Sedan uppfinningen av datorer har människor använt termen ' Data ' för att hänvisa till datorinformation, antingen överförd eller lagrad. Det finns dock data som finns i ordertyper också. Data kan vara siffror eller texter skrivna på ett papper, i form av bitar och bytes lagrade i minnet av elektroniska enheter, eller fakta lagrade i en persons sinne. När världen började moderniseras blev denna data en viktig aspekt av allas vardag, och olika implementeringar gjorde det möjligt för dem att lagra dem på olika sätt.
Data är en samling fakta och siffror eller en uppsättning värden eller värden av ett specifikt format som hänvisar till en enda uppsättning objektvärden. Dataposterna klassificeras sedan i underposter, vilket är gruppen av poster som inte är känd som den enkla primära formen av objektet.
Låt oss överväga ett exempel där ett anställds namn kan delas upp i tre underpunkter: Första, Mellan och Sist. Ett ID som tilldelas en anställd kommer dock i allmänhet att betraktas som en enda artikel.
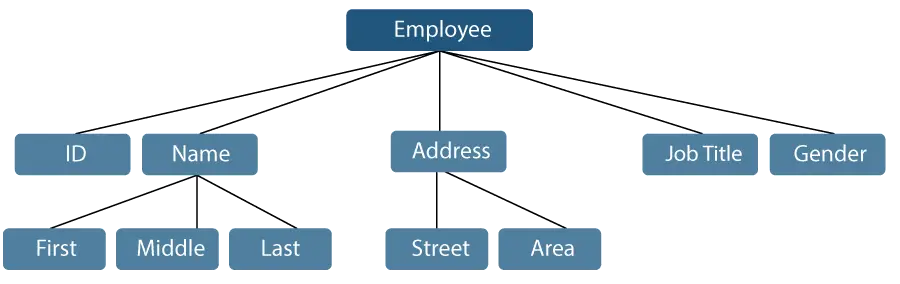
Figur 1: Representation av dataobjekt
I exemplet som nämns ovan är objekten som ID, Ålder, Kön, Första, Mellan, Sist, Gata, Ort, etc. elementära dataobjekt. Däremot är namnet och adressen gruppdataobjekt.
Vad är datastruktur?
Datastruktur är en gren inom datavetenskap. Studiet av datastruktur gör det möjligt för oss att förstå organisationen av data och hanteringen av dataflödet för att öka effektiviteten i varje process eller program. Datastruktur är ett särskilt sätt att lagra och organisera data i datorns minne så att dessa data enkelt kan hämtas och effektivt utnyttjas i framtiden när det behövs. Data kan hanteras på olika sätt, som den logiska eller matematiska modellen för en specifik organisation av data är känd som en datastruktur.
Omfattningen av en viss datamodell beror på två faktorer:
- För det första måste den laddas tillräckligt in i strukturen för att återspegla den definitiva korrelationen mellan data och ett verkligt objekt.
- För det andra bör bildningen vara så enkel att man kan anpassa sig för att behandla data effektivt närhelst det behövs.
Några exempel på datastrukturer är arrayer, länkade listor, stack, kö, träd etc. Datastrukturer används i stor utsträckning i nästan alla aspekter av datavetenskap, t.ex. kompilatordesign, operativsystem, grafik, artificiell intelligens och många fler.
Datastrukturer är huvuddelen av många datavetenskapliga algoritmer eftersom de tillåter programmerare att hantera data på ett effektivt sätt. Det spelar en avgörande roll för att förbättra prestandan för ett program eller mjukvara, eftersom programmets huvudsakliga syfte är att lagra och hämta användarens data så snabbt som möjligt.
array av strängar i c-programmering
Grundläggande terminologier relaterade till datastrukturer
Datastrukturer är byggstenarna i alla program eller program. Att välja lämplig datastruktur för ett program är en extremt utmanande uppgift för en programmerare.
Följande är några grundläggande terminologier som används närhelst datastrukturerna är inblandade:
| Attribut | ID | namn | Kön | Jobbtitel |
|---|---|---|---|---|
| Värderingar | 1234 | Stacey M. Hill | Kvinna | Mjukvaruutvecklare |
Enheter med liknande attribut bildar en Entitetsuppsättning . Varje attribut för en entitetsuppsättning har ett värdeintervall, uppsättningen av alla möjliga värden som skulle kunna tilldelas det specifika attributet.
Termen 'information' används ibland för data med givna attribut av meningsfull eller bearbetad data.
Förstå behovet av datastrukturer
Eftersom applikationer blir mer komplexa och mängden data ökar varje dag, vilket kan leda till problem med datasökning, bearbetningshastighet, hantering av flera förfrågningar och många fler. Datastrukturer stöder olika metoder för att organisera, hantera och lagra data effektivt. Med hjälp av Data Structures kan vi enkelt gå igenom dataposterna. Datastrukturer ger effektivitet, återanvändbarhet och abstraktion.
Varför ska vi lära oss datastrukturer?
- Datastrukturer och algoritmer är två av nyckelaspekterna inom datavetenskap.
- Datastrukturer tillåter oss att organisera och lagra data, medan algoritmer tillåter oss att bearbeta dessa data på ett meningsfullt sätt.
- Att lära oss datastrukturer och algoritmer kommer att hjälpa oss att bli bättre programmerare.
- Vi kommer att kunna skriva kod som är mer effektiv och tillförlitlig.
- Vi kommer också att kunna lösa problem snabbare och mer effektivt.
Förstå målen för datastrukturer
Datastrukturer uppfyller två kompletterande mål:
Förstå några nyckelfunktioner i datastrukturer
Några av de viktiga egenskaperna hos datastrukturer är:
Klassificering av datastrukturer
En datastruktur levererar en strukturerad uppsättning variabler relaterade till varandra på olika sätt. Den utgör grunden för ett programmeringsverktyg som anger förhållandet mellan dataelementen och låter programmerare bearbeta data effektivt.
java sträng till heltalskonvertering
Vi kan klassificera datastrukturer i två kategorier:
- Primitiv datastruktur
- Icke-primitiv datastruktur
Följande figur visar de olika klassificeringarna av datastrukturer.

Figur 2: Klassificeringar av datastrukturer
Primitiva datastrukturer
- Dessa datastrukturer kan manipuleras eller styras direkt av instruktioner på maskinnivå.
- Grundläggande datatyper som Heltal, Flytande, Karaktär , och Boolean kommer under de primitiva datastrukturerna.
- Dessa datatyper kallas också Enkla datatyper , eftersom de innehåller tecken som inte kan delas upp ytterligare
Icke-primitiva datastrukturer
- Dessa datastrukturer kan inte manipuleras eller styras direkt av instruktioner på maskinnivå.
- Fokus för dessa datastrukturer är att bilda en uppsättning dataelement som är antingen homogen (samma datatyp) eller heterogen (olika datatyper).
- Baserat på strukturen och arrangemanget av data kan vi dela in dessa datastrukturer i två underkategorier -
- Linjära datastrukturer
- Icke-linjära datastrukturer
Linjära datastrukturer
En datastruktur som bevarar en linjär koppling mellan dess dataelement kallas en linjär datastruktur. Arrangemanget av data görs linjärt, där varje element består av efterföljare och föregångare förutom det första och det sista dataelementet. Det är dock inte nödvändigtvis sant i fallet med minne, eftersom arrangemanget kanske inte är sekventiellt.
Baserat på minnesallokering klassificeras de linjära datastrukturerna ytterligare i två typer:
De Array är det bästa exemplet på den statiska datastrukturen eftersom de har en fast storlek och dess data kan ändras senare.
Länkade listor, stackar , och Svansar är vanliga exempel på dynamiska datastrukturer
Typer av linjära datastrukturer
Följande är listan över linjära datastrukturer som vi vanligtvis använder:
1. Matriser
En Array är en datastruktur som används för att samla in flera dataelement av samma datatyp till en variabel. Istället för att lagra flera värden av samma datatyper i separata variabelnamn, kan vi lagra dem alla tillsammans till en variabel. Detta uttalande innebär inte att vi kommer att behöva förena alla värden av samma datatyp i något program till en array av den datatypen. Men det kommer ofta att finnas tillfällen då vissa specifika variabler av samma datatyper alla är relaterade till varandra på ett sätt som är lämpligt för en array.
En Array är en lista med element där varje element har en unik plats i listan. Dataelementen i arrayen delar samma variabelnamn; var och en har dock ett olika indexnummer som kallas en sänkning. Vi kan komma åt vilket dataelement som helst från listan med hjälp av dess plats i listan. Sålunda är nyckelegenskapen hos arrayerna att förstå att data lagras i angränsande minnesplatser, vilket gör det möjligt för användarna att gå igenom dataelementen i arrayen med deras respektive index.

Figur 3. En Array
Arrayer kan klassificeras i olika typer:
Några tillämpningar av Array:
- Vi kan lagra en lista över dataelement som tillhör samma datatyp.
- Array fungerar som en extra lagring för andra datastrukturer.
- Arrayen hjälper också till att lagra dataelement i ett binärt träd med det fasta antalet.
- Array fungerar också som en lagring av matriser.
2. Länkade listor
ordning efter slumpmässig sql
A Länkad lista är ett annat exempel på en linjär datastruktur som används för att lagra en samling dataelement dynamiskt. Dataelement i denna datastruktur representeras av noderna, anslutna med länkar eller pekare. Varje nod innehåller två fält, informationsfältet består av faktiska data och pekfältet består av adressen till de efterföljande noderna i listan. Pekaren för den sista noden i den länkade listan består av en nollpekare, eftersom den pekar på ingenting. Till skillnad från Arrays kan användaren dynamiskt justera storleken på en länkad lista enligt kraven.

Figur 4. En länkad lista
Länkade listor kan klassificeras i olika typer:
Några tillämpningar av länkade listor:
- De länkade listorna hjälper oss att implementera stackar, köer, binära träd och grafer av fördefinierad storlek.
- Vi kan även implementera Operativsystems funktion för dynamisk minneshantering.
- Länkade listor tillåter också polynomimplementering för matematiska operationer.
- Vi kan använda Circular Linked List för att implementera operativsystem eller applikationsfunktioner som Round Robin utför uppgifter.
- Cirkulär länkad lista är också användbart i ett bildspel där en användare måste gå tillbaka till den första bilden efter att den sista bilden har presenterats.
- Dubbellänkad lista används för att implementera framåt- och bakåtknappar i en webbläsare för att flytta framåt och bakåt på de öppna sidorna på en webbplats.
3. Stackar
A Stack är en linjär datastruktur som följer LIFO (Sist in, först ut) princip som tillåter operationer som infogning och radering från ena änden av stacken, dvs. Top. Stackar kan implementeras med hjälp av angränsande minne, en Array och icke-angränsande minne, en länkad lista. Verkliga exempel på högar är högar med böcker, en kortlek, högar med pengar och många fler.

Figur 5. Ett verkligt exempel på Stack
Ovanstående figur representerar det verkliga exemplet på en stapel där operationerna endast utförs från ena änden, som att infoga och ta bort nya böcker från toppen av stapeln. Det innebär att infogning och borttagning i stacken endast kan göras från toppen av stapeln. Vi kan bara komma åt stackens toppar vid varje given tidpunkt.
De primära operationerna i stacken är följande:

Bild 6. En stack
Några tillämpningar av stackar:
- Stacken används som en tillfällig lagringsstruktur för rekursiva operationer.
- Stack används också som Auxiliary Storage Structure för funktionsanrop, kapslade operationer och uppskjutna/uppskjutna funktioner.
- Vi kan hantera funktionsanrop med hjälp av Stacks.
- Stackar används också för att utvärdera aritmetiska uttryck i olika programmeringsspråk.
- Stackar är också användbara för att konvertera infix-uttryck till postfix-uttryck.
- Stackar tillåter oss att kontrollera uttryckets syntax i programmeringsmiljön.
- Vi kan matcha parenteser med Stacks.
- Stackar kan användas för att vända en sträng.
- Stackar är till hjälp för att lösa problem baserat på backtracking.
- Vi kan använda Stacks i djup-först-sökning i grafer och trädgenomgång.
- Stackar används också i operativsystemets funktioner.
- Stackar används också i UNDO- och REDO-funktionerna i en redigering.
4. Svansar
A Kö är en linjär datastruktur som liknar en Stack med vissa begränsningar när det gäller infogning och borttagning av elementen. Infogningen av ett element i en kö görs i ena änden, och borttagningen görs i en annan eller motsatt ände. Således kan vi dra slutsatsen att ködatastrukturen följer FIFO-principen (First In, First Out) för att manipulera dataelementen. Implementering av köer kan göras med hjälp av Arrays, Linked Lists eller Stacks. Några verkliga exempel på köer är en kö vid biljettdisken, en rulltrappa, en biltvätt och många fler.

Bild 7. Ett verkligt exempel på kö
Bilden ovan är en verklig illustration av en biobiljettdisk som kan hjälpa oss att förstå Kön där kunden som kommer först alltid serveras först. Kunden som kommer sist kommer utan tvekan att betjänas sist. Båda ändarna av kön är öppna och kan utföra olika operationer. Ett annat exempel är en food court-linje där kunden sätts in från den bakre änden medan kunden tas bort i fronten efter att ha tillhandahållit den service de efterfrågade.
Följande är de primära operationerna för kön:

Figur 8. Kö
Några tillämpningar av köer:
- Köer används vanligtvis i breddsökningsoperationen i Graphs.
- Köer används också i Job Scheduler Operations of Operating Systems, som en tangentbordsbuffertkö för att lagra de tangenter som användarna trycker på och en utskriftsbuffertkö för att lagra de dokument som skrivs ut av skrivaren.
- Köer ansvarar för CPU-schemaläggning, jobbschemaläggning och diskschemaläggning.
- Prioritetsköer används vid filnedladdning i en webbläsare.
- Köer används också för att överföra data mellan kringutrustning och CPU.
- Köer är också ansvariga för att hantera avbrott som genereras av användarapplikationerna för CPU:n.
Icke-linjära datastrukturer
Icke-linjära datastrukturer är datastrukturer där dataelementen inte är ordnade i sekventiell ordning. Här är det inte möjligt att infoga och ta bort data på ett linjärt sätt. Det finns ett hierarkiskt förhållande mellan de enskilda dataposterna.
Typer av icke-linjära datastrukturer
Följande är listan över icke-linjära datastrukturer som vi vanligtvis använder:
1. Träd
Ett träd är en icke-linjär datastruktur och en hierarki som innehåller en samling noder så att varje nod i trädet lagrar ett värde och en lista med referenser till andra noder ('barnen').
Träddatastrukturen är en specialiserad metod för att ordna och samla in data i datorn för att kunna användas mer effektivt. Den innehåller en central nod, strukturella noder och subnoder anslutna via kanter. Vi kan också säga att träddatastrukturen består av rötter, grenar och löv kopplade.

Bild 9. Ett träd
hur man hittar blockerade nummer på Android
Träd kan delas in i olika typer:
Några tillämpningar av träd:
- Träd implementerar hierarkiska strukturer i datorsystem som kataloger och filsystem.
- Träd används också för att implementera navigeringsstrukturen på en webbplats.
- Vi kan generera kod som Huffmans kod med hjälp av Trees.
- Träd är också användbara vid beslutsfattande i spelapplikationer.
- Träd är ansvariga för att implementera prioritetsköer för prioritetsbaserade OS-schemaläggningsfunktioner.
- Träd är också ansvariga för att analysera uttryck och satser i kompilatorerna för olika programmeringsspråk.
- Vi kan använda träd för att lagra datanycklar för indexering för Database Management System (DBMS).
- Spanning Trees tillåter oss att dirigera beslut i dator- och kommunikationsnätverk.
- Träd används också i sökvägsalgoritmen som implementeras i applikationer för artificiell intelligens (AI), robotik och videospel.
2. Grafer
En graf är ett annat exempel på en icke-linjär datastruktur som omfattar ett ändligt antal noder eller hörn och kanterna som förbinder dem. Graferna används för att ta itu med problem i den verkliga världen där det betecknar problemområdet som ett nätverk såsom sociala nätverk, kretsnätverk och telefonnätverk. Till exempel kan noderna eller hörnen i en graf representera en enskild användare i ett telefonnät, medan kanterna representerar länken mellan dem via telefon.
Grafdatastrukturen, G anses vara en matematisk struktur som består av en uppsättning hörn, V och en uppsättning kanter, E som visas nedan:
G = (V,E)

Bild 10. En graf
Ovanstående figur representerar en graf med sju hörn A, B, C, D, E, F, G och tio kanter [A, B], [A, C], [B, C], [B, D], [B, E], [C, D], [D, E], [D, F], [E, F] och [E, G].
Beroende på positionen för hörn och kanter kan graferna klassificeras i olika typer:
Några tillämpningar av grafer:
- Grafer hjälper oss att representera rutter och nätverk i transport-, resor- och kommunikationsapplikationer.
- Grafer används för att visa rutter i GPS.
- Grafer hjälper oss också att representera sammankopplingarna i sociala nätverk och andra nätverksbaserade applikationer.
- Grafer används i kartapplikationer.
- Grafer är ansvariga för representationen av användarnas preferenser i e-handelsapplikationer.
- Grafer används också i Utility-nätverk för att identifiera de problem som uppstår för lokala eller kommunala företag.
- Grafer hjälper också till att hantera användningen och tillgängligheten av resurser i en organisation.
- Grafer används också för att göra dokumentlänkskartor över webbplatserna för att visa kopplingen mellan sidorna genom hyperlänkar.
- Grafer används också i robotrörelser och neurala nätverk.
Grundläggande funktioner för datastrukturer
I följande avsnitt kommer vi att diskutera de olika typerna av operationer som vi kan utföra för att manipulera data i varje datastruktur:
- Kompileringstid
- Körning
Till exempel malloc() funktion används i C Language för att skapa datastruktur.
Förstå den abstrakta datatypen
Enligt National Institute of Standards and Technology (NIST) , är en datastruktur ett arrangemang av information, vanligtvis i minnet, för bättre algoritmeffektivitet. Datastrukturer inkluderar länkade listor, stackar, köer, träd och ordböcker. De kan också vara en teoretisk enhet, som namn och adress på en person.
Från definitionen som nämns ovan kan vi dra slutsatsen att operationerna i datastrukturen inkluderar:
- En hög nivå av abstraktioner som tillägg eller radering av ett objekt från en lista.
- Söka och sortera ett objekt i en lista.
- Åtkomst till objektet med högst prioritet i en lista.
Närhelst datastrukturen utför sådana operationer är det känt som en Abstrakt datatyp (ADT) .
handledning för javascript
Vi kan definiera det som en uppsättning dataelement tillsammans med operationerna på datan. Termen 'abstrakt' hänvisar till det faktum att data och de grundläggande operationerna som definieras på dem studeras oberoende av deras implementering. Det inkluderar vad vi kan göra med datan, inte hur vi kan göra det.
En ADI-implementering innehåller en lagringsstruktur för att lagra dataelement och algoritmer för grundläggande drift. Alla datastrukturer, som en array, länkad lista, kö, stack, etc., är exempel på ADT.
Förstå fördelarna med att använda ADT
I den verkliga världen utvecklas program som en konsekvens av nya begränsningar eller krav, så att modifiera ett program kräver i allmänhet en förändring i en eller flera datastrukturer. Anta till exempel att vi vill infoga ett nytt fält i en anställds register för att hålla reda på mer information om varje anställd. I så fall kan vi förbättra programmets effektivitet genom att ersätta en Array med en länkad struktur. I en sådan situation är det olämpligt att skriva om varje procedur som använder den modifierade strukturen. Därför är ett bättre alternativ att separera en datastruktur från dess implementeringsinformation. Detta är principen bakom användningen av abstrakta datatyper (ADT).
Vissa tillämpningar av datastrukturer
Följande är några tillämpningar av datastrukturer:
- Datastrukturer hjälper till att organisera data i en dators minne.
- Datastrukturer hjälper också till att representera informationen i databaser.
- Data Structures tillåter implementering av algoritmer för att söka igenom data (till exempel sökmotor).
- Vi kan använda datastrukturerna för att implementera algoritmerna för att manipulera data (till exempel ordbehandlare).
- Vi kan också implementera algoritmerna för att analysera data med hjälp av datastrukturer (till exempel dataminers).
- Datastrukturer stöder algoritmer för att generera data (till exempel en slumptalsgenerator).
- Datastrukturer stöder också algoritmer för att komprimera och dekomprimera data (till exempel ett zip-verktyg).
- Vi kan också använda datastrukturer för att implementera algoritmer för att kryptera och dekryptera data (till exempel ett säkerhetssystem).
- Med hjälp av Data Structures kan vi bygga mjukvara som kan hantera filer och kataloger (T.ex. en filhanterare).
- Vi kan också utveckla mjukvara som kan rendera grafik med hjälp av Data Structures. (Till exempel en webbläsare eller programvara för 3D-rendering).
Förutom de, som tidigare nämnts, finns det många andra applikationer av datastrukturer som kan hjälpa oss att bygga vilken mjukvara som helst.