Python är ett bra språk för att göra dataanalys, främst på grund av det fantastiska ekosystemet av datacentrerad Pytonorm paket. Pandas är ett av dessa paket och gör import och analys av data mycket enklare.
Pandas DataFrame mean()
Pandas dataframe.mean() funktion returnerar medelvärdet av värdena för den begärda axeln. Om metoden tillämpas på ett pandasserieobjekt returnerar metoden ett skalärt värde som är medelvärdet av alla observationer i Pandas dataram . Om metoden tillämpas på ett Pandas Dataframe-objekt returnerar metoden en Panda-serien objekt som innehåller medelvärdet av värdena över den angivna axeln.
Syntax: DataFrame.mean(axis=0, skipna=True, level=None, numeric_only=False, **kwargs)
Parametrar:
- axel: {index (0), kolumner (1)}
- beställa : Exkludera NA/null-värden när du beräknar resultatet
- nivå: Om axeln är ett MultiIndex (hierarkiskt), räkna längs en viss nivå och kollapsa till en serie
- numeric_only : Inkludera endast float, int, booleska kolumner. Om Ingen, kommer att försöka använda allt, använd endast numerisk data. Inte implementerat för serier.
Returnerar: medelvärde: Series eller DataFrame (om nivå anges)
fackförbund vs fackförbund alla
Pandas DataFrame.mean() Exempel
Exempel 1:
Använd funktionen mean() för att hitta medelvärdet av alla observationer över indexaxeln.
Pytonorm # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, 44, 1], 'B':[5, 2, 54, 3, 2], 'C':[20, 16, 7, 3, 8], 'D':[14, 3, 17, 2, 6]}) # Print the dataframe df> 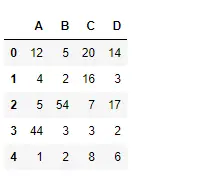
Låt oss använda funktionen Dataframe.mean() för att hitta medelvärdet över indexaxeln.
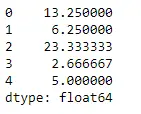
Pytonorm # Even if we do not specify axis = 0, # the method will return the mean over # the index axis by default df.mean(axis = 0)>
Produktion:
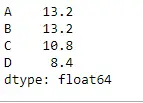
Exempel 2:
Använd mean()-funktionen på en dataram som har None-värden. Hitta också medelvärdet över kolumnaxeln.
Pytonorm # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, None, 1], 'B':[7, 2, 54, 3, None], 'C':[20, 16, 11, 3, 8], 'D':[14, 3, None, 2, 6]}) # skip the Na values while finding the mean df.mean(axis = 1, skipna = True)> Produktion: