I den här artikeln kommer vi att diskutera DFS-algoritmen i datastrukturen. Det är en rekursiv algoritm för att söka i alla hörn i en träddatastruktur eller en graf. Algoritmen för djup-först-sökning (DFS) börjar med den initiala noden i graf G och går djupare tills vi hittar målnoden eller noden utan barn.
På grund av den rekursiva naturen kan stackdatastrukturen användas för att implementera DFS-algoritmen. Processen att implementera DFS liknar BFS-algoritmen.
Steg-för-steg-processen för att implementera DFS-traverseringen ges enligt följande -
- Skapa först en stack med det totala antalet hörn i grafen.
- Välj nu vilken vertex som helst som startpunkt för korsningen och tryck in den vertexen i stapeln.
- Efter det, tryck en icke-besökt vertex (intill toppen av stapeln) till toppen av stapeln.
- Upprepa nu steg 3 och 4 tills det inte finns några hörn kvar att besöka från vertexet på högens topp.
- Om ingen vertex finns kvar, gå tillbaka och skjuta en vertex från stapeln.
- Upprepa steg 2, 3 och 4 tills bunten är tom.
Tillämpningar av DFS-algoritm
Tillämpningarna för att använda DFS-algoritmen ges enligt följande -
- DFS-algoritm kan användas för att implementera den topologiska sorteringen.
- Den kan användas för att hitta vägarna mellan två hörn.
- Den kan också användas för att upptäcka cykler i grafen.
- DFS-algoritm används också för pussel med en lösning.
- DFS används för att avgöra om en graf är tvådelad eller inte.
Algoritm
Steg 1: SET STATUS = 1 (färdigt tillstånd) för varje nod i G
Steg 2: Tryck på startnoden A på stacken och ställ in dess STATUS = 2 (vänteläge)
iPhone emojis på Android
Steg 3: Upprepa steg 4 och 5 tills STACKEN är tom
Steg 4: Pop den översta noden N. Bearbeta den och ställ in dess STATUS = 3 (bearbetat tillstånd)
Steg 5: Tryck på stacken alla grannar till N som är i redoläge (vars STATUS = 1) och ställ in deras STATUS = 2 (vänteläge)
[SLUT PÅ LOOP]
Steg 6: UTGÅNG
Pseudokod
DFS(G,v) ( v is the vertex where the search starts ) Stack S := {}; ( start with an empty stack ) for each vertex u, set visited[u] := false; push S, v; while (S is not empty) do u := pop S; if (not visited[u]) then visited[u] := true; for each unvisited neighbour w of uu push S, w; end if end while END DFS() Exempel på DFS-algoritm
Låt oss nu förstå hur DFS-algoritmen fungerar genom att använda ett exempel. I exemplet nedan finns en riktad graf med 7 hörn.
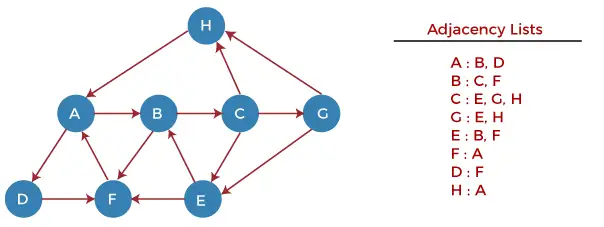
Låt oss nu börja undersöka grafen från Nod H.
Steg 1 - Tryck först på H på traven.
STACK: H
Steg 2 - POPPA det översta elementet från stapeln, d.v.s. H, och skriv ut det. SKÖT nu alla grannar till H på stacken som är i redo-läge.
Print: H]STACK: A
Steg 3 - POPPA det översta elementet från stapeln, dvs A, och skriv ut det. SKÖT nu alla grannar till A på stapeln som är i redo-läge.
Print: A STACK: B, D
Steg 4 - POPPA det översta elementet från stapeln, d.v.s. D, och skriv ut det. SKÖT nu alla grannar till D på stacken som är i redo-läge.
Print: D STACK: B, F
Steg 5 - POPPA det översta elementet från stapeln, dvs F, och skriv ut det. SKÖT nu alla grannar till F på stacken som är i redo-läge.
Print: F STACK: B
Steg 6 - POPPA det översta elementet från stapeln, d.v.s. B, och skriv ut det. SKÖT nu alla grannar till B på stapeln som är i redo-läge.
Print: B STACK: C
Steg 7 - POPPA det översta elementet från stapeln, dvs C, och skriv ut det. SKÖT nu alla grannar till C på stacken som är i redo-läge.
Print: C STACK: E, G
Steg 8 - POPPA det översta elementet från stacken, d.v.s. G och PUSH alla grannar till G på stacken som är i redo-tillstånd.
Print: G STACK: E
Steg 9 - POPPA det översta elementet från stacken, d.v.s. E och PUSH alla grannar till E på stapeln som är i redo-tillstånd.
Print: E STACK:
Nu har alla grafnoder passerats och stacken är tom.
Komplexiteten för djup-först sökalgoritm
Tidskomplexiteten för DFS-algoritmen är O(V+E) , där V är antalet hörn och E är antalet kanter i grafen.
Rymdkomplexiteten för DFS-algoritmen är O(V).
Implementering av DFS-algoritm
Låt oss nu se implementeringen av DFS-algoritmen i Java.
I det här exemplet ges grafen som vi använder för att demonstrera koden enligt följande -

/*A sample java program to implement the DFS algorithm*/ import java.util.*; class DFSTraversal { private LinkedList adj[]; /*adjacency list representation*/ private boolean visited[]; /* Creation of the graph */ DFSTraversal(int V) /*'V' is the number of vertices in the graph*/ { adj = new LinkedList[V]; visited = new boolean[V]; for (int i = 0; i <v; i++) adj[i]="new" linkedlist(); } * adding an edge to the graph void insertedge(int src, int dest) { adj[src].add(dest); dfs(int vertex) visited[vertex]="true;" *mark current node as visited* system.out.print(vertex + ' '); iterator it="adj[vertex].listIterator();" while (it.hasnext()) n="it.next();" if (!visited[n]) dfs(n); public static main(string args[]) dfstraversal dfstraversal(8); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, system.out.println('depth first traversal for is:'); graph.dfs(0); < pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/28/dfs-algorithm-3.webp" alt="DFS algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the depth-first search technique, its example, complexity, and implementation in the java programming language. Along with that, we have also seen the applications of the depth-first search algorithm.</p> <p>So, that's all about the article. Hope it will be helpful and informative to you.</p> <hr></v;>