Excel-ark är mycket instinktiva och användarvänliga, vilket gör dem idealiska för att manipulera stora datamängder även för mindre tekniska personer. Om du letar efter platser där du kan lära dig att manipulera och automatisera saker i Excel-filer med hjälp av Pytonorm , Sök inte mer. Du är på rätt plats.
I den här artikeln kommer du att lära dig hur du använder Pandas att arbeta med Excel-kalkylblad. I den här artikeln kommer vi att lära oss om:
- Läsa Excel fil använder Pandas i Python
- Installera och importera pandor
- Läsa flera Excel-ark med Pandas
- Tillämpning av olika Pandafunktioner
Läser Excel-fil med Pandas i Python
Installera pandor
För att installera Pandas i Python kan vi använda följande kommando i kommandotolken:
pip install pandas>
För att installera Pandas i Anaconda kan vi använda följande kommando i Anaconda Terminal:
conda install pandas>
Importera pandor
Först och främst måste vi importera Pandas-modulen, vilket kan göras genom att köra kommandot:
Python3
import> pandas as pd> |
>
>
Indatafil: Låt oss anta att Excel-filen ser ut så här
Blad 1:

Blad 1
Blad 2:
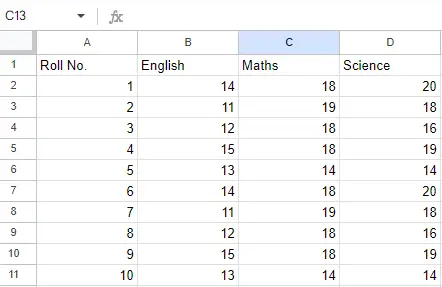
Blad 2
Nu kan vi importera Excel-filen med hjälp av read_excel-funktionen i Pandas för att läsa Excel-fil med Pandas i Python. Den andra satsen läser data från Excel och lagrar den i en pandas Data Frame som representeras av variabeln newData.
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Produktion:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Laddar flera ark med metoden Concat().
Om det finns flera ark i Excel-arbetsboken importerar kommandot data från det första arket. För att göra en dataram med alla ark i arbetsboken är den enklaste metoden att skapa olika dataramar separat och sedan sammanfoga dem. Read_excel-metoden tar argumentet sheet_name och index_col där vi kan specificera arket som ramen ska vara gjord av och index_col specificerar titelkolumnen, som visas nedan:
Exempel:
Det tredje påståendet sammanfogar båda arken. Nu för att kontrollera hela dataramen kan vi helt enkelt köra följande kommando:
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Produktion:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Head() och Tail() metoder i Pandas
För att se 5 kolumner från toppen och från botten av dataramen kan vi köra kommandot. Detta huvud() och svans() metoden tar också argument som siffror för antalet kolumner som ska visas.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Produktion:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Shape() metod
De shape() metod kan användas för att se antalet rader och kolumner i dataramen enligt följande:
Python3
newData.shape> |
>
>
Produktion:
(20, 3)>
Sort_values()-metoden i Pandas
Om någon kolumn innehåller numeriska data kan vi sortera den kolumnen med hjälp av sort_values() metod i pandor enligt följande:
Python3
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Låt oss nu anta att vi vill ha de 5 bästa värdena i den sorterade kolumnen, vi kan använda metoden head() här:
Python3
sorted_column.head(>5>)> |
>
>
Produktion:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Vi kan göra det med vilken numerisk kolumn som helst i dataramen som visas nedan:
Python3
newData[>'Maths'>].head()> |
>
>
Produktion:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Pandas Describe() metod
Anta nu att vår data mestadels är numerisk. Vi kan få statistisk information som medelvärde, max, min, etc. om dataramen med hjälp av beskriva() metod enligt nedan:
Python3
newData.describe()> |
>
>
Produktion:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Detta kan också göras separat för alla numeriska kolumner med följande kommando:
Python3
mamta kulkarni skådespelare
newData[>'English'>].mean()> |
>
>
Produktion:
14.3>
Även annan statistisk information kan beräknas med respektive metod. Liksom i Excel kan formler också tillämpas, och beräknade kolumner kan skapas enligt följande:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
Produktion:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Efter att ha arbetat på data i dataramen kan vi exportera data tillbaka till en Excel-fil med metoden to_excel. För detta måste vi ange en utdata Excel-fil där de transformerade data ska skrivas, som visas nedan:
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Produktion:
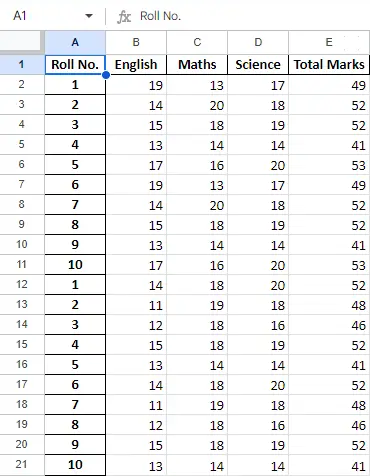
Slutblad