En viktig aspekt av Maskininlärning är modellutvärdering. Du måste ha någon mekanism för att utvärdera din modell. Det är här dessa prestationsmått kommer in i bilden, de ger oss en känsla av hur bra en modell är. Om du är bekant med några av grunderna i Maskininlärning då måste du ha stött på några av dessa mätvärden, som noggrannhet, precision, återkallelse, auc-roc, etc., som vanligtvis används för klassificeringsuppgifter. I den här artikeln kommer vi att undersöka ett sådant mått på djupet, vilket är AUC-ROC-kurvan.
Innehållsförteckning
- Vad är AUC-ROC-kurvan?
- Nyckeltermer som används i AUC och ROC Curve
- Samband mellan känslighet, specificitet, FPR och tröskel.
- Hur fungerar AUC-ROC?
- När ska vi använda AUC-ROC-utvärderingsmåttet?
- Spekulerar modellens prestanda
- Förstå AUC-ROC-kurvan
- Implementering med två olika modeller
- Hur använder man ROC-AUC för en multiklassmodell?
- Vanliga frågor om AUC ROC Curve i maskininlärning
Vad är AUC-ROC-kurvan?
AUC-ROC-kurvan, eller Area Under the Receiver Operation Characteristic-kurva, är en grafisk representation av prestandan hos en binär klassificeringsmodell vid olika klassificeringströsklar. Det används vanligtvis inom maskininlärning för att bedöma förmågan hos en modell att skilja mellan två klasser, vanligtvis den positiva klassen (t.ex. förekomst av en sjukdom) och den negativa klassen (t.ex. frånvaro av en sjukdom).
Låt oss först förstå innebörden av de två termerna ROC och AUC .
- ROC : Mottagarens funktionsegenskaper
- AUC : Area under kurva
Receiver Operating Characteristics (ROC) kurva
ROC står för Receiver Operating Characteristics och ROC-kurvan är den grafiska representationen av effektiviteten hos den binära klassificeringsmodellen. Den plottar den sanna positiva frekvensen (TPR) vs den falska positiva frekvensen (FPR) vid olika klassificeringströsklar.
Område under kurva (AUC) Kurva:
AUC står för Area Under the Curve, och AUC-kurvan representerar arean under ROC-kurvan. Den mäter den övergripande prestandan för den binära klassificeringsmodellen. Eftersom både TPR och FPR sträcker sig mellan 0 till 1, så kommer området alltid att ligga mellan 0 och 1, och ett högre värde på AUC anger bättre modellprestanda. Vårt huvudmål är att maximera detta område för att ha högsta TPR och lägsta FPR vid den givna tröskeln. AUC mäter sannolikheten att modellen kommer att tilldela en slumpmässigt vald positiv instans en högre förutsagd sannolikhet jämfört med en slumpmässigt vald negativ instans.
Den representerar sannolikhet med vilken vår modell kan skilja mellan de två klasserna som finns i vårt mål.
ROC-AUC Klassificering Utvärdering Metrisk
Nyckeltermer som används i AUC och ROC Curve
1. TPR och FPR
Detta är den vanligaste definitionen som du skulle ha stött på när du skulle Google AUC-ROC. I grund och botten är ROC-kurvan en graf som visar prestandan för en klassificeringsmodell vid alla möjliga tröskelvärden (tröskelvärde är ett visst värde bortom vilket du säger att en punkt tillhör en viss klass). Kurvan plottas mellan två parametrar
- TPR – Sann positiv kurs
- FPR – Falsk positiv frekvens
Innan vi förstår, låt TPR och FPR oss snabbt titta på förvirringsmatris .
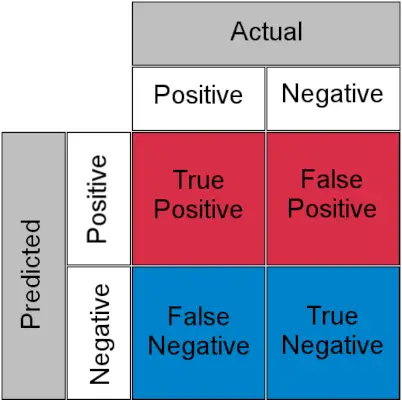
Förvirringsmatris för en klassificeringsuppgift
- Riktigt positiv : Faktisk positiv och förutspådd som positiv
- Riktigt negativ : Faktisk negativ och förutspådd som negativ
- Falskt positivt (Typ I-fel) : Faktisk negativ men förutspådd som positiv
- Falskt negativt (Typ II-fel) : Faktiskt positiv men förutspådd som negativ
Enkelt uttryckt kan du kalla False Positive a falskt alarm och Falskt negativ a Fröken . Låt oss nu titta på vad TPR och FPR är.
2. Känslighet / Sant positiv frekvens / Återkallelse
I grund och botten är TPR/Återkallelse/Känslighet förhållandet mellan positiva exempel som är korrekt identifierade. Det representerar modellens förmåga att korrekt identifiera positiva instanser och beräknas enligt följande:

Sensitivity/Recall/TPR mäter andelen faktiska positiva instanser som korrekt identifieras av modellen som positiva.
3. Falsk positiv frekvens
FPR är förhållandet mellan negativa exempel som är felaktigt klassificerade.

4. Specificitet
Specificitet mäter andelen faktiska negativa instanser som korrekt identifieras av modellen som negativa. Det representerar modellens förmåga att korrekt identifiera negativa instanser

Och som sagt tidigare är ROC inget annat än plottet mellan TPR och FPR över alla möjliga trösklar och AUC är hela området under denna ROC-kurva.
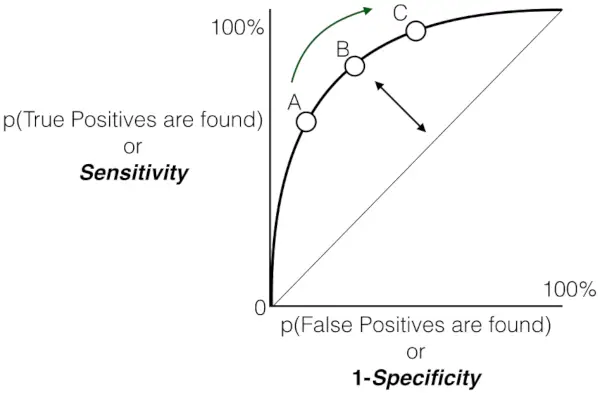
Känslighet kontra falsk positiv frekvens plot
Samband mellan känslighet, specificitet, FPR och tröskel .
Känslighet och specificitet:
- Omvänt förhållande: sensitivitet och specificitet har ett omvänt samband. När den ena ökar, tenderar den andra att minska. Detta återspeglar den inneboende avvägningen mellan verkliga positiva och verkliga negativa kurser.
- Inställning via tröskel: Genom att justera tröskelvärdet kan vi kontrollera balansen mellan sensitivitet och specificitet. Lägre trösklar leder till högre sensitivitet (mer sanna positiva) på bekostnad av specificitet (mer falska positiva). Omvänt, en höjning av tröskeln ökar specificiteten (färre falskt positiva) men offrar känsligheten (fler falskt negativa).
Tröskelvärde och falsk positiv frekvens (FPR):
- FPR och specificitetsanslutning: Falskt positiv frekvens (FPR) är helt enkelt komplementet till specificitet (FPR = 1 – specificitet). Detta betyder det direkta förhållandet mellan dem: högre specificitet översätts till lägre FPR och vice versa.
- FPR-ändringar med TPR: På samma sätt, som du observerade, är den sanna positiva frekvensen (TPR) och FPR också kopplade. En ökning av TPR (mer sanna positiva) leder i allmänhet till en ökning av FPR (mer falska positiva). Omvänt resulterar en minskning av TPR (färre sanna positiva) i en minskning av FPR (färre falska positiva)
Hur fungerar AUC-ROC?
Vi tittade på den geometriska tolkningen, men jag antar att det fortfarande inte räcker för att utveckla intuitionen bakom vad 0,75 AUC faktiskt betyder, låt oss nu titta på AUC-ROC ur en probabilistisk synvinkel. Låt oss först prata om vad AUC gör och senare kommer vi att bygga vår förståelse ovanpå detta
AUC mäter hur väl en modell kan skilja mellan klasser.
En AUC på 0,75 skulle faktiskt betyda att låt oss säga att vi tar två datapunkter som tillhör separata klasser, då är det en 75 % chans att modellen skulle kunna separera dem eller rangordna dem korrekt, dvs. positiv punkt har en högre förutsägelsesannolikhet än den negativa klass. (om man antar en högre förutsägelsesannolikhet betyder det att punkten helst skulle tillhöra den positiva klassen). Här är ett litet exempel för att göra saker tydligare.
Index | Klass | Sannolikhet |
|---|---|---|
P1 | 1 | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Här har vi 6 punkter där P1, P2 och P5 tillhör klass 1 och P3, P4 och P6 tillhör klass 0 och vi är motsvarande förutsagda sannolikheter i sannolikhetskolumnen, som vi sa om vi tar två punkter som hör till separata klasser vad är då sannolikheten för att modellen rangordnar dem korrekt.
Vi kommer att ta alla möjliga par så att en poäng tillhör klass 1 och den andra tillhör klass 0, vi kommer att ha totalt 9 sådana par nedan är alla dessa 9 möjliga par.
Par | stämmer |
|---|---|
(P1,P3) | Ja |
(P1,P4) | Ja |
(P1,P6) | Ja |
(P2,P3) | Ja |
(P2,P4) | Ja |
(P2,P6) | Ja |
(P3,P5) | Nej |
(P4,P5) | Nej |
(P5,P6) | Ja |
Här kolumn är Korrekt berättar om det nämnda paret är korrekt rangordnat baserat på den förutsagda sannolikheten, dvs klass 1 poäng har högre sannolikhet än klass 0 poäng, i 7 av dessa 9 möjliga par är klass 1 rankad högre än klass 0, eller vi kan säga att det finns en 77% chans att om du väljer ett par poäng som tillhör separata klasser skulle modellen kunna särskilja dem korrekt. Nu tror jag att du kanske har lite intuition bakom detta AUC-nummer, bara för att reda ut ytterligare tvivel, låt oss validera det med Scikit lär sig AUC-ROC-implementering.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Produktion:
AUC for our sample data is 0.778>
När ska vi använda AUC-ROC-utvärderingsmåttet?
Det finns vissa områden där användning av ROC-AUC kanske inte är idealisk. I fall där datasetet är mycket obalanserat, ROC-kurvan kan ge en alltför optimistisk bedömning av modellens prestanda . Denna optimismbias uppstår eftersom ROC-kurvans falska positiva frekvens (FPR) kan bli mycket liten när antalet faktiska negativa är stort.
Om man tittar på FPR-formeln,

k-nn algoritm
vi observerar ,
- Den negativa klassen är i majoritet, nämnaren för FPR domineras av sanna negativa, på grund av vilka FPR blir mindre känslig för förändringar i förutsägelser relaterade till minoritetsklassen (positiv klass).
- ROC-kurvor kan vara lämpliga när kostnaden för falska positiva och falska negativa är balanserade och datauppsättningen inte är kraftigt obalanserad.
I så fall, Precision-Recall Curves kan användas som ger ett alternativt utvärderingsmått som är mer lämpligt för obalanserade datamängder, med fokus på klassificerarens prestanda med avseende på den positiva (minoritets)klassen.
Spekulerar modellens prestanda
- En hög AUC (nära 1) indikerar utmärkt särskiljningsförmåga. Detta innebär att modellen är effektiv för att skilja mellan de två klasserna, och dess förutsägelser är tillförlitliga.
- En låg AUC (nära 0) tyder på dålig prestanda. I det här fallet kämpar modellen för att skilja mellan positiva och negativa klasser, och dess förutsägelser kanske inte är tillförlitliga.
- AUC runt 0,5 antyder att modellen i huvudsak gör slumpmässiga gissningar. Den visar ingen förmåga att separera klasserna, vilket indikerar att modellen inte lär sig några meningsfulla mönster från data.
Förstå AUC-ROC-kurvan
I en ROC-kurva representerar x-axeln typiskt False Positive Rate (FPR), och y-axeln representerar True Positive Rate (TPR), även känd som Sensitivity eller Recall. Så, ett högre x-axelvärde (åt höger) på ROC-kurvan indikerar en högre False Positive Rate, och ett högre y-axelvärde (mot toppen) indikerar en högre True Positive Rate. ROC-kurvan är en grafisk representation av avvägningen mellan sann positiv frekvens och falsk positiv frekvens vid olika trösklar. Den visar prestandan för en klassificeringsmodell vid olika klassificeringströsklar. AUC (Area Under the Curve) är ett sammanfattande mått på ROC-kurvans prestanda. Valet av tröskelvärde beror på de specifika kraven för det problem du försöker lösa och avvägningen mellan falska positiva och falska negativa, dvs. acceptabelt i ditt sammanhang.
- Om du vill prioritera att minska falska positiva resultat (minimera chanserna att märka något som positivt när det inte är det), kan du välja en tröskel som resulterar i en lägre andel falska positiva.
- Om du vill prioritera att öka sann positiv (fånga så många faktiska positiva som möjligt), kan du välja en tröskel som resulterar i en högre sann positiv andel.
Låt oss överväga ett exempel för att illustrera hur ROC-kurvor genereras för olika trösklar och hur en viss tröskel motsvarar en förvirringsmatris. Anta att vi har en problem med binär klassificering med en modell som förutsäger om ett e-postmeddelande är skräppost (positivt) eller inte skräppost (negativt).
Låt oss överväga de hypotetiska uppgifterna,
True Etiketter: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Förutspådda sannolikheter: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Fall 1: Tröskelvärde = 0,5
Sanna etiketter | Förutspådda sannolikheter | Förutspådda etiketter |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Förvirringsmatris baserad på ovanstående förutsägelser
| Förutsägelse = 0 | Förutsägelse = 1 |
|---|---|---|
Faktisk = 0 | TP=4 | FN=1 |
Faktiskt = 1 | FP=0 | TN=5 |
Följaktligen,
- True Positive Rate (TPR) :
Andel faktiska positiva korrekt identifierade av klassificeraren är

- Falskt positiv frekvens (FPR) :
Andel faktiska negativa felaktigt klassificerade som positiva



Så, vid tröskeln 0,5:
- Sann positiv frekvens (känslighet): 0,8
- Falskt positiv frekvens: 0
Tolkningen är att modellen, vid denna tröskel, korrekt identifierar 80 % av faktiska positiva (TPR) men felaktigt klassificerar 0 % av faktiska negativa som positiva (FPR).
Följaktligen får vi för olika trösklar ,
Fall 2: Tröskel = 0,7
Sanna etiketter | Förutspådda sannolikheter | Förutspådda etiketter |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Förvirringsmatris baserad på ovanstående förutsägelser
| Förutsägelse = 0 | Förutsägelse = 1 |
|---|---|---|
Faktisk = 0 | TP=5 | FN=0 |
Faktiskt = 1 | FP=2 | TN=3 |
Följaktligen,
- True Positive Rate (TPR) :
Andel faktiska positiva korrekt identifierade av klassificeraren är

- Falskt positiv frekvens (FPR) :
Andel faktiska negativa felaktigt klassificerade som positiva



Fall 3: Tröskelvärde = 0,4
Sanna etiketter | Förutspådda sannolikheter | Förutspådda etiketter |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Förvirringsmatris baserad på ovanstående förutsägelser
| Förutsägelse = 0 | Förutsägelse = 1 |
|---|---|---|
Faktisk = 0 | TP=4 | FN=1 |
Faktiskt = 1 | FP=0 | TN=5 |
Följaktligen,
- True Positive Rate (TPR) :
Andel faktiska positiva korrekt identifierade av klassificeraren är
- Falskt positiv frekvens (FPR) :
Andel faktiska negativa felaktigt klassificerade som positiva
Fall 4: Tröskelvärde = 0,2
Sanna etiketter | Förutspådda sannolikheter | Förutspådda etiketter |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 1 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 1 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Förvirringsmatris baserad på ovanstående förutsägelser
| Förutsägelse = 0 | Förutsägelse = 1 |
|---|---|---|
Faktisk = 0 | TP=2 | FN=3 |
Faktiskt = 1 | FP=0 | TN=5 |
Följaktligen,
- True Positive Rate (TPR) :
Andel faktiska positiva korrekt identifierade av klassificeraren är

- Falskt positiv frekvens (FPR) :
Andel faktiska negativa felaktigt klassificerade som positiva

Fall 5: Tröskel = 0,85
Sanna etiketter | Förutspådda sannolikheter | Förutspådda etiketter |
|---|---|---|
| 1 | 0,8 | 0 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Förvirringsmatris baserad på ovanstående förutsägelser
| Förutsägelse = 0 | Förutsägelse = 1 |
|---|---|---|
Faktisk = 0 | TP=5 | FN=0 |
Faktiskt = 1 | FP=4 | TN=1 |
Följaktligen,
- True Positive Rate (TPR) :
Andel faktiska positiva korrekt identifierade av klassificeraren är
- Falskt positiv frekvens (FPR) :
Andel faktiska negativa felaktigt klassificerade som positiva


