Z-Score i statistik är ett mått på hur många standardavvikelser en datapunkt är från medelvärdet av en fördelning. Låt oss hitta z-poäng i statistik. En z-poäng på 0 indikerar att datapunktens poäng är densamma som medelpoängen. En positiv z-poäng indikerar att datapunkten är över genomsnittet, medan en negativ z-poäng indikerar att datapunkten är under genomsnittet.
Formeln för att beräkna en z-poäng är: z = (x – μ)/p
Var:
- x: är testvärdet
- m: är medelvärdet
- på: är standardvärdet
I den här artikeln kommer vi att diskutera följande begrepp:
Innehållsförteckning
- Vad är Z-Score?
- Hur beräknar man Z-poäng?
- Egenskaper för Z-Score
- Beräkna extremvärden med hjälp av Z-Score-värdet
- Implementering av Z-Score i Python
- Tillämpning av Z-Score
- Z-poäng vs. standardavvikelse
- Varför kallas Z-poäng standardpoäng?
Vad är Z-Score?
Z-poängen, även känd som standardpoängen, berättar för oss avvikelsen för en datapunkt från medelvärdet genom att uttrycka det i termer av standardavvikelser över eller under medelvärdet. Det ger oss en uppfattning om hur långt en datapunkt är från medelvärdet. Därför mäts Z-poängen i termer av standardavvikelse från medelvärdet. Till exempel, en Z-poäng på 2 indikerar att värdet är 2 standardavvikelser från medelvärdet. För att använda en z-poäng måste vi känna till populationsmedelvärdet (μ) och även populationens standardavvikelse (σ).
Formeln för Z-Score
En z-poäng kan beräknas med hjälp av följande formel.
z = (X – μ) / p
var,
- z = Z-poäng
- X = Elementets värde
- μ = Populationsmedelvärde
- σ = Populationsstandardavvikelse
Hur beräknar man Z-poäng?
Vi får populationsmedelvärdet (μ), populationens standardavvikelse (σ) och det observerade värdet (x) i problemformuleringen genom att ersätta detsamma i Z-poängekvationen ger oss Z-poängvärdet. Beroende på om den givna Z-poängen är positiv eller negativ, kan vi använda positiv Z-tabell eller negativ Z-tabell tillgänglig online eller på baksidan av din statistikbok i bilagan.
{kind=link}
{kind=link}
format sträng java
Exempel 1:
Du gör GATE-provet och får 500. Medelpoängen för GATE är 390 och standardavvikelsen är 45. Hur bra fick du på testet jämfört med den genomsnittliga testpersonen?
Lösning:
Följande data är lättillgänglig i frågeställningen ovan
Råpoäng/observat värde = X = 500
Medelpoäng = μ = 390
Standardavvikelse = σ = 45
Genom att tillämpa formeln för z-poäng,
z = (X – μ) / p
z = (500 – 390) / 45
z = 110 / 45 = 2,44
Detta betyder att din z-poäng är 2,44 .
Eftersom Z-poängen är positiv 2,44 kommer vi att använda den positiva Z-tabellen.
Låt oss nu ta en titt på Z Tabell (CC-BY) för att veta hur bra du gjorde jämfört med de andra testdeltagarna.
Följ instruktionerna nedan för att hitta sannolikheten från tabellen.
Här, z-poäng = 2,44, som i indikerar att datapunkten är 2,44 standardavvikelser över medelvärdet.
- Mappa först de två första siffrorna 2.4 på Y-axeln.
- Sedan längs X-axeln, karta 0.04
- Förena båda axlarna. Skärningspunkten mellan de två ger dig den kumulativa sannolikheten förknippad med Z-poängvärdet du letar efter
[Denna sannolikhet representerar arean under standardnormalkurvan till vänster om Z-poängen]
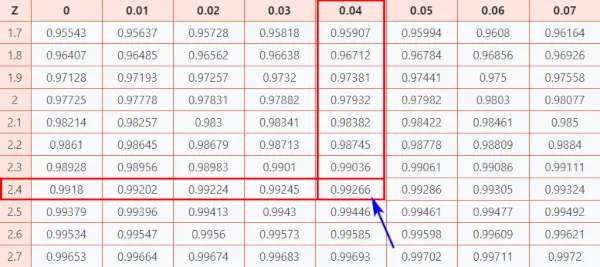
Normalfördelningstabell
Som ett resultat kommer du att få det slutliga värdet som är 0,99266 .
Nu måste vi jämföra hur vårt ursprungliga betyg på 500 på GATE-undersökningen jämförs med det genomsnittliga resultatet för partiet. För att göra det måste vi omvandla den kumulativa sannolikheten förknippad med Z-poängen till ett procentvärde.
0,99266 × 100 = 99,266 %
Till sist kan man säga att du har presterat bra än nästan 99 % av andra testtagare.
Exempel 2 : Vad är sannolikheten att en elev får mellan 350 och 400 (med ett medelpoäng μ på 390 och en standardavvikelse σ på 45)?
Lösning:
Minsta poäng = X1= 350
Maxpoäng = X2= 400
Genom att tillämpa formeln för z-poäng,
Med1= (X1 – m) / sid
10 till makten 6Med1= (350 – 390) / 45
Med1= -40 / 45 = -0,88
Med2= (X2– m) / sid
z2 = (400 – 390) / 45
Med2= 10/45 = 0,22
Eftersom z1 är negativ måste vi titta på ett negativt Z-tabell och hitta att kumulativ sannolikhet p1, den första sannolikheten, är 0,18943 .
Med2är positivt, så vi använder en positiv Z-tabell som ger en kumulativ sannolikhet p2av 0,58706 .
Den slutliga sannolikheten beräknas genom att subtrahera p1 från p2:
p = p2– sid1
p = 0,58706 – 0,18943 = 0,39763
Sannolikheten att en elev får mellan 350 och 400 är 39,763 % (0,39763 * 100).
Egenskaper för Z-Score
- Storleken på Z-poängen återspeglar hur långt en datapunkt är från medelvärdet i termer av standardavvikelser.
- Ett element som har en z-poäng på mindre än 0 representerar att elementet är mindre än medelvärdet.
- Z-poäng möjliggör jämförelse av datapunkter från olika distributioner.
- Ett element som har en z-poäng större än 0 representerar att elementet är större än medelvärdet.
- Ett element som har en z-poäng lika med 0 representerar att elementet är lika med medelvärdet.
- Ett element som har en z-poäng lika med 1 representerar att elementet är 1 standardavvikelse större än medelvärdet; en z-poäng lika med 2, 2 standardavvikelser större än medelvärdet och så vidare.
- Ett element med en z-poäng lika med -1 representerar att elementet är 1 standardavvikelse mindre än medelvärdet; en z-poäng lika med -2, 2 standardavvikelser mindre än medelvärdet och så vidare.
- Om antalet element i en given mängd är stort, så har cirka 68 % av elementen en z-poäng mellan -1 och 1; cirka 95 % har en z-poäng mellan -2 och 2; cirka 99 % har ett z-värde mellan -3 och 3. Detta är känt som den empiriska regeln, och den anger procentandelen data inom vissa standardavvikelser från medelvärdet i en normalfördelning som visas i bilden nedan.
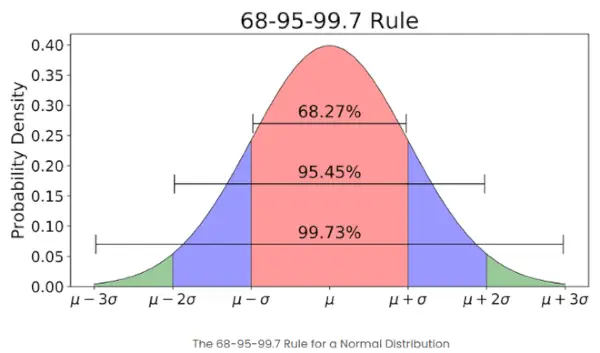
Den empiriska regeln i Normalfördelning
Beräkna extremvärden med hjälp av Z-Score-värdet
Vi kan beräkna extremvärden i data med hjälp av z-poängvärdet för datapunkterna. Stegen för att överväga en extremdatapunkt är som:
- Till en början samlar vi datauppsättningen där vi vill se extremvärdena
- Vi kommer att beräkna medelvärdet och standardavvikelsen för datasetet. Dessa värden kommer att användas för att beräkna z-poängvärdet för varje datapunkt.
- Vi kommer att beräkna z-poängvärdet för varje datapunkt. Formeln för att beräkna z-poängvärdet kommer att vara densamma som
Z = frac{{X – mu}}{{sigma}}
där X är datapunkten, μ är medelvärdet av datan och σ är standardavvikelsen för datamängden. - Vi kommer att bestämma cutoff-värdet för z-poängen, varefter datapunkten kan betraktas som en extremvärde. Detta cutoff-värde är en hyperparameter som vi bestämmer beroende på vårt projekt.
- En datapunkt vars z-poängvärde är större än 3 betyder att datapunkten inte tillhör 99,73 %-punkten av datamängden.
- Alla datapunkter vars z-poäng är större än vårt beslutade gränsvärde kommer att betraktas som en extremvärde.
Kolla upp: Z-poäng för Outlier Detection
Implementering av Z-Score i Python
Vi kan använda Python för att beräkna z-poängvärdet för datapunkter i datamängden. Vi kommer också att använda numpy-biblioteket för att beräkna medelvärde och standardavvikelse för datasetet.
Python3 import numpy as np def calculate_z_score(data): # Mean of the dataset mean = np.mean(data) # Standard Deviation of tha dataset std_dev = np.std(data) # Z-score of tha data points z_scores = (data - mean) / std_dev return z_scores # Example dataset dataset = [3,9, 23, 43,53, 4, 5,30, 35, 50, 70, 150, 6, 7, 8, 9, 10] z_scores = calculate_z_score(dataset) print('Z-Score :',z_scores) # Data points which lies outside 3 standard deviatioms are outliers # i.e outside range of99.73% values outliers = [data_point for data_point, z_score in zip(dataset, z_scores) if z_score>3] print(f'
Outliers i datasetet är {outliers}')> Produktion:
Z-poäng : [-0,7574907 -0,59097335 -0,20243286 0,35262498 0,6301539 -0,72973781
-0,70198492 -0,00816262 0,13060185 0,54689523 1,10195307 3,32218443
-0,67423202 -0,64647913 -0,61872624 -0,59097335 -0,56322046]
Outliers i datamängden är [150]
Tillämpning av Z-Score
- Z-poäng används ofta för funktionsskalning för att få olika funktioner till en gemensam skala. Normalisering av funktioner säkerställer att de har noll medelvärde och enhetsvarians, vilket kan vara fördelaktigt för vissa maskininlärningsalgoritmer, särskilt de som är beroende av distansmått.
- Z-poäng kan användas för att identifiera extremvärden i en datauppsättning. Datapunkter med Z-poäng över en viss tröskel (vanligtvis 3 standardavvikelser från medelvärdet) kan betraktas som extremvärden.
- Z-poäng kan användas i anomalidetekteringsalgoritmer för att identifiera instanser som avviker avsevärt från det förväntade beteendet.
- Z-poäng kan användas för att omvandla snedfördelningar till mer normala fördelningar.
- När man arbetar med regressionsmodeller kan Z-poäng av residualer analyseras för att kontrollera homoskedasticitet (konstant varians av residualer).
- Z-poäng kan användas i funktionsskalning genom att titta på deras standardavvikelser från medelvärdet.
Z-poäng vs. standardavvikelse
Z- Poäng | Standardavvikelse |
|---|---|
Förvandla rådata till en standardiserad skala. | Mäter mängden variation eller spridning i en uppsättning värden. |
Gör det lättare att jämföra värden från olika datamängder eftersom de tar bort de ursprungliga måttenheterna. | Standardavvikelse behåller de ursprungliga måttenheterna, vilket gör den mindre lämplig för direkta jämförelser mellan datauppsättningar med olika enheter. |
Ange hur långt en datapunkt är från medelvärdet i termer av standardavvikelser, vilket ger ett mått på datapunktens relativa position inom fördelningen | Uttryckt i samma enheter som originaldata, vilket ger ett absolut mått på hur utspridda värdena är runt medelvärdet |
Kolla upp: Z-poängtabell
Varför kallas Z-poäng standardpoäng?
Z-poäng är också kända som standardpoäng eftersom de standardiserar värdet av en slumpmässig variabel. Det betyder att listan med standardiserade poäng har ett medelvärde på 0 och en standardavvikelse på 1,0. Z-poäng möjliggör också jämförelse av poäng på olika typer av variabler. Detta beror på att de använder relativ ställning för att likställa poäng från olika variabler eller fördelningar.
Z-poäng används ofta för att jämföra en variabel med en standardnormalfördelning (med μ = 0 och σ = 1).
Z-Score i statistik – Vanliga frågor
Vad är betydelsen av positiva och negativa Z-poäng?
Positiva Z-poäng indikerar värden över medelvärdet, medan negativa Z-poäng indikerar värden under medelvärdet. Tecknet reflekterar riktningen för avvikelsen från medelvärdet.
Vad betyder en Z-poäng på 0?
En Z-poäng på 0 indikerar att datapunktens värde är exakt i medelvärdet av datamängden. Det tyder på att datapunkten varken ligger över eller under medelvärdet.
Vad är 68-95-99.7-regeln i förhållande till Z-Scores?
68-95-99.7-regeln, även känd som den empiriska regeln, säger att:
- Cirka 68 % av data faller inom 1 standardavvikelse från medelvärdet.
- Cirka 95 % faller inom 2 standardavvikelser.
- Cirka 99,7 % faller inom 3 standardavvikelser.
Kan Z-Scores användas för icke-normala fördelningar?
Z-poäng baseras på antagandet att data följer en normalfördelning. Men i praktiken är Z-Scores fördelaktiga för data som följer en normalfördelning. Även om Z-poäng kan beräknas för vilken fördelning som helst, blir deras tolkning mindre tillförlitlig och okomplicerad när man hanterar icke-normalfördelade data.
Hur kan Z-Scores tillämpas i verkliga situationer?
Z-Scores har olika applikationer, till exempel inom ekonomi för portföljanalys, utbildning för standardiserade tester, hälsa för kliniska bedömningar med mera. De tillhandahåller ett standardiserat mått för att jämföra och tolka data.