Vi läser de linjära datastrukturerna som en array, länkad lista, stack och kö där alla element är ordnade på ett sekventiellt sätt. De olika datastrukturerna används för olika typer av data.
Några faktorer beaktas vid val av datastruktur:
genomstruken markdown
Ett träd är också en av de datastrukturer som representerar hierarkiska data. Anta att vi vill visa de anställda och deras positioner i hierarkisk form så kan det representeras enligt nedan:
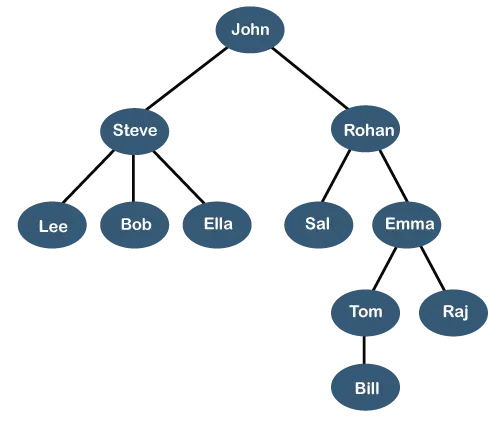
Ovanstående träd visar organisationshierarki av något företag. I ovanstående struktur, john är vd av företaget, och John har två direkta rapporter namngivna som Steve och Rohan . Steve har tre direkta rapporter namngivna Lee, Bob, Ella var Steve är chef. Bob har två direkta rapporter namngivna Skall och Emma . Emma har två direktrapporter namngivna Tom och Raj . Tom har en direktrapport namngiven Räkningen . Denna speciella logiska struktur är känd som en Träd . Dess struktur liknar det riktiga trädet, så det heter a Träd . I den här strukturen rot är överst, och dess grenar rör sig i riktning nedåt. Därför kan vi säga att trädets datastruktur är ett effektivt sätt att lagra data på ett hierarkiskt sätt.
Låt oss förstå några nyckelpunkter i trädets datastruktur.
- En träddatastruktur definieras som en samling objekt eller enheter som kallas noder som är sammanlänkade för att representera eller simulera hierarki.
- En träddatastruktur är en icke-linjär datastruktur eftersom den inte lagras på ett sekventiellt sätt. Det är en hierarkisk struktur eftersom element i ett träd är ordnade på flera nivåer.
- I träddatastrukturen är den översta noden känd som en rotnod. Varje nod innehåller vissa data, och data kan vara av vilken typ som helst. I ovanstående trädstruktur innehåller noden namnet på den anställde, så typen av data skulle vara en sträng.
- Varje nod innehåller en del data och länken eller referensen till andra noder som kan kallas barn.
Några grundläggande termer som används i träddatastrukturen.
Låt oss överväga trädstrukturen, som visas nedan:

I ovanstående struktur är varje nod märkt med något nummer. Varje pil som visas i ovanstående figur är känd som en länk mellan de två noderna.
Egenskaper för träddatastruktur

Baserat på egenskaperna för träddatastrukturen klassificeras träd i olika kategorier.
Implementering av träd
Träddatastrukturen kan skapas genom att skapa noderna dynamiskt med hjälp av pekarna. Trädet i minnet kan representeras enligt nedan:

Ovanstående figur visar representationen av träddatastrukturen i minnet. I ovanstående struktur innehåller noden tre fält. Det andra fältet lagrar data; det första fältet lagrar adressen till det vänstra barnet, och det tredje fältet lagrar adressen till det högra barnet.
I programmering kan strukturen för en nod definieras som:
struct node { int data; struct node *left; struct node *right; } Ovanstående struktur kan endast definieras för de binära träden eftersom det binära trädet kan ha ytterst två barn, och generiska träd kan ha fler än två barn. Strukturen för noden för generiska träd skulle vara annorlunda jämfört med det binära trädet.
välj från flera tabeller sql
Tillämpningar av träd
Följande är tillämpningarna för träd:
Typer av träddatastruktur
Följande är typerna av en träddatastruktur:
string tokenizer java

Det kan finnas n antal underträd i ett allmänt träd. I det allmänna trädet är underträden oordnade eftersom noderna i underträdet inte kan ordnas.
Varje icke-tomt träd har en nedåtgående kant, och dessa kanter är anslutna till noderna som kallas barnnoder . Rotnoden är märkt med nivå 0. Noderna som har samma förälder är kända som syskon .

För att veta mer om det binära trädet, klicka på länken nedan:
https://www.javatpoint.com/binary-tree
Varje nod i det vänstra underträdet måste innehålla ett värde som är mindre än värdet på rotnoden, och värdet för varje nod i det högra underträdet måste vara större än värdet på rotnoden.
En nod kan skapas med hjälp av en användardefinierad datatyp som kallas struktur, enligt nedanstående:
struct node { int data; struct node *left; struct node *right; } Ovanstående är nodstrukturen med tre fält: datafält, det andra fältet är den vänstra pekaren för nodtypen och det tredje fältet är den högra pekaren för nodtypen.
För att veta mer om det binära sökträdet, klicka på länken nedan:
https://www.javatpoint.com/binary-search-tree
Det är en av typerna av det binära trädet, eller så kan vi säga att det är en variant av det binära sökträdet. AVL-trädet tillfredsställer egenskapen hos binärt träd såväl som av binärt sökträd . Det är ett självbalanserande binärt sökträd som uppfanns av Adelson Velsky Lindas . Här innebär självbalansering att balansera höjderna på vänster underträd och höger underträd. Denna balansering mäts i termer av balanserande faktor .
Vi kan betrakta ett träd som ett AVL-träd om trädet följer det binära sökträdet samt en balanserande faktor. Balanseringsfaktorn kan definieras som skillnaden mellan höjden på det vänstra underträdet och höjden på det högra underträdet . Balansfaktorns värde måste vara antingen 0, -1 eller 1; därför bör varje nod i AVL-trädet ha värdet på balanseringsfaktorn antingen som 0, -1 eller 1.
För att veta mer om AVL-trädet, klicka på länken nedan:
https://www.javatpoint.com/avl-tree
Det röd-svarta trädet är det binära sökträdet. Förutsättningen för det röd-svarta trädet är att vi bör känna till det binära sökträdet. I ett binärt sökträd bör värdet på det vänstra underträdet vara mindre än värdet för den noden, och värdet på det högra underträdet bör vara större än värdet på den noden. Som vi vet är tidskomplexiteten för binär sökning i genomsnittsfallet log2n, det bästa fallet är O(1), och det sämsta fallet är O(n).
När någon operation utförs på trädet vill vi att vårt träd ska vara balanserat så att alla operationer som sökning, infogning, radering etc. tar kortare tid, och alla dessa operationer kommer att ha samma tidskomplexitet som logga2n.
Det röd-svarta trädet är ett självbalanserande binärt sökträd. AVL-trädet är också ett höjdbalanserande binärt sökträd då varför behöver vi ett röd-svart träd . I AVL-trädet vet vi inte hur många rotationer som skulle krävas för att balansera trädet, men i det Röd-svarta trädet krävs max 2 rotationer för att balansera trädet. Den innehåller en extra bit som representerar antingen den röda eller svarta färgen på en nod för att säkerställa balanseringen av trädet.
Splayträdets datastruktur är också ett binärt sökträd där nyligen nått element placeras vid rotpositionen av trädet genom att utföra några rotationsoperationer. Här, splaying betyder den nyligen öppnade noden. Det är en självbalanserande binärt sökträd som inte har något explicit balansvillkor som AVL träd.
java karta
Det kan vara en möjlighet att höjden på splayträdet inte är balanserad, dvs. höjden på både vänster och höger underträd kan skilja sig, men operationerna i splay tree tar ordning på lugna tid var n är antalet noder.
Splayträd är ett balanserat träd men det kan inte betraktas som ett höjdbalanserat träd eftersom det efter varje operation utförs rotation vilket leder till ett balanserat träd.
Treap-datastrukturen kom från Tree and Heap-datastrukturen. Så den omfattar egenskaperna för både träd- och heapdatastrukturer. I binärt sökträd måste varje nod på det vänstra underträdet vara lika med eller mindre än värdet på rotnoden och varje nod på det högra underträdet måste vara lika med eller större än värdet på rotnoden. I högdatastrukturen innehåller både höger och vänster underträd större nycklar än roten; därför kan vi säga att rotnoden innehåller det lägsta värdet.
I treap-datastrukturen har varje nod båda nyckel och prioritet där nyckeln härleds från det binära sökträdet och prioritet härleds från högdatastrukturen.
De Treap datastrukturen följer två egenskaper som anges nedan:
java kartor
- Höger underordnad av en nod>=nuvarande nod och vänster underordnad av en nod<=current node (binary tree)< li>
- Underordnade underträd måste vara större än noden (högen)
B-träd är ett balanserat m-väg träd var m definierar trädets ordning. Hittills har vi läst att noden bara innehåller en nyckel men b-tree kan ha mer än en nyckel och fler än 2 barn. Den upprätthåller alltid den sorterade datan. I binärt träd är det möjligt att lövnoder kan vara på olika nivåer, men i b-träd måste alla lövnoder vara på samma nivå.
Om ordningen är m har noden följande egenskaper:
- Varje nod i ett b-träd kan ha maximum m barn
- För minsta barn har en lövnod 0 barn, rotnoden har minst 2 barn och den interna noden har minsta tak på m/2 barn. Till exempel är värdet på m 5 vilket betyder att en nod kan ha 5 barn och interna noder kan innehålla max 3 barn.
- Varje nod har maximala (m-1) nycklar.
Rotnoden måste innehålla minst 1 nyckel och alla andra noder måste innehålla minst tak på m/2 minus 1 nycklar.