Baserat på ovanstående resultat kommer vi att plotta ROC-kurvan
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Produktion:
Från grafen antyds det att:
- Den grå streckade linjen representerar det värsta scenariot, där modellens förutsägelser, dvs. TPR är FPR, är desamma. Denna diagonala linje anses vara det värsta scenariot, vilket indikerar lika sannolikhet för falska positiva och falska negativa.
- När punkter avviker från den slumpmässiga gissningslinjen mot det övre vänstra hörnet, förbättras modellens prestanda.
- Area Under the Curve (AUC) är ett kvantitativt mått på modellens särskiljande förmåga. Ett högre AUC-värde, närmare 1,0, indikerar överlägsen prestanda. Bästa möjliga AUC-värde är 1,0, vilket motsvarar en modell som uppnår 100 % sensitivitet och 100 % specificitet.
Sammantaget fungerar Receiver Operating Characteristic (ROC)-kurvan som en grafisk representation av avvägningen mellan en binär klassificeringsmodells True Positive Rate (känslighet) och False Positive Rate vid olika beslutströsklar. När kurvan graciöst stiger mot det övre vänstra hörnet, betecknar det modellens lovvärda förmåga att skilja mellan positiva och negativa instanser över en rad konfidensgränser. Denna uppåtgående bana indikerar en förbättrad prestanda, med högre känslighet uppnådd samtidigt som falska positiva resultat minimeras. De kommenterade tröskelvärdena, betecknade som A, B, C, D och E, ger värdefulla insikter om modellens dynamiska beteende på olika konfidensnivåer.
Implementering med två olika modeller
Installera bibliotek
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
För att träna Random Forest och Logistisk tillbakagång modeller och för att presentera sina ROC-kurvor med AUC-poäng, skapar algoritmen artificiell binär klassificeringsdata.
Generera data och dela upp data
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Med hjälp av ett delat förhållande på 80-20 skapar algoritmen artificiell binär klassificeringsdata med 20 funktioner, delar upp den i tränings- och testuppsättningar och tilldelar ett slumpmässigt frö för att säkerställa reproducerbarhet.
Tränar de olika modellerna
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Med hjälp av ett fast slumpmässigt frö för att säkerställa repeterbarhet, initierar och tränar metoden en logistisk regressionsmodell på träningssetet. På liknande sätt använder den träningsdata och samma slumpmässiga frö för att initiera och träna en Random Forest-modell med 100 träd.
Förutsägelser
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Med hjälp av testdata och en utbildad Logistisk tillbakagång modell förutsäger koden den positiva klassens sannolikhet. På ett liknande sätt, med hjälp av testdata, använder den den tränade Random Forest-modellen för att producera projicerade sannolikheter för den positiva klassen.
Skapa en dataram
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Med hjälp av testdata skapar koden en DataFrame som heter test_df med kolumner märkta True, Logistic och RandomForest, och lägger till sanna etiketter och förutspådda sannolikheter från Random Forest och Logistic Regression-modellerna.
Rita upp ROC-kurvan för modellerna
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Produktion:

Koden genererar en plot med 8 x 6 tums figurer. Den beräknar AUC- och ROC-kurvan för varje modell (Random Forest and Logistic Regression), och plottar sedan ROC-kurvan. De ROC-kurva för slumpmässig gissning representeras också av en röd streckad linje, och etiketter, en titel och en förklaring är inställda för visualisering.
Hur använder man ROC-AUC för en multiklassmodell?
För en inställning med flera klasser kan vi helt enkelt använda metodiken en mot alla och du kommer att ha en ROC-kurva för varje klass. Låt oss säga att du har fyra klasser A, B, C och D, då skulle det finnas ROC-kurvor och motsvarande AUC-värden för alla de fyra klasserna, dvs. när A en gång skulle vara en klass och B, C och D kombinerade skulle vara de andra klassen. , på samma sätt är B en klass och A, C och D kombinerade som andra klasser osv.
De allmänna stegen för att använda AUC-ROC i samband med en klassificeringsmodell med flera klasser är:
En-mot-alla-metod:
- För varje klass i ditt flerklassproblem, behandla den som den positiva klassen samtidigt som du kombinerar alla andