Oinformerad sökning är en klass av generella sökalgoritmer som fungerar på ett brute force-sätt. Oinformerade sökalgoritmer har ingen ytterligare information om tillstånd eller sökutrymme annat än hur man korsar trädet, så det kallas även blindsökning.
Följande är de olika typerna av oinformerade sökalgoritmer:
1. Bredd-först sökning:
- Bredd-först-sökning är den vanligaste sökstrategin för att korsa ett träd eller en graf. Den här algoritmen söker på bredden i ett träd eller en graf, så det kallas breddförst-sökning.
- BFS-algoritmen börjar söka från trädets rotnod och expanderar alla efterföljande noder på den aktuella nivån innan den går till noder på nästa nivå.
- Bredd-först sökalgoritmen är ett exempel på en generell grafisk sökalgoritm.
- Bredd-första sökning implementerad med hjälp av FIFO-ködatastruktur.
Fördelar:
- BFS kommer att tillhandahålla en lösning om någon lösning finns.
- Om det finns mer än en lösning för ett givet problem, kommer BFS att tillhandahålla den minimala lösningen som kräver minst antal steg.
Nackdelar:
- Det kräver mycket minne eftersom varje nivå i trädet måste sparas i minnet för att utöka nästa nivå.
- BFS behöver mycket tid om lösningen är långt borta från rotnoden.
Exempel:
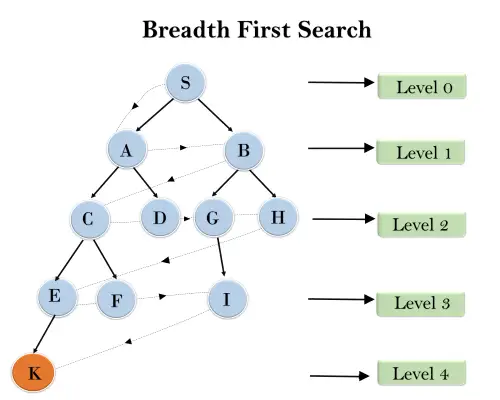
I trädstrukturen nedan har vi visat korsningen av trädet med hjälp av BFS-algoritmen från rotnoden S till målnoden K. BFS-sökalgoritmen korsar i lager, så den kommer att följa vägen som visas av den prickade pilen, och korsad väg kommer att vara:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
Tidskomplexitet: Tidskomplexiteten för BFS-algoritmen kan erhållas genom antalet noder som korsas i BFS fram till den grundaste noden. Där d = djupet för grundaste lösningen och b är en nod i varje tillstånd.
T(b) = 1+b2+b3+......+ bd= O (bd)
Utrymmes komplexitet: Rymdkomplexiteten för BFS-algoritmen ges av minnesstorleken på gränsen som är O(bd).
Fullständighet: BFS är klar, vilket innebär att om den grundaste målnoden är på något ändligt djup, så kommer BFS att hitta en lösning.
Optimalitet: BFS är optimal om vägkostnaden är en icke-minskande funktion av nodens djup.
2. Djup-första sökning
- Djup-först-sökning är en rekursiv algoritm för att korsa ett träd eller en grafdatastruktur.
- Den kallas djup-först-sökningen eftersom den börjar från rotnoden och följer varje väg till dess största djupnod innan den går till nästa väg.
- DFS använder en stackdatastruktur för dess implementering.
- Processen för DFS-algoritmen liknar BFS-algoritmen.
Obs: Backtracking är en algoritmteknik för att hitta alla möjliga lösningar med hjälp av rekursion.
Fördel:
- DFS kräver mycket mindre minne eftersom det bara behöver lagra en stack av noderna på vägen från rotnoden till den aktuella noden.
- Det tar mindre tid att nå målnoden än BFS-algoritmen (om den går på rätt väg).
Nackdel:
- Det finns möjlighet att många stater fortsätter att upprepas, och det finns ingen garanti för att hitta lösningen.
- DFS-algoritmen går till djupgående sökning och någon gång kan den gå till den oändliga slingan.
Exempel:
I sökträdet nedan har vi visat flödet av djup-först-sökning, och det kommer att följa ordningen som:
Rotnod ---> Vänster nod ----> höger nod.
Den kommer att börja söka från rotnod S, och korsa A, sedan B, sedan D och E, efter att ha korsat E, kommer den att backa trädet eftersom E inte har någon annan efterföljare och målnoden fortfarande inte hittas. Efter backtracking kommer den att korsa nod C och sedan G, och här kommer den att avslutas när den hittade målnoden.

Fullständighet: DFS-sökalgoritmen är komplett inom ändligt tillståndsutrymme eftersom den kommer att expandera varje nod inom ett begränsat sökträd.
Tidskomplexitet: Tidskomplexiteten för DFS kommer att vara ekvivalent med den nod som algoritmen passerar. Det ges av:
T(n)= 1+ n2+ n3+.........+ nm=O(nm)
Där m= maximalt djup för någon nod och detta kan vara mycket större än d (Grunnaste lösningsdjupet)
alfa beta beskärning
Utrymmes komplexitet: DFS-algoritmen behöver endast lagra en enkel väg från rotnoden, därför är rymdkomplexiteten för DFS ekvivalent med storleken på fransuppsättningen, vilket är O(bm) .
Optimal: DFS-sökalgoritmen är icke-optimal, eftersom den kan generera ett stort antal steg eller höga kostnader för att nå målnoden.
3. Djupbegränsad sökalgoritm:
En djupbegränsad sökalgoritm liknar djup-först-sökning med en förutbestämd gräns. Djupbegränsad sökning kan lösa nackdelen med den oändliga vägen i Djupet-först-sökningen. I denna algoritm kommer noden vid djupgränsen att behandla eftersom den inte har några efterföljande noder ytterligare.
Djupbegränsad sökning kan avslutas med två villkor för misslyckande:
- Standardfelvärde: Det indikerar att problemet inte har någon lösning.
- Cutoff-felvärde: Det definierar ingen lösning för problemet inom en given djupgräns.
Fördelar:
Djupbegränsad sökning är minneseffektiv.
Nackdelar:
- Djupbegränsad sökning har också en nackdel av ofullständighet.
- Det kanske inte är optimalt om problemet har mer än en lösning.
Exempel:

Fullständighet: DLS-sökalgoritmen är klar om lösningen ligger över djupgränsen.
Tidskomplexitet: Tidskomplexiteten hos DLS-algoritmen är O(bℓ) .
Utrymmes komplexitet: Rymdkomplexiteten för DLS-algoritmen är O (b�ℓ) .
Optimal: Djupbegränsad sökning kan ses som ett specialfall av DFS, och det är inte heller optimalt även om ℓ>d.
4. Sökalgoritm för enhetlig kostnad:
Uniform-cost search är en sökalgoritm som används för att korsa ett viktat träd eller en graf. Denna algoritm kommer in när en annan kostnad är tillgänglig för varje kant. Det primära målet med enhetlig kostnadssökning är att hitta en väg till målnoden som har den lägsta kumulativa kostnaden. Uniform-cost search expanderar noder enligt deras vägkostnader från rotnoden. Den kan användas för att lösa vilken graf/träd som helst där den optimala kostnaden efterfrågas. En sökalgoritm för enhetlig kostnad implementeras av prioritetskön. Det ger maximal prioritet till lägsta kumulativa kostnad. Enhetlig kostnadssökning motsvarar BFS-algoritmen om vägkostnaden för alla kanter är densamma.
Fördelar:
- Enhetlig kostnadssökning är optimal eftersom vägen med lägst kostnad väljs i varje stat.
Nackdelar:
- Den bryr sig inte om antalet steg i att söka och bekymrar sig bara om vägkostnaden. På grund av vilket denna algoritm kan ha fastnat i en oändlig loop.
Exempel:

Fullständighet:
En enhetlig kostnadssökning är klar, till exempel om det finns en lösning kommer UCS att hitta den.
Tidskomplexitet:
Låt C* är Kostnaden för den optimala lösningen , och e är varje steg för att komma närmare målnoden. Då är antalet steg = C*/ε+1. Här har vi tagit +1, då vi börjar från tillstånd 0 och slutar till C*/ε.
Därför är det värsta tänkbara tidskomplexiteten för enhetlig kostnadssökning O(b1 + [C*/e])/ .
Utrymmes komplexitet:
Samma logik är för rymdkomplexitet, så det värsta tänkbara rymdkomplexiteten för sökning med enhetlig kostnad är O(b1 + [C*/e]) .
Optimal:
En enhetlig kostnadssökning är alltid optimal eftersom den bara väljer en väg med den lägsta vägkostnaden.
5. Iterativ fördjupning, djup-först sökning:
Den iterativa fördjupningsalgoritmen är en kombination av DFS- och BFS-algoritmer. Denna sökalgoritm tar reda på den bästa djupgränsen och gör det genom att gradvis öka gränsen tills ett mål hittas.
Denna algoritm utför djup-först-sökning upp till en viss 'djupgräns', och den fortsätter att öka djupgränsen efter varje iteration tills målnoden hittas.
Denna sökalgoritm kombinerar fördelarna med Breadth-first-sökningens snabba sökning och djup-först-sökningens minneseffektivitet.
Den iterativa sökalgoritmen är användbar oinformerad sökning när sökutrymmet är stort och djupet på målnoden är okänt.
Fördelar:
- Den kombinerar fördelarna med BFS- och DFS-sökalgoritmer när det gäller snabb sökning och minneseffektivitet.
Nackdelar:
- Den största nackdelen med IDDFS är att det upprepar allt arbete från föregående fas.
Exempel:
Följande trädstruktur visar den iterativa djupsökningen först. IDDFS-algoritmen utför olika iterationer tills den inte hittar målnoden. Iterationen som utförs av algoritmen ges som:

1:a upprepningen-----> A
2:a iterationen----> A, B, C
3:e iterationen------>A, B, D, E, C, F, G
4:e iterationen ------>A, B, D, H, I, E, C, F, K, G
I den fjärde iterationen kommer algoritmen att hitta målnoden.
Fullständighet:
Denna algoritm är komplett om förgreningsfaktorn är finit.
Tidskomplexitet:
Låt oss anta att b är förgreningsfaktorn och djupet är d, då är tidskomplexiteten i värsta fall O(bd) .
Utrymmes komplexitet:
Rymdkomplexiteten hos IDDFS kommer att vara O(bd) .
Optimal:
IDDFS-algoritmen är optimal om vägkostnaden är en icke-minskande funktion av nodens djup.
6. Dubbelriktad sökalgoritm:
Dubbelriktad sökalgoritm kör två samtidiga sökningar, en form av initialtillstånd som kallas framåtsökning och en annan från målnod som kallas bakåtsökning, för att hitta målnoden. Dubbelriktad sökning ersätter en enda sökgraf med två små subgrafer där den ena startar sökningen från en första hörn och den andra börjar från målpunkten. Sökningen avbryts när dessa två grafer skär varandra.
Dubbelriktad sökning kan använda söktekniker som BFS, DFS, DLS, etc.
Fördelar:
- Dubbelriktad sökning går snabbt.
- Dubbelriktad sökning kräver mindre minne
Nackdelar:
- Implementeringen av det dubbelriktade sökträdet är svårt.
Exempel:
I sökträdet nedan används dubbelriktad sökalgoritm. Denna algoritm delar upp en graf/träd i två undergrafer. Den börjar passera från nod 1 i riktning framåt och börjar från målnod 16 i riktning bakåt.
Algoritmen slutar vid nod 9 där två sökningar möts.

Fullständighet: Dubbelriktad sökning är klar om vi använder BFS i båda sökningarna.
Tidskomplexitet: Tidskomplexiteten för dubbelriktad sökning med BFS är O(bd) .
Utrymmes komplexitet: Utrymmet komplexitet dubbelriktad sökning är O(bd) .
Optimal: Dubbelriktad sökning är optimal.