Nyckelordet IDENTITY är en egenskap i SQL Server. När en tabellkolumn definieras med en identitetsegenskap kommer dess värde att vara automatiskt genererat inkrementellt värde . Detta värde skapas automatiskt av servern. Därför kan vi inte manuellt ange ett värde i en identitetskolumn som användare. Därför, om vi markerar en kolumn som identitet, kommer SQL Server att fylla i den på ett sätt som ökar automatiskt.
Syntax
Följande är syntaxen för att illustrera användningen av IDENTITY-egenskapen i SQL Server:
IDENTITY[(seed, increment)]
Syntaxparametrarna ovan förklaras nedan:
Låt oss förstå detta koncept genom ett enkelt exempel.
Anta att vi har en ' Studerande ' bord, och vi vill ha Student-ID ska genereras automatiskt. Vi har en början student-ID för 10 och vill öka den med 1 för varje nytt ID. I det här scenariot måste följande värden definieras.
Utsäde: 10
Ökning: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
OBS: Endast en identifieringskolumn är tillåten per tabell i SQL Server.
Exempel på SQL Server IDENTITY
Låt oss förstå hur vi kan använda identitetsegenskapen i tabellen. Identitetsegenskapen i en kolumn kan ställas in antingen när den nya tabellen skapas eller efter att den har skapats. Här kommer vi att se båda fallen med exempel.
IDENTITY-egenskap med ny tabell
Följande sats kommer att skapa en ny tabell med egenskapen identitet i den angivna databasen:
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Därefter kommer vi att infoga en ny rad i den här tabellen med en PRODUKTION klausul för att se det automatiskt genererade person-id:t:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
Om du kör den här frågan visas följande utdata:
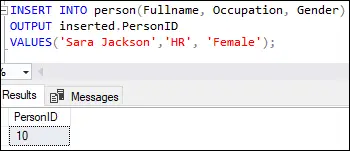
Denna utdata visar att den första raden har infogats med värdet tio i PersonID kolumn enligt specifikationen i kolumnen för tabelldefinitionens identitet.
Låt oss infoga en annan rad i person bord som nedan:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
Denna fråga returnerar följande utdata:

Denna utdata visar att den andra raden har infogats med värdet 11 och den tredje raden med värdet 12 i kolumnen PersonID.
IDENTITY-egenskap med befintlig tabell
Vi kommer att förklara detta koncept genom att först ta bort tabellen ovan och skapa dem utan identitetsegenskap. Utför satsen nedan för att ta bort tabellen:
DROP TABLE person;
Därefter skapar vi en tabell med hjälp av nedanstående fråga:
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Om vi vill lägga till en ny kolumn med egenskapen identitet i en befintlig tabell, måste vi använda kommandot ALTER. Frågan nedan kommer att lägga till PersonID som en identitetskolumn i persontabellen:
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
Lägger till värde i identitetskolumnen explicit
Om vi lägger till en ny rad i tabellen ovan genom att explicit ange identitetskolumns värde, kommer SQL Server att ge ett fel. Se frågan nedan:
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
Att köra den här frågan kommer att leda till följande fel:

För att explicit infoga identitetskolumnvärdet måste vi först ställa in IDENTITY_INSERT-värdet PÅ. Utför sedan insert-operationen för att lägga till en ny rad i tabellen och ställ sedan in IDENTITY_INSERT-värdet AV. Se kodskriptet nedan:
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT PÅ låter användare lägga in data i identitetskolumner, medan IDENTITY_INSERT AV hindrar dem från att lägga till värde till den här kolumnen.
Genom att köra kodskriptet visas nedanstående utdata där vi kan se att PersonID med värde 14 har infogats framgångsrikt.

IDENTITET Funktion
SQL Server tillhandahåller vissa identitetsfunktioner för att arbeta med IDENTITY-kolumnerna i en tabell. Dessa identitetsfunktioner listas nedan:
- @@IDENTITY Funktion
- SCOPE_IDENTITY() Funktion
- IDENT_CURRENT Funktion
- IDENTITET Funktion
Låt oss ta en titt på IDENTITY-funktionerna med några exempel.
@@IDENTITY Funktion
@@IDENTITY är en systemdefinierad funktion som visar det senaste identitetsvärdet (maximalt använt identitetsvärde) skapat i en tabell för IDENTITY-kolumnen i samma session. Denna funktionskolumn returnerar identitetsvärdet som genereras av satsen efter att ha infogat en ny post i en tabell. Den returnerar en NULL värde när vi kör en fråga som inte skapar IDENTITY-värden. Det fungerar alltid inom ramen för den aktuella sessionen. Den kan inte användas på distans.
Exempel
Anta att vi har det nuvarande maximala identitetsvärdet i persontabellen är 13. Nu kommer vi att lägga till en post i samma session som ökar identitetsvärdet med ett. Sedan kommer vi att använda @@IDENTITY-funktionen för att få det senaste identitetsvärdet skapat i samma session.
Här är hela kodskriptet:
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
Att köra skriptet kommer att returnera följande utdata där vi kan se det maximala använda identitetsvärdet är 14.

SCOPE_IDENTITY() Funktion
SCOPE_IDENTITY() är en systemdefinierad funktion till visa det senaste identitetsvärdet i en tabell under nuvarande omfattning. Denna omfattning kan vara en modul, trigger, funktion eller en lagrad procedur. Den liknar @@IDENTITY()-funktionen, förutom att den här funktionen bara har en begränsad omfattning. Funktionen SCOPE_IDENTITY returnerar NULL om vi kör den före infogningsoperationen som genererar ett värde i samma omfång.
Exempel
Koden nedan använder både @@IDENTITY och SCOPE_IDENTITY()-funktionen i samma session. Det här exemplet visar först det sista identitetsvärdet och infogar sedan en rad i tabellen. Därefter utför den båda identitetsfunktionerna.
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
Om du kör koden visas samma värde i den aktuella sessionen och liknande omfattning. Se utgångsbilden nedan:

Nu ska vi se hur båda funktionerna är olika med ett exempel. Först skapar vi två namngivna tabeller anställd_data och avdelning med hjälp av följande uttalande:
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
Därefter skapar vi en INSERT-utlösare i tabellen för anställda_data. Denna utlösare anropas för att infoga en rad i avdelningstabellen när vi infogar en rad i tabellen anställd_data.
Frågan nedan skapar en trigger för att infoga ett standardvärde 'DEN' i avdelningstabellen på varje infogningsfråga i tabellen anställd_data:
vad betyder detta xd
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
Efter att ha skapat en utlösare kommer vi att infoga en post i tabellen anställd_data och se utdata från både @@IDENTITY och SCOPE_IDENTITY() funktioner.
INSERT INTO employee_data VALUES ('John Mathew');
Genom att köra frågan läggs en rad till i tabellen werknemer_data och genererar ett identitetsvärde i samma session. När infogningsfrågan har körts i tabellen anställd_data anropar den automatiskt en utlösare för att lägga till en rad i avdelningstabellen. Identitetens startvärde är 1 för anställd_data och 100 för avdelningstabellen.
Slutligen utför vi nedanstående satser som visar utdata 100 för funktionen SELECT @@IDENTITY och 1 för funktionen SCOPE_IDENTITY eftersom de endast returnerar identitetsvärde i samma omfång.
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
Här är resultatet:

IDENT_CURRENT() Funktion
IDENT_CURRENT är en systemdefinierad funktion till visa det senaste IDENTITY-värdet genereras för en given tabell under vilken anslutning som helst. Den här funktionen tar inte hänsyn till omfattningen av SQL-frågan som skapar identitetsvärdet. Denna funktion kräver tabellnamnet som vi vill få identitetsvärdet för.
Exempel
Vi kan förstå det genom att först öppna de två anslutningsfönstren. Vi kommer att infoga en post i det första fönstret som genererar identitetsvärdet 15 i persontabellen. Därefter kan vi verifiera detta identitetsvärde i ett annat anslutningsfönster där vi kan se samma utdata. Här är hela koden:
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
Om du kör ovanstående koder i två olika fönster visas samma identitetsvärde.

IDENTITY() Funktion
Funktionen IDENTITY() är en systemdefinierad funktion används för att infoga en identitetskolumn i en ny tabell . Denna funktion skiljer sig från egenskapen IDENTITY som vi använder med CREATE TABLE- och ALTER TABLE-satserna. Vi kan endast använda den här funktionen i en SELECT INTO-sats, som används vid överföring av data från en tabell till en annan.
Följande syntax illustrerar användningen av denna funktion i SQL Server:
IDENTITY (data_type , seed , increment) AS column_name
Om en källtabell har en IDENTITY-kolumn, ärver tabellen som skapas med ett SELECT INTO-kommando den som standard. Till exempel , vi har tidigare skapat en tabellperson med en identitetskolumn. Anta att vi skapar en ny tabell som ärver persontabellen med hjälp av SELECT INTO-satserna med IDENTITY()-funktionen. I så fall får vi ett fel eftersom källtabellen redan har en identitetskolumn. Se frågan nedan:
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
Om du kör ovanstående sats kommer följande felmeddelande att returneras:

Låt oss skapa en ny tabell utan identitetsegenskap med hjälp av följande uttalande:
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
Kopiera sedan den här tabellen med hjälp av SELECT INTO-satsen inklusive IDENTITY-funktionen enligt följande:
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
När satsen körs kan vi verifiera den med hjälp av sp_hjälp kommando som visar tabellegenskaper.

Du kan se kolumnen IDENTITET i FRÄSTBART egenskaper enligt de angivna villkoren.
Om vi använder den här funktionen med SELECT-satsen kommer SQL Server genom följande felmeddelande:
Medd. 177, nivå 15, tillstånd 1, rad 2 IDENTITY-funktionen kan endast användas när SELECT-satsen har en INTO-sats.
Återanvänder IDENTITY-värden
Vi kan inte återanvända identitetsvärdena i SQL Server-tabellen. När vi tar bort valfri rad från identitetskolumntabellen skapas en lucka i identitetskolumnen. Dessutom kommer SQL Server att skapa en lucka när vi infogar en ny rad i identitetskolumnen och uttalandet misslyckas eller rullas tillbaka. Mellanrummet indikerar att identitetsvärdena går förlorade och inte kan genereras igen i IDENTITY-kolumnen.
Betrakta exemplet nedan för att förstå det praktiskt. Vi har redan en persontabell som innehåller följande data:

Därefter kommer vi att skapa ytterligare två tabeller med namnet 'placera' , och ' person_position ' med hjälp av följande uttalande:
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
Därefter försöker vi infoga en ny post i persontabellen och tilldela dem en position genom att lägga till en ny rad i person_position-tabellen. Vi kommer att göra detta genom att använda transaktionsutdraget enligt nedan:
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
Ovanstående transaktionskodskript kör den första infogningssatsen framgångsrikt. Men det andra uttalandet misslyckades eftersom det inte fanns någon position med id tio i positionstabellen. Därför rullades hela transaktionen tillbaka.
Eftersom vi har maximalt identitetsvärde i kolumnen PersonID är 16, konsumerade den första infogningssatsen identitetsvärdet 17, och sedan återställdes transaktionen. Därför, om vi infogar nästa rad i tabellen Person, kommer nästa identitetsvärde att vara 18. Kör följande sats:
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
Efter att ha kontrollerat persontabellen igen ser vi att den nyligen tillagda posten innehåller identitetsvärde 18.

Två IDENTITY-kolumner i en enda tabell
Tekniskt sett är det inte möjligt att skapa två identitetskolumner i en enda tabell. Om vi gör detta, ger SQL Server ett fel. Se följande fråga:
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
När vi kör den här koden kommer vi att se följande fel:

Vi kan dock skapa två identitetskolumner i en enda tabell genom att använda den beräknade kolumnen. Följande fråga skapar en tabell med en beräknad kolumn som använder den ursprungliga identitetskolumnen och minskar den med 1.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
Därefter kommer vi att lägga till några data i den här tabellen med kommandot nedan:
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
Slutligen kontrollerar vi tabelldata med hjälp av SELECT-satsen. Den returnerar följande utdata:

Vi kan se på bilden hur SecondID-kolumnen fungerar som en andra identitetskolumn, som minskar med tio från startvärdet på 9990.
Feluppfattningar i SQL Servers IDENTITY-kolumn
DBA-användaren har många missuppfattningar om SQL Server-identitetskolumner. Följande är listan över de vanligaste missuppfattningarna om identitetskolumner som kan ses:
IDENTITY-kolumnen är UNIK: Enligt SQL Servers officiella dokumentation kan identitetsegenskapen inte garantera att kolumnvärdet är unikt. Vi måste använda en PRIMARY KEY, UNIQUE constraint eller UNIQUE index för att framtvinga en unik kolumn.
IDENTITY-kolumnen genererar på varandra följande nummer: Officiell dokumentation anger tydligt att de tilldelade värdena i identitetskolumnen kan gå förlorade vid databasfel eller omstart av servern. Det kan orsaka luckor i identitetsvärdet under infogning. Gapet kan också skapas när vi tar bort värdet från tabellen, eller när insert-satsen rullas tillbaka. De värden som genererar luckor kan inte användas vidare.
IDENTITY-kolumnen kan inte automatiskt generera befintliga värden: Det är inte möjligt för identitetskolumnen att automatiskt generera befintliga värden förrän identitetsegenskapen har återställts genom att använda kommandot DBCC CHECKIDENT. Det tillåter oss att justera startvärdet (startvärdet för raden) för identitetsegenskapen. Efter att ha utfört detta kommando kommer SQL Server inte att kontrollera de nyskapade värdena som redan finns i tabellen eller inte.
IDENTITY-kolumnen som PRIMÄRNYCKEL räcker för att identifiera raden: Om en primärnyckel innehåller identitetskolumnen i tabellen utan några andra unika begränsningar, kan kolumnen lagra dubbletter av värden och förhindra kolumnunikhet. Som vi vet kan primärnyckeln inte lagra dubbletter av värden, men identitetskolumnen kan lagra dubbletter; det rekommenderas att inte använda primärnyckeln och identitetsegenskapen i samma kolumn.
Använder fel verktyg för att få tillbaka identitetsvärden efter en infogning: Det är också en vanlig missuppfattning om omedvetenhet om skillnaderna mellan funktionerna @@IDENTITY, SCOPE_IDENTITY(), IDENT_CURRENT och IDENTITY() för att få identitetsvärdet direkt infogat från satsen vi just har kört.
Skillnad mellan SEQUENCE och IDENTITY
Vi använder både SEQUENCE och IDENTITY för att generera autonummer. Det har dock vissa skillnader, och den största skillnaden är att identitet är tabellberoende, medan sekvens inte är det. Låt oss sammanfatta deras skillnader i tabellformen:
| IDENTITET | SEKVENS |
|---|---|
| Identitetsegenskapen används för en specifik tabell och kan inte delas med andra tabeller. | En DBA definierar sekvensobjektet som kan delas mellan flera tabeller eftersom det är oberoende av en tabell. |
| Den här egenskapen genererar automatiskt värden varje gång insert-satsen körs på tabellen. | Den använder NEXT VALUE FOR-satsdelen för att generera nästa värde för ett sekvensobjekt. |
| SQL Server återställer inte kolumnvärdet för identitetsegenskapen till dess initiala värde. | SQL Server kan återställa värdet för sekvensobjektet. |
| Vi kan inte ställa in det maximala värdet för identitetsegendom. | Vi kan ställa in maxvärdet för sekvensobjektet. |
| Det introduceras i SQL Server 2000. | Det introduceras i SQL Server 2012. |
| Den här egenskapen kan inte generera identitetsvärde i fallande ordning. | Det kan generera värden i fallande ordning. |
Slutsats
Den här artikeln ger en fullständig översikt över IDENTITY-egenskapen i SQL Server. Här har vi lärt oss hur och när identitetsegenskap används, dess olika funktioner, missuppfattningar och hur den skiljer sig från sekvensen.