- dnorm()
dnorm(x, mean, sd)>pnorm()
pnorm(x, mean, sd)>qnorm()
qnorm(p, mean, sd)>rnorm()
rnorm(n, mean, sd)>var,
– x representerar datamängden med värden – medelvärde(x) representerar medelvärdet av datamängden x . Dess standardvärde är 0.>– sd(x) representerar standardavvikelsen för datamängden x . Dess standardvärde är 1.>– n är antalet observationer. – sid är en vektor för sannolikheter
Funktioner för att generera normalfördelning i R
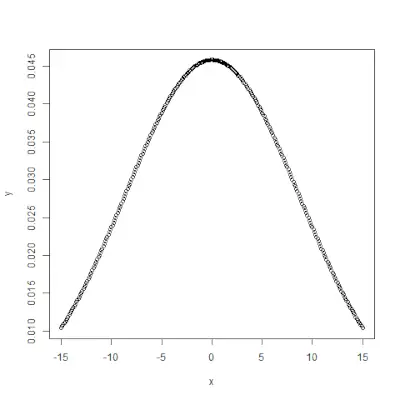
dnorm()
dnorm()> funktion i R programmering mäter densitet funktion av distribution. I statistiken mäts det med nedanstående formel->var,
 är elak och
är elak och 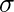 är standardavvikelse. Syntax :
är standardavvikelse. Syntax : dnorm(x, mean, sd)>Exempel:
# creating a sequence of values> # between -15 to 15 with a difference of 0.1> x>=> seq(>->15>,>15>, by>=>0.1>)> > y>=> dnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file>=>'dnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Produktion:
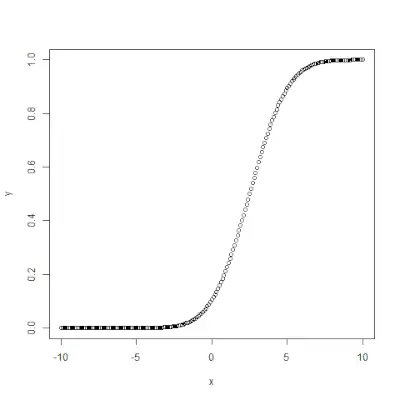
pnorm()
pnorm()> funktion är den kumulativa fördelningsfunktionen som mäter sannolikheten att ett slumptal X tar ett värde mindre än eller lika med x, dvs. i statistik ges det av->Syntax:
pnorm(x, mean, sd)>Exempel:
# creating a sequence of values> # between -10 to 10 with a difference of 0.1> x <>-> seq(>->10>,>10>, by>=>0.1>)> > y <>-> pnorm(x, mean>=> 2.5>, sd>=> 2>)> > # output to be present as PNG file> png(>file>=>'pnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Utgång:
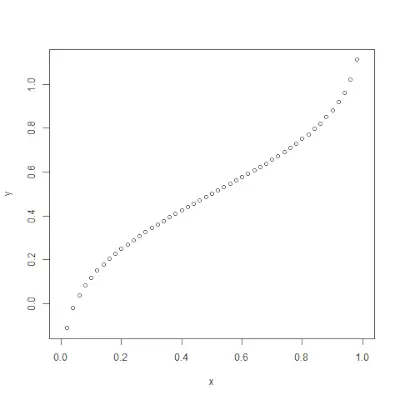
qnorm()
qnorm()> funktion är motsatsen till pnorm()>fungera. Den tar sannolikhetsvärdet och ger utdata som motsvarar sannolikhetsvärdet. Det är användbart för att hitta percentilerna för en normalfördelning. Syntax: qnorm(p, mean, sd)>Exempel:
# Create a sequence of probability values> # incrementing by 0.02.> x <>-> seq(>0>,>1>, by>=> 0.02>)> > y <>-> qnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file> => 'qnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # Save the file.> dev.off()> |
>
>Produktion:
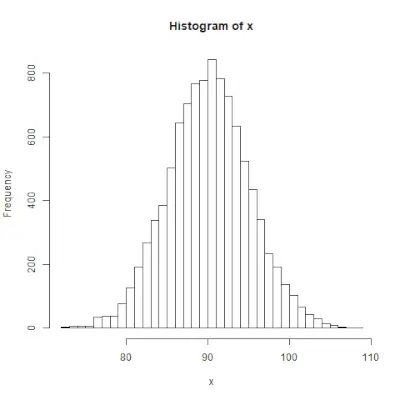
rnorm()
rnorm()> funktion i R-programmering används för att generera en vektor av slumptal som är normalfördelade. Syntax: rnorm(x, mean, sd)>Exempel:
# Create a vector of 1000 random numbers> # with mean=90 and sd=5> x <>-> rnorm(>10000>, mean>=>90>, sd>=>5>)> > # output to be present as PNG file> png(>file> => 'rnormExample.webp'>)> > # Create the histogram with 50 bars> hist(x, breaks>=>50>)> > # Save the file.> dev.off()> |
>
>Utgång: