A hashtabell är en datastruktur som möjliggör snabb infogning, radering och hämtning av data. Det fungerar genom att använda en hash-funktion för att mappa en nyckel till ett index i en array. I den här artikeln kommer vi att implementera en hashtabell i Python med hjälp av separat kedja för att hantera kollisioner.
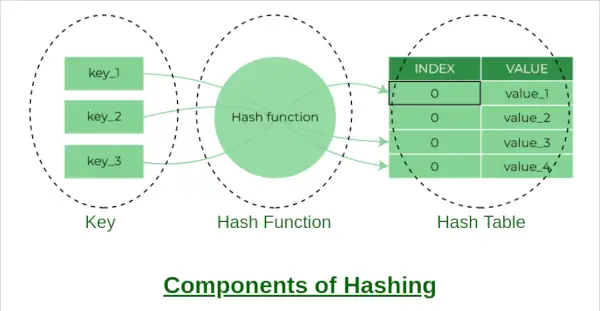
Komponenter av hashing
Separat kedja är en teknik som används för att hantera kollisioner i en hashtabell. När två eller flera nycklar mappar till samma index i arrayen, lagrar vi dem i en länkad lista vid det indexet. Detta gör att vi kan lagra flera värden på samma index och fortfarande kunna hämta dem med deras nyckel.
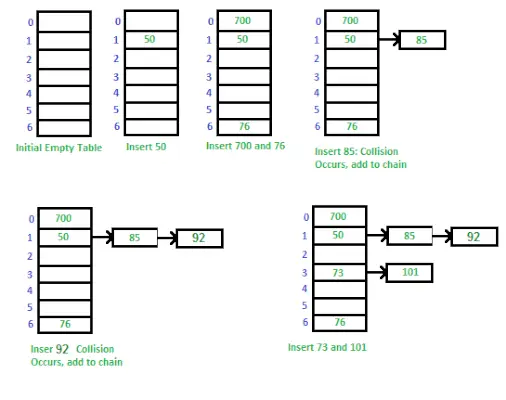
Sätt att implementera Hash Table med Separate Chaining
Sätt att implementera Hash Table med Separate Chaining:
Skapa två klasser: ' Nod 'och' HashTable '.
den ' Nod ' klass kommer att representera en nod i en länkad lista. Varje nod kommer att innehålla ett nyckel-värdepar, samt en pekare till nästa nod i listan.
Python3
class> Node:> >def> __init__(>self>, key, value):> >self>.key>=> key> >self>.value>=> value> >self>.>next> => None> |
java-operatör
>
>
Klassen 'HashTable' kommer att innehålla arrayen som kommer att hålla de länkade listorna, såväl som metoder för att infoga, hämta och ta bort data från hashtabellen.
Python3
class> HashTable:> >def> __init__(>self>, capacity):> >self>.capacity>=> capacity> >self>.size>=> 0> >self>.table>=> [>None>]>*> capacity> |
>
>
den ' __varm__ ' metoden initierar hashtabellen med en given kapacitet. Det ställer in kapacitet 'och' storlek ' variabler och initierar arrayen till 'Ingen'.
Nästa metod är _hash ’ metod. Denna metod tar en nyckel och returnerar ett index i arrayen där nyckel-värdeparet ska lagras. Vi kommer att använda Pythons inbyggda hash-funktion för att hasha nyckeln och sedan använda modulo-operatorn för att få ett index i arrayen.
Python3
def> _hash(>self>, key):> >return> hash>(key)>%> self>.capacity> |
>
>
De 'Föra in' metod kommer att infoga ett nyckel-värdepar i hashtabellen. Det tar indexet där paret ska lagras med hjälp av _hash ’ metod. Om det inte finns någon länkad lista i det indexet, skapar den en ny nod med nyckel-värdeparet och ställer in den som listans huvud. Om det finns en länkad lista i det indexet, iterera genom listan tills den sista noden hittas eller nyckeln redan finns, och uppdatera värdet om nyckeln redan finns. Om den hittar nyckeln uppdaterar den värdet. Om den inte hittar nyckeln skapar den en ny nod och lägger till den i listans huvud.
Python3
def> insert(>self>, key, value):> >index>=> self>._hash(key)> >if> self>.table[index]>is> None>:> >self>.table[index]>=> Node(key, value)> >self>.size>+>=> 1> >else>:> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >current.value>=> value> >return> >current>=> current.>next> >new_node>=> Node(key, value)> >new_node.>next> => self>.table[index]> >self>.table[index]>=> new_node> >self>.size>+>=> 1> |
>
int till sträng
>
De Sök metod hämtar värdet som är associerat med en given nyckel. Den får först indexet där nyckel-värdeparet ska lagras med hjälp av _hash metod. Den söker sedan efter nyckeln i den länkade listan i det indexet. Om den hittar nyckeln returnerar den det associerade värdet. Om den inte hittar nyckeln höjer den en KeyError .
Python3
def> search(>self>, key):> >index>=> self>._hash(key)> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >return> current.value> >current>=> current.>next> >raise> KeyError(key)> |
>
>
De 'avlägsna' metod tar bort ett nyckel-värdepar från hashtabellen. Den får först indexet där paret ska lagras med hjälp av ` _hash ` metod. Den söker sedan efter nyckeln i den länkade listan i det indexet. Om den hittar nyckeln tar den bort noden från listan. Om den inte hittar nyckeln höjer den en ` KeyError `.
Python3
regex java
def> remove(>self>, key):> >index>=> self>._hash(key)> > >previous>=> None> >current>=> self>.table[index]> > >while> current:> >if> current.key>=>=> key:> >if> previous:> >previous.>next> => current.>next> >else>:> >self>.table[index]>=> current.>next> >self>.size>->=> 1> >return> >previous>=> current> >current>=> current.>next> > >raise> KeyError(key)> |
>
>
'__str__' metod som returnerar en strängrepresentation av hashtabellen.
Python3
def> __str__(>self>):> >elements>=> []> >for> i>in> range>(>self>.capacity):> >current>=> self>.table[i]> >while> current:> >elements.append((current.key, current.value))> >current>=> current.>next> >return> str>(elements)> |
>
>
Här är den fullständiga implementeringen av klassen 'HashTable':
Python3
class> Node:> >def> __init__(>self>, key, value):> >self>.key>=> key> >self>.value>=> value> >self>.>next> => None> > > class> HashTable:> >def> __init__(>self>, capacity):> >self>.capacity>=> capacity> >self>.size>=> 0> >self>.table>=> [>None>]>*> capacity> > >def> _hash(>self>, key):> >return> hash>(key)>%> self>.capacity> > >def> insert(>self>, key, value):> >index>=> self>._hash(key)> > >if> self>.table[index]>is> None>:> >self>.table[index]>=> Node(key, value)> >self>.size>+>=> 1> >else>:> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >current.value>=> value> >return> >current>=> current.>next> >new_node>=> Node(key, value)> >new_node.>next> => self>.table[index]> >self>.table[index]>=> new_node> >self>.size>+>=> 1> > >def> search(>self>, key):> >index>=> self>._hash(key)> > >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >return> current.value> >current>=> current.>next> > >raise> KeyError(key)> > >def> remove(>self>, key):> >index>=> self>._hash(key)> > >previous>=> None> >current>=> self>.table[index]> > >while> current:> >if> current.key>=>=> key:> >if> previous:> >previous.>next> => current.>next> >else>:> >self>.table[index]>=> current.>next> >self>.size>->=> 1> >return> >previous>=> current> >current>=> current.>next> > >raise> KeyError(key)> > >def> __len__(>self>):> >return> self>.size> > >def> __contains__(>self>, key):> >try>:> >self>.search(key)> >return> True> >except> KeyError:> >return> False> > > # Driver code> if> __name__>=>=> '__main__'>:> > ># Create a hash table with> ># a capacity of 5> >ht>=> HashTable(>5>)> > ># Add some key-value pairs> ># to the hash table> >ht.insert(>'apple'>,>3>)> >ht.insert(>'banana'>,>2>)> >ht.insert(>'cherry'>,>5>)> > ># Check if the hash table> ># contains a key> >print>(>'apple'> in> ht)># True> >print>(>'durian'> in> ht)># False> > ># Get the value for a key> >print>(ht.search(>'banana'>))># 2> > ># Update the value for a key> >ht.insert(>'banana'>,>4>)> >print>(ht.search(>'banana'>))># 4> > >ht.remove(>'apple'>)> ># Check the size of the hash table> >print>(>len>(ht))># 3> |
>
>Produktion
True False 2 4 3>
Tidskomplexitet och rymdkomplexitet:
- De tidskomplexitet av Föra in , Sök och avlägsna metoder i en hashtabell som använder separat kedja beror på storleken på hashtabellen, antalet nyckel-värdepar i hashtabellen och längden på den länkade listan vid varje index.
- Om man antar en bra hashfunktion och en enhetlig fördelning av nycklar är den förväntade tidskomplexiteten för dessa metoder O(1) för varje operation. Men i värsta fall kan tidskomplexiteten vara På) , där n är antalet nyckel-värdepar i hashtabellen.
- Det är dock viktigt att välja en bra hashfunktion och en lämplig storlek på hashtabellen för att minimera sannolikheten för kollisioner och säkerställa bra prestanda.
- De rymdkomplexitet för en hashtabell som använder separat kedja beror på storleken på hashtabellen och antalet nyckel-värdepar som lagras i hashtabellen.
- Själva hashtabellen tar O(m) space, där m är hashtabellens kapacitet. Varje länkad listnod tar O(1) mellanslag, och det kan vara högst n noder i de länkade listorna, där n är antalet nyckel-värdepar som lagras i hashtabellen.
- Därför är den totala rymdkomplexiteten O(m + n) .
Slutsats:
I praktiken är det viktigt att välja en lämplig kapacitet för hashtabellen för att balansera utrymmesanvändningen och sannolikheten för kollisioner. Om kapaciteten är för liten ökar sannolikheten för kollisioner, vilket kan orsaka prestandaförsämring. Å andra sidan, om kapaciteten är för stor kan hashtabellen förbruka mer minne än nödvändigt.