- Avståndsvektoralgoritmen är en dynamisk algoritm.
- Det används främst i ARPANET och RIP.
- Varje router har en avståndstabell som kallas Vektor .
Tre nycklar för att förstå hur Distance Vector Routing Algorithm fungerar:
Avstånd vektor Routing Algoritm
Låt dx(y) vara kostnaden för den lägsta kostnadsvägen från nod x till nod y. De lägsta kostnaderna är relaterade av Bellman-Fords ekvation,
d<sub>x</sub>(y) = min<sub>v</sub>{c(x,v) + d<sub>v</sub>(y)} Var minv är ekvationen för alla x grannar. Efter att ha färdats från x till v, om vi tar hänsyn till den billigaste vägen från v till y, blir vägkostnaden c(x,v)+di(y). Den lägsta kostnaden från x till y är minimum av c(x,v)+di(y) tagit över alla grannar.
Med Distance Vector Routing-algoritmen innehåller noden x följande routinginformation:
- För varje granne v är kostnaden c(x,v) vägkostnaden från x till direkt ansluten granne, v.
- Avståndsvektorn x, dvs Dx= [Dx(y) : y i N ], med dess kostnad för alla destinationer, y, i N.
- Avståndsvektorn för var och en av dess grannar, dvs Di= [Di(y): y i N] för varje granne v till x.
Avståndsvektorrouting är en asynkron algoritm där nod x skickar kopian av sin avståndsvektor till alla sina grannar. När nod x tar emot den nya avståndsvektorn från en av dess närliggande vektorer, v, sparar den avståndsvektorn för v och använder Bellman-Fords ekvation för att uppdatera sin egen avståndsvektor. Ekvationen ges nedan:
hur man byter namn på en katalog linux
d<sub>x</sub>(y) = min<sub>v</sub>{ c(x,v) + d<sub>v</sub>(y)} for each node y in N Noden x har uppdaterat sin egen avståndsvektortabell genom att använda ovanstående ekvation och skickar sin uppdaterade tabell till alla sina grannar så att de kan uppdatera sina egna avståndsvektorer.
Algoritm
At each node x, <p> <strong>Initialization</strong> </p> for all destinations y in N: D<sub>x</sub>(y) = c(x,y) // If y is not a neighbor then c(x,y) = ∞ for each neighbor w D<sub>w</sub>(y) = ? for all destination y in N. for each neighbor w send distance vector D<sub>x</sub> = [ D<sub>x</sub>(y) : y in N ] to w <strong>loop</strong> <strong>wait</strong> (until I receive any distance vector from some neighbor w) for each y in N: D<sub>x</sub>(y) = minv{c(x,v)+D<sub>v</sub>(y)} If D<sub>x</sub>(y) is changed for any destination y Send distance vector D<sub>x</sub> = [ D<sub>x</sub>(y) : y in N ] to all neighbors <strong>forever</strong> Obs: I Distance vector algorithm uppdaterar nod x sin tabell när den antingen ser någon kostnadsförändring i en direkt länkad nod eller tar emot någon vektoruppdatering från någon granne.
Låt oss förstå genom ett exempel:
Dela information
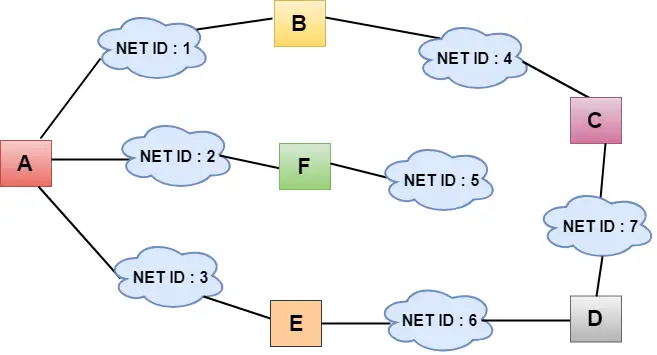
- I figuren ovan representerar varje moln nätverket och numret inuti molnet representerar nätverks-ID.
- Alla LAN är anslutna av routrar, och de är representerade i rutor märkta som A, B, C, D, E, F.
- Algoritmen för distansvektordirigering förenklar routingprocessen genom att anta att kostnaden för varje länk är en enhet. Därför kan effektiviteten av överföringen mätas genom antalet länkar för att nå destinationen.
- I Distance vector routing baseras kostnaden på hoppräkning.

I figuren ovan ser vi att routern skickar kunskapen till de närmaste grannarna. Grannarna lägger till denna kunskap till sin egen kunskap och skickar den uppdaterade tabellen till sina egna grannar. På så sätt får routrar sin egen information plus den nya informationen om grannarna.
Rutttabell
Två processer inträffar:
- Skapa tabellen
- Uppdaterar tabellen
Skapa tabellen
Inledningsvis skapas routingtabellen för varje router som innehåller minst tre typer av information som nätverks-ID, kostnaden och nästa hopp.


- I figuren ovan visas de ursprungliga routningstabellerna för alla routrar. I en routingtabell representerar den första kolumnen nätverks-ID, den andra kolumnen representerar kostnaden för länken och den tredje kolumnen är tom.
- Dessa rutttabeller skickas till alla grannar.
Till exempel:
A sends its routing table to B, F & E. B sends its routing table to A & C. C sends its routing table to B & D. D sends its routing table to E & C. E sends its routing table to A & D. F sends its routing table to A.
Uppdaterar tabellen
- När A tar emot en routingtabell från B, använder den sin information för att uppdatera tabellen.
- Routingtabellen för B visar hur paketen kan flyttas till nätverken 1 och 4.
- B:et är granne med A-routern, paketen från A till B kan nås i ett hopp. Så 1 läggs till alla kostnader som anges i B:s tabell och summan blir kostnaden för att nå ett visst nätverk.

- Efter justering kombinerar A sedan denna tabell med en egen tabell för att skapa en kombinerad tabell.

- Den kombinerade tabellen kan innehålla en del dubbletter av data. I figuren ovan innehåller den kombinerade tabellen för router A dubblettdata, så den behåller endast de data som har den lägsta kostnaden. Till exempel kan A skicka data till nätverk 1 på två sätt. Den första, som inte använder någon nästa router, så den kostar ett hopp. Den andra kräver två hopp (A till B, sedan B till nätverk 1). Det första alternativet har den lägsta kostnaden, därför behålls det och det andra tas bort.

- Processen att skapa routingtabellen fortsätter för alla routrar. Varje router tar emot informationen från grannarna och uppdaterar routingtabellen.
Slutliga routningstabeller för alla routrar ges nedan:
