A Convolutional Neural Network (CNN) är en typ av Deep Learning neural nätverksarkitektur som vanligtvis används i Computer Vision. Datorseende är ett fält av artificiell intelligens som gör det möjligt för en dator att förstå och tolka bilden eller visuella data.
När det gäller maskininlärning, Artificiellt nervsystem prestera riktigt bra. Neurala nätverk används i olika datamängder som bilder, ljud och text. Olika typer av neurala nätverk används för olika ändamål, till exempel för att förutsäga sekvensen av ord vi använder Återkommande neurala nätverk närmare bestämt en LSTM , på samma sätt för bildklassificering använder vi Convolution Neural-nätverk. I den här bloggen ska vi bygga en grundläggande byggsten för CNN.
I ett vanligt neuralt nätverk finns det tre typer av lager:
npm rensa cache
- Indatalager: Det är lagret där vi ger input till vår modell. Antalet neuroner i detta lager är lika med det totala antalet funktioner i våra data (antal pixlar i fallet med en bild).
- Dolt lager: Indata från indatalagret matas sedan in i det dolda lagret. Det kan finnas många dolda lager beroende på vår modell och datastorlek. Varje gömt lager kan ha olika antal neuroner som i allmänhet är större än antalet funktioner. Utsignalen från varje lager beräknas genom matrismultiplikation av utsignalen från det föregående lagret med inlärbara vikter av det lagret och sedan genom tillägg av inlärbara förspänningar följt av aktiveringsfunktion som gör nätverket olinjärt.
- Utdatalager: Utdata från det dolda lagret matas sedan in i en logistisk funktion som sigmoid eller softmax som omvandlar utdata från varje klass till sannolikhetspoängen för varje klass.
Data matas in i modellen och utdata från varje lager erhålls från steget ovan anropas feedforward , vi beräknar sedan felet med hjälp av en felfunktion, några vanliga felfunktioner är korsentropi, kvadratförlustfel etc. Felfunktionen mäter hur bra nätverket presterar. Därefter backpropagerar vi in i modellen genom att beräkna derivatorna. Detta steg kallas Convolutional Neural Network (CNN) är den utökade versionen av artificiella neurala nätverk (ANN) som främst används för att extrahera funktionen från den rutnätsliknande matrisdatauppsättningen. Till exempel visuella datamängder som bilder eller videor där datamönster spelar en stor roll.
CNN arkitektur
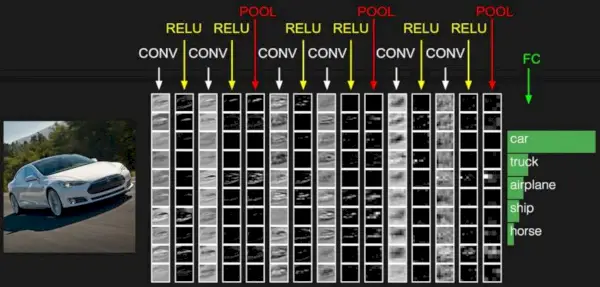
Convolutional Neural Network består av flera lager som ingångslager, Convolutional lager, Pooling lager och helt anslutna lager.

Enkel CNN-arkitektur
Konvolutionslagret tillämpar filter på ingångsbilden för att extrahera funktioner, Pooling-lagret nedsamplar bilden för att minska beräkningen och det helt anslutna lagret gör den slutliga förutsägelsen. Nätverket lär sig de optimala filtren genom backpropagation och gradient decent.
Hur Convolutional Layers fungerar
Convolution Neural Networks eller covnets är neurala nätverk som delar sina parametrar. Föreställ dig att du har en bild. Den kan representeras som en kuboid som har sin längd, bredd (bildens dimension) och höjd (dvs kanalen eftersom bilder i allmänhet har röda, gröna och blå kanaler).
Föreställ dig nu att du tar en liten lapp av den här bilden och kör ett litet neuralt nätverk, kallat ett filter eller kärna på det, med säg K-utgångar och representerar dem vertikalt. Skjut nu det neurala nätverket över hela bilden, som ett resultat kommer vi att få en annan bild med olika bredder, höjder och djup. Istället för bara R-, G- och B-kanaler har vi nu fler kanaler men mindre bredd och höjd. Denna operation kallas Veck . Om lappstorleken är densamma som bildens storlek kommer det att vara ett vanligt neuralt nätverk. På grund av denna lilla lapp har vi färre vikter.
Bildkälla: Deep Learning Udacity
Låt oss nu prata om lite matematik som är involverat i hela faltningsprocessen.
- Konvolutionslager består av en uppsättning inlärningsbara filter (eller kärnor) med små bredder och höjder och samma djup som ingångsvolymen (3 om indatalagret är bildinmatning).
- Till exempel, om vi måste köra faltning på en bild med måtten 34x34x3. Den möjliga storleken på filter kan vara axax3, där 'a' kan vara något som 3, 5 eller 7 men mindre jämfört med bilddimensionen.
- Under framåtpassningen skjuter vi varje filter över hela ingångsvolymen steg för steg där varje steg anropas kliva (som kan ha ett värde på 2, 3 eller till och med 4 för högdimensionella bilder) och beräkna punktprodukten mellan kärnvikterna och lappen från ingångsvolymen.
- När vi skjuter våra filter får vi en 2D-utgång för varje filter och vi staplar dem tillsammans som ett resultat, vi får en utmatningsvolym som har ett djup som är lika med antalet filter. Nätverket kommer att lära sig alla filter.
Lager som används för att bygga ConvNets
En komplett Convolution Neural Networks-arkitektur är också känd som covnets. En covnet är en sekvens av lager, och varje lager omvandlar en volym till en annan genom en differentierbar funktion.
Typer av lager: datauppsättningar
Låt oss ta ett exempel genom att köra en kåpa på en bild med dimensionen 32 x 32 x 3.
- Indatalager: Det är lagret där vi ger input till vår modell. I CNN, i allmänhet kommer ingången att vara en bild eller en sekvens av bilder. Det här lagret innehåller bildens råa indata med bredd 32, höjd 32 och djup 3.
- Konvolutionella lager: Detta är lagret som används för att extrahera funktionen från indatadataset. Den tillämpar en uppsättning inlärningsbara filter som kallas kärnorna på ingångsbilderna. Filtren/kärnorna är mindre matriser vanligtvis 2×2, 3×3 eller 5×5 form. den glider över indatabilden och beräknar punktprodukten mellan kärnvikten och motsvarande indatabild. Utdata från detta lager kallas funktionskartor. Anta att vi använder totalt 12 filter för detta lager så får vi en utgående volym på dimensionen 32 x 32 x 12.
- Aktiveringslager: Genom att lägga till en aktiveringsfunktion till utgången från det föregående lagret, adderar aktiveringslager olinjäritet till nätverket. den kommer att tillämpa en elementvis aktiveringsfunktion på utmatningen av faltningsskiktet. Några vanliga aktiveringsfunktioner är återuppta : max(0, x), Skum , Läckande RELU , etc. Volymen förblir oförändrad, så utmatningsvolymen kommer att ha måtten 32 x 32 x 12.
- Poollager: Detta lager sätts in med jämna mellanrum i täcket och dess huvudsakliga funktion är att minska storleken på volymen vilket gör att beräkningen snabbt minskar minnet och även förhindrar överanpassning. Två vanliga typer av poollager är max poolning och genomsnittlig pooling . Om vi använder en maxpool med 2 x 2 filter och steg 2 kommer den resulterande volymen att vara av dimensionen 16x16x12.
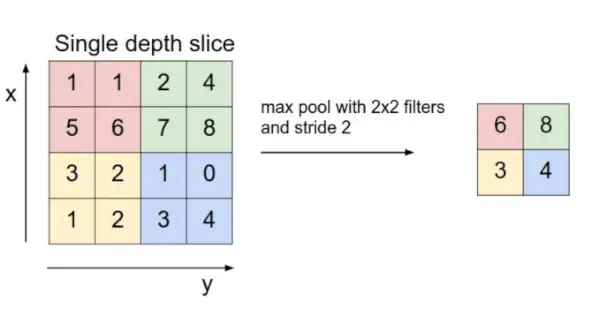
Bildkälla: cs231n.stanford.edu
- Tillplattning: De resulterande särdragskartorna tillplattas till en endimensionell vektor efter faltnings- och poolskikten så att de kan överföras till ett helt länkat lager för kategorisering eller regression.
- Fullt anslutna lager: Den tar indata från föregående lager och beräknar den slutliga klassificeringen eller regressionsuppgiften.
Bildkälla: cs231n.stanford.edu
- Utdatalager: Utdata från de helt anslutna lagren matas sedan in i en logistisk funktion för klassificeringsuppgifter som sigmoid eller softmax som omvandlar utdata från varje klass till sannolikhetspoängen för varje klass.
Exempel:
Låt oss överväga en bild och tillämpa faltningsskiktet, aktiveringsskiktet och poolskiktsoperationen för att extrahera den inre funktionen.
Ingångsbild:
Ingångsbild
Steg:
- importera nödvändiga bibliotek
- ställ in parametern
- definiera kärnan
- Ladda bilden och rita den.
- Formatera om bilden
- Använd faltningslageroperation och rita ut bilden.
- Tillämpa aktiveringslagerdrift och rita ut bilden.
- Använd poollageroperation och rita ut bilden.
Python3
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)> image>=> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
>
java kast undantag
>
Produktion :

Original gråskalebild
Produktion
Fördelar med Convolutional Neural Networks (CNN):
- Bra på att upptäcka mönster och funktioner i bilder, videor och ljudsignaler.
- Robust för translation, rotation och skalinvarians.
- End-to-end utbildning, inget behov av manuell funktionsextraktion.
- Kan hantera stora datamängder och uppnå hög noggrannhet.
Nackdelar med Convolutional Neural Networks (CNN):
- Beräkningsmässigt dyr att träna och kräver mycket minne.
- Kan vara benägna att överanpassa om inte tillräckligt med data eller korrekt reglering används.
- Kräver stora mängder märkt data.
- Tolkbarheten är begränsad, det är svårt att förstå vad nätverket har lärt sig.
Vanliga frågor (FAQs)
1: Vad är ett Convolutional Neural Network (CNN)?
A Convolutional Neural Network (CNN) är en typ av djupinlärningsneurala nätverk som är väl lämpade för bild- och videoanalys. CNN använder en serie faltnings- och poollager för att extrahera funktioner från bilder och videor, och använder sedan dessa funktioner för att klassificera eller upptäcka objekt eller scener.
2: Hur fungerar CNN?
CNN fungerar genom att applicera en serie faltning och poollager på en ingångsbild eller video. Konvolutionslager extraherar funktioner från ingången genom att föra ett litet filter, eller kärna, över bilden eller videon och beräkna punktprodukten mellan filtret och ingången. Poolande lager samplar sedan ned utdata från faltningsskikten för att minska dimensionaliteten hos datan och göra den mer beräkningseffektiv.
3: Vilka är några vanliga aktiveringsfunktioner som används i CNN?
Några vanliga aktiveringsfunktioner som används i CNN inkluderar:
- Rectified Linear Unit (ReLU): ReLU är en icke-mättande aktiveringsfunktion som är beräkningseffektiv och lätt att träna.
- Leaky Rectified Linear Unit (Leaky ReLU): Leaky ReLU är en variant av ReLU som tillåter en liten mängd negativ gradient att flöda genom nätverket. Detta kan hjälpa till att förhindra att nätverket dör under träning.
- Parametrisk likriktad linjär enhet (PReLU): PReLU är en generalisering av Leaky ReLU som gör att lutningen för den negativa gradienten kan läras in.
4: Vad är syftet med att använda flera faltningslager i ett CNN?
Genom att använda flera faltningslager i en CNN kan nätverket lära sig allt mer komplexa funktioner från ingångsbilden eller videon. De första faltningsskikten lär sig enkla funktioner, såsom kanter och hörn. De djupare faltningsskikten lär sig mer komplexa funktioner, såsom former och objekt.
5: Vilka är några vanliga regleringstekniker som används i CNN?
Regulariseringstekniker används för att förhindra CNN från att överanpassa träningsdata. Några vanliga regleringstekniker som används i CNN inkluderar:
- Bortfall: Bortfall tappar slumpmässigt neuroner från nätverket under träning. Detta tvingar nätverket att lära sig mer robusta funktioner som inte är beroende av någon enskild neuron.
- L1-regularisering: L1-regularisering regulariserar det absoluta värdet av vikterna i nätverket. Detta kan bidra till att minska antalet vikter och göra nätverket mer effektivt.
- L2-regularisering: L2-regularisering regulariserar kvadraten på vikterna i nätverket. Detta kan också bidra till att minska antalet vikter och göra nätverket mer effektivt.
6: Vad är skillnaden mellan ett faltningslager och ett poollager?
Ett faltningslager extraherar funktioner från en ingångsbild eller video, medan ett poollager nedsamplar utdata från faltningsskikten. Konvolutionslager använder en serie filter för att extrahera funktioner, medan poollager använder en mängd olika tekniker för att nedsampla data, till exempel maximal pooling och genomsnittlig pooling.