Pandas dataframe.corr() används för att hitta den parvisa korrelationen för alla kolumner i Pandas Dataframe i Python. Några NaN värden exkluderas automatiskt. För att ignorera eventuella icke-numeriska värden, använd parametern numeric_only = True. I den här artikeln kommer vi att lära oss om metoden DataFrame.corr() i Pytonorm .
Pandas DataFrame corr() Metodsyntax
Syntax: DataFrame.corr(self, method='pearson', min_periods=1, numeric_only = False)
Parametrar:
- metod:
- pearson: standardkorrelationskoefficient
- kendall: Kendall Tau korrelationskoefficient
- spearman: Spearman rank korrelation
- min_perioder : Minsta antal observationer som krävs per kolumnpar för att få ett giltigt resultat. För närvarande endast tillgänglig för pearson och spearman korrelation
- numeric_only : Om endast de numeriska värdena ska användas eller inte. Den är inställd på False som standard.
Returnerar: count :y : DataFrame
Pandas Data Correlations corr() Metod
En bra korrelation beror på användningen, men det är säkert att säga att du har minst 0,6 (eller -0,6) för att kalla det en bra korrelation. Ett enkelt exempel för att visa hur korrelation fungerar i Pytonorm .
Python3
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
>
>
förbeställ genomgång
Produktion
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
Skapa exempeldataram
Skriver ut de första 10 raderna i Dataframe.
Notera: Korrelationen för en variabel med sig själv är 1. För en länk till CSV-filen som används i kod, klicka här
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
>
Produktion

Python Pandas DataFrame corr() Metodexempel
Hitta korrelation bland kolumnerna med hjälp av pearson-metoden
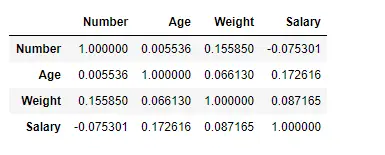
Här använder vi funktionen corr() för att hitta korrelationen mellan kolumnerna i dataramen med hjälp av 'Pearson'-metoden. Vi har bara fyra numeriska kolumner i dataramen. Utdatadataramen kan tolkas som för vilken cell som helst, radvariabelkorrelation med kolumnvariabeln är cellens värde. Som tidigare nämnts är korrelationen för en variabel med sig själv 1. Av den anledningen är alla diagonalvärden 1,00.
Python3
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
>
Produktion
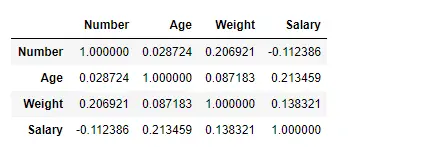
Hitta korrelation bland kolumnerna med hjälp av Kendall-metoden
Använd Pandas df.corr()-funktion för att hitta korrelationen mellan kolumnerna i Dataframe med hjälp av 'kendall'-metoden. Utdatadataramen kan tolkas som för vilken cell som helst, radvariabelkorrelation med kolumnvariabeln är cellens värde. Som tidigare nämnts är korrelationen för en variabel med sig själv 1. Av den anledningen är alla diagonalvärden 1,00.
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
>
>
Produktion