Ett databasschema är en struktur som representerar den logiska lagringen av data i en databas . Den representerar organisationen av data och ger information om relationerna mellan tabellerna i en given databas. I det här ämnet kommer vi att förstå mer om databasschema och dess typer. Innan vi förstår databasschemat, låt oss först förstå vad en databas är.
Vad är databas?
A databas är en plats för att lagra information. Den kan lagra de enklaste data, såsom en lista över personer såväl som de mest komplexa data. Databasen lagrar informationen i ett välstrukturerat format.
Vad är Databas Schema?
- Ett databasschema är den logiska representationen av en databas, som visar hur data lagras logiskt i hela databasen. Den innehåller en lista med attribut och instruktioner som informerar databasmotorn om hur data är organiserad och hur elementen är relaterade till varandra.
- Ett databasschema innehåller schemaobjekt som kan inkludera tabeller, fält, paket, vyer, relationer, primärnyckel, främmande nyckel,
- I själva verket lagras uppgifterna fysiskt i filer som kan vara i ostrukturerad form, men för att hämta den och använda den måste vi lägga den i en strukturerad form. För att göra detta används ett databasschema. Den ger kunskap om hur uppgifterna är organiserade i en databas och hur de associeras med annan data.
- Ett databasschemaobjekt inkluderar följande:
- Konsekvent formatering för alla datainmatningar.
- Databasobjekt och unika nycklar för alla datainmatningar.
- Tabeller med flera kolumner och varje kolumn innehåller dess namn och datatyp.
- Komplexiteten och storleken på schemat varierar beroende på projektets storlek. Det hjälper utvecklare att enkelt hantera och strukturera databasen innan den kodas.
- Det givna diagrammet är ett exempel på ett databasschema. Den innehåller tre tabeller, deras datatyper. Detta representerar också relationerna mellan tabellerna och primärnycklarna samt främmande nycklar.
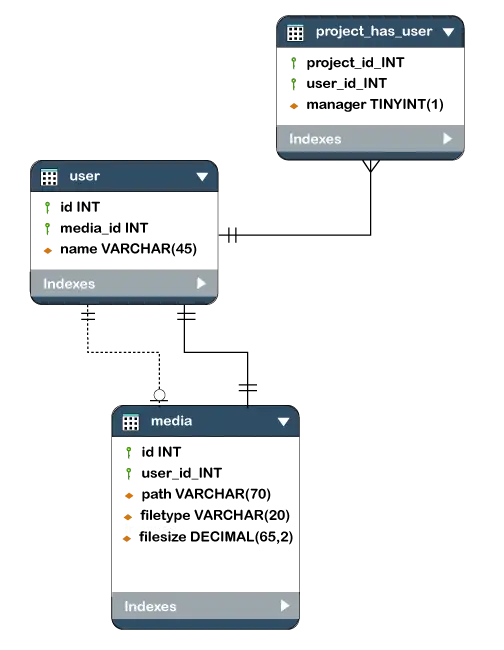
Typer av databasschema
Databasschemat är uppdelat i tre typer, som är:

1. Fysiskt databasschema
Ett fysiskt databasschema anger hur data lagras fysiskt på ett lagringssystem eller disklagring i form av filer och index. Att designa en databas på fysisk nivå kallas a fysiskt schema .
2. Logiskt databasschema
Det logiska databasschemat specificerar alla logiska begränsningar som måste tillämpas på lagrad data. Den definierar vyerna, integritetsbegränsningarna och tabellen. Här termen Integritetsbegränsningar definiera uppsättningen regler som används av DBMS (Databas Management System) för att upprätthålla kvaliteten för infogning och uppdatering av data. Det logiska schemat representerar hur data lagras i form av tabeller och hur en tabells attribut är sammanlänkade.
På denna nivå arbetar programmerare och administratörer och implementeringen av datastrukturen är dold på denna nivå.
Olika verktyg används för att skapa ett logiskt databasschema, och dessa verktyg visar relationerna mellan komponenten i din data; denna process kallas IS-modellering .
ER-modelleringen står för entity-relationship modeling, som specificerar relationerna mellan olika enheter.
Vi kan förstå det med ett exempel på en grundläggande handelsapplikation. Nedan visas schemat, den enkla ER-modellen som representerar det logiska transaktionsflödet i en handelsapplikation.

I det givna exemplet anges Id i varje cirkel, och dessa Id är primärnyckel & främmande nycklar.
De primärnyckeln är används för att unikt identifiera posten i ett dokument eller en post. Id för de tre övre cirklarna är de primära nycklarna.
De Främmande nyckel används som primärnyckel för andra tabeller. FK representerar den främmande nyckeln i diagrammet. Det relaterar ett bord till ett annat bord.
3. Visa schema
Vynivådesignen för en databas är känd som visa schema . Detta schema beskriver generellt slutanvändarens interaktion med databassystemen.
Skillnaden mellan det fysiska och det logiska databasschemat
| Fysiskt databasschema | Logiskt databasschema |
|---|---|
| Det inkluderar inte attributen. | Det inkluderar attributen. |
| Den innehåller både primära och sekundära nycklar. | Den innehåller också både primära och sekundära nycklar. |
| Den innehåller tabellnamnet. | Den innehåller namnen på tabellerna. |
| Den innehåller kolumnnamnen och deras datatyper. | Den innehåller inget kolumnnamn eller datatyp. |
Databasinstans eller databasschema är samma?
Termerna databasschema och databasinstanser är relaterade till varandra och ibland förvirrande att användas som samma sak. Men båda skiljer sig från varandra.
Databasschema är en representation av en planerad databas och innehåller faktiskt inte data.
Å andra sidan, a databasinstans är en typ av ögonblicksbild av en faktisk databas som den existerade vid ett tillfälle. Därför varierar det eller kan ändras per tid. Däremot är databasschemat statiskt och mycket komplicerat att ändra strukturen i en databas.
vad är skillnaden mellan en megabyte och en gigabyte
Både instanser och scheman är relaterade till och påverkar varandra genom DBMS. DBMS säkerställer att varje databasinstans överensstämmer med de begränsningar som ställs av databasdesignerna i databasschemat.
Skapar schema
För att skapa ett schema används 'CREATE SCHEMA'-satser i varje typ av databas. Men varje DBMS har en annan betydelse för detta. Nedan förklarar vi att skapa scheman i olika databassystem:
1. MySQL
I MySQL , den ' SKAPA SCHEMA ' uttalande skapar databasen. Det beror på att CREATE SCHEMA-satsen i MySQL liknar CREATE DATABASE-satsen och schema är en synonym för databasen.
2. Oracle Database
I Oracle Database finns varje schema redan med varje databasanvändare. Därför skapar CREATE SCHEMA faktiskt inte ett schema; snarare hjälper det att visa schemat med tabeller och vyer och gör det möjligt att komma åt dessa objekt utan att kräva flera SQL-satser för flera transaktioner. 'CREATE USER'-satsen används för att skapa ett schema i Oracle.
3. SQL Server
I den SQL servern skapar 'CREATE SCHEMA'-satsen ett nytt schema med det namn som användaren angett.
Databasschemadesign
En schemadesign är det första steget i att bygga en grund inom datahantering. Ineffektiva schemadesigner är svåra att hantera och förbrukar mer minne och andra resurser. Det beror logiskt på affärskraven. Det krävs att du väljer rätt databasschemadesign för att underlätta projektets livscykel. Listan över några populära databasschemadesigner ges nedan:
Platt modell
Ett platt modellschema är en typ av 2D-array där varje kolumn innehåller samma typ av data och element i en rad är relaterade till varandra. Det kan förstås som ett enda kalkylblad eller en databastabell utan relationer. Denna schemadesign är mest lämplig för små applikationer som inte innehåller komplexa data.
Hierarkisk modell
Den hierarkiska modelldesignen innehåller en trädliknande struktur. Trädstrukturen innehåller rotnoden för data och dess undernoder. Mellan varje underordnad nod och överordnad nod finns en en-till-många-relation. Sådana typer av databasscheman presenteras av XML- eller JSON-filer, eftersom dessa filer kan innehålla entiteterna med deras underenheter.
java sträng trim
De hierarkiska schemamodellerna är bäst lämpade för att lagra kapslade data, till exempel representation Hominoid klassificering.
Nätverksmodell
Nätverksmodelldesignen liknar hierarkisk design eftersom den representerar en serie noder och hörn. Den största skillnaden mellan nätverksmodellen och den hierarkiska modellen är att nätverksmodellen tillåter ett många-till-många-förhållande. Däremot tillåter den hierarkiska modellen bara en en-till-många-relation.
Nätverksmodellens design är bäst lämpad för applikationer som kräver rumsliga beräkningar. Det är också bra för att representera arbetsflöden och främst för ärenden med flera vägar till samma resultat.
Relationsmodell
Relationsmodellerna används för relationsdatabasen, som lagrar data som tabellens relationer. Det finns relationsoperatorer som används för att arbeta på data för att manipulera och beräkna olika värden från den.
Stjärnschema
Stjärnschemat är ett annat sätt för schemadesign för att organisera data. Den är bäst lämpad för att lagra och analysera en enorm mängd data, och den fungerar på 'Fakta' och 'Dimensioner'. Här faktumet är den numeriska datapunkten som driver affärsprocesser, och Dimensionera är en faktabeskrivning. Med Star Schema kan vi strukturera data för RDBMS .
Snowflake Schema
Snöflingeschemat är en anpassning av ett stjärnschema. Det finns en huvud 'Fakta'-tabell i stjärnschemat som innehåller de viktigaste datapunkterna och referenser till dess dimensionstabeller. Men i snöflinga kan dimensionstabeller ha sina egna dimensionstabeller.