Linux uniq-kommandot används för att ta bort alla upprepade rader från en fil. Den kan också användas för att visa antalet ord, bara upprepade rader, ignorera tecken och jämföra specifika fält. Det är ett av de mest använda kommandona i Linux systemet. Det används ofta med sorteringskommando eftersom den jämför intilliggande tecken. Den kasserar alla identiska rader och skriver utdata.
Syntax:
uniq [OPTION]... [INPUT [OUTPUT]]
Alternativ:
Några användbara kommandoradsalternativ för uniq-kommandot är följande:
-c, --count: det prefixer raderna med antalet förekomster.
-d, --upprepad: den används för att skriva ut dubbletter av rader, en för varje grupp.
-D: Den används för att skriva ut alla dubbletter.
--all-repeated[=METHOD]: Det är ganska likt alternativet '-D', skillnaden mellan båda alternativen är att det tillåter separering av grupper med en tom rad.
-f, --skip-fields=N: Den används för att undvika jämförelse av de första N fälten.
--grupp[=METOD]: Den används för att visa alla objekt och separerar grupperna med en tom rad.
-i, --ignore-case: Det används för att ignorera skillnaderna när man jämför.
-s, --skip-chars=N: Det används för att undvika jämförelse av de första N tecknen.
-u, --unik: den används för att skriva ut unika linjer.
-z, --noll-terminerad: Den används för att linjeavgränsaren är NUL och inte nylinjeläge.
teckenstorlekar i latex
-w, --check-chars=N: Den används för att jämföra högst N tecken på rader.
--hjälp: Den används för att visa hjälpdokumentation.
--version: Den används för att visa versionsinformationen.
Exempel på uniq Command
Låt oss se följande exempel på kommandot uniq:
- Ta bort upprepade rader
- räkna antalet förekomster av ett ord
- Visa de upprepade raderna
- Visa de unika linjerna
- Ignorera tecken i jämförelse
- Ignorera fält i jämförelse
Ta bort upprepade rader
För att ta bort upprepade rader från en fil, kör det grundläggande uniq-kommandot enligt följande:
sort dupli.txt | uniq
Ovanstående kommando tar bort dubblettraderna från filen 'dupli.txt'. Tänk på följande utdata:
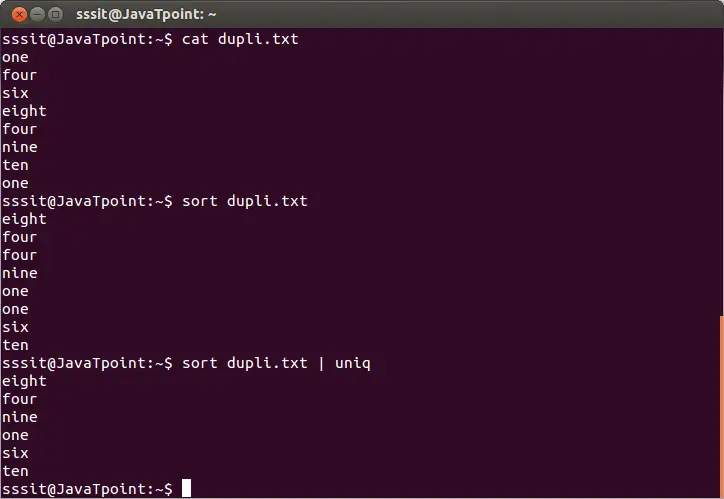
Från ovanstående utdata ignoreras de upprepade orden.
Räkna antalet förekomster av ett ord
Vi kan räkna antalet förekomster av ett ord genom att använda kommandot uniq. Alternativet '-c' används för att räkna ordet. Kör det enligt följande:
.tif-fil
sort dupli.txt | uniq -c
Ovanstående kommando kommer att räkna orden som kommer i 'dupli.txt'. Tänk på följande utdata:

Från ovanstående utdata, kommandot 'sort dupli.txt | uniq -c' räknar antalet gånger ett ord upprepas.
Visa de upprepade raderna
Alternativet '-d' används för att endast visa de upprepade raderna. Det kommer bara att visa raderna som kommer att vara mer än en gång i en fil och skriva utdata till standardutdata. Tänk på kommandot nedan:
sort dupli.txt | uniq -d
Ovanstående kommando visar endast de upprepade raderna. Tänk på följande utdata:

Visa de unika linjerna
Alternativet '-u' används för att endast visa de unika raderna (som inte upprepas). Den visar bara de rader som bara förekommer en gång och skriver resultatet till standardutdata. Tänk på kommandot nedan:
sort dupli.txt | uniq -u
Ovanstående kommando visar endast de unika raderna från filen 'dupli.txt'. Tänk på följande utdata:

Ignorera tecken i jämförelse
Alternativet '-s' används för att ignorera tecknen i jämförelse. Den ignorerar det angivna antalet tecken och visar resultatet till standardutdata. Tänk på kommandot nedan:
sort dupli.txt | uniq -s 2
Ovanstående kommando kommer att ignorera de två första tecknen i jämförelse från filen 'dupli.txt'. Tänk på följande utdata:

Ignorera fält i jämförelse
Alternativet '-f' används för att ignorera fälten. Tänk på kommandot nedan:
uniq -f 2 dupli2.txt
Ovanstående kommando kommer inte att jämföra de två första fälten från filen 'dupli2.txt'. Tänk på följande utdata:

Från ovanstående utdata hoppas de första två fälten över, och resten av alla fält jämförs från filen 'dupli2.txt'.