Följande arkitektur förklarar flödet av inlämning av en fråga till Hive.
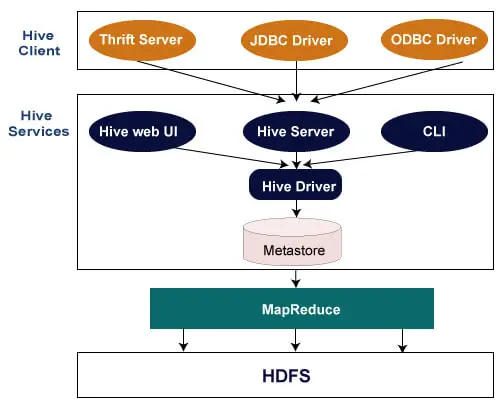
Hive klient
Hive tillåter att skriva applikationer på olika språk, inklusive Java, Python och C++. Det stöder olika typer av klienter som: -
- Thrift Server - Det är en tvärspråkig tjänsteleverantörsplattform som betjänar begäran från alla de programmeringsspråk som stöder Thrift.
- JDBC-drivrutin - Den används för att upprätta en anslutning mellan hive och Java-applikationer. JDBC-drivrutinen finns i klassen org.apache.hadoop.hive.jdbc.HiveDriver.
- ODBC-drivrutin - Den tillåter applikationer som stöder ODBC-protokollet att ansluta till Hive.
Hive Services
Följande tjänster tillhandahålls av Hive:-
- Hive CLI - Hive CLI (Command Line Interface) är ett skal där vi kan köra Hive-frågor och kommandon.
- Hive Web User Interface - Hive Web UI är bara ett alternativ till Hive CLI. Det tillhandahåller ett webbaserat GUI för att köra Hive-frågor och kommandon.
- Hive MetaStore - Det är ett centralt arkiv som lagrar all strukturinformation för olika tabeller och partitioner i lagret. Den innehåller också metadata för kolumn och dess typinformation, serializers och deserializers som används för att läsa och skriva data och motsvarande HDFS-filer där data lagras.
- Hive Server - Den kallas Apache Thrift Server. Den accepterar begäran från olika klienter och tillhandahåller den till Hive Driver.
- Hive Driver - Den tar emot frågor från olika källor som webbgränssnitt, CLI, Thrift och JDBC/ODBC-drivrutin. Den överför frågorna till kompilatorn.
- Hive Compiler - Syftet med kompilatorn är att analysera frågan och utföra semantisk analys av de olika frågeblocken och uttrycken. Det konverterar HiveQL-satser till MapReduce-jobb.
- Hive Execution Engine - Optimizer genererar den logiska planen i form av DAG av map-reduce-uppgifter och HDFS-uppgifter. I slutändan exekverar exekveringsmotorn de inkommande uppgifterna i ordning efter deras beroenden.