protected]', 'California');
Vi kan verifiera uppgifterna genom att köra VÄLJ påstående:
SELECT * FROM customer;
Efter att ha kört frågan kan vi se utdata nedan där vi har åtta rader in i tabellen:

Nu kommer vi att skapa en markör för att visa kundposterna. Nedanstående kodsnuttar förklarar alla steg i markördeklarationen eller skapandet genom att sätta ihop allt:
java giltiga identifierare
--Declare the variables for holding data. DECLARE @id INT, @c_name NVARCHAR(50), @city NVARCHAR(50) --Declare and set counter. DECLARE @Counter INT SET @Counter = 1 --Declare a cursor DECLARE PrintCustomers CURSOR FOR SELECT id, c_name, city FROM customer --Open cursor OPEN PrintCustomers --Fetch the record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city --LOOP UNTIL RECORDS ARE AVAILABLE. WHILE @@FETCH_STATUS = 0 BEGIN IF @Counter = 1 BEGIN PRINT 'id' + CHAR(9) + 'c_name' + CHAR(9) + CHAR(9) + 'city' PRINT '--------------------------' END --Print the current record PRINT CAST(@id AS NVARCHAR(10)) + CHAR(9) + @c_name + CHAR(9) + CHAR(9) + @city --Increment the counter variable SET @Counter = @Counter + 1 --Fetch the next record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city END --Close the cursor CLOSE PrintCustomers --Deallocate the cursor DEALLOCATE PrintCustomers
Efter att ha kört en markör får vi följande utdata:

Begränsningar för SQL Server Cursor
En markör har vissa begränsningar så att den alltid bör användas endast när det inte finns något alternativ förutom markören. Dessa begränsningar är:
- Markören förbrukar nätverksresurser genom att kräva en nätverksresa varje gång den hämtar en post.
- En markör är en minnesrelaterad uppsättning pekare, vilket betyder att den tar lite minne som andra processer kan använda på vår maskin.
- Det sätter lås på en del av tabellen eller hela tabellen vid bearbetning av data.
- Markörens prestanda och hastighet är långsammare eftersom de uppdaterar tabellposter en rad i taget.
- Markörer är snabbare än while-loopar, men de har mer overhead.
- Antalet rader och kolumner som förs in i markören är en annan aspekt som påverkar markörhastigheten. Det hänvisar till hur lång tid det tar att öppna markören och köra en fetch-sats.
Hur kan vi undvika markörer?
Markörernas huvudsakliga uppgift är att gå igenom tabellen rad för rad. Det enklaste sättet att undvika markörer ges nedan:
Använder SQL while loop
Det enklaste sättet att undvika användningen av en markör är att använda en while-loop som tillåter att en resultatuppsättning infogas i den tillfälliga tabellen.
Användardefinierade funktioner
Ibland används markörer för att beräkna den resulterande raduppsättningen. Vi kan åstadkomma detta genom att använda en användardefinierad funktion som uppfyller kraven.
Använder Joins
Join bearbetar endast de kolumner som uppfyller det angivna villkoret och minskar därmed kodraderna som ger snabbare prestanda än markörer i fall stora poster behöver bearbetas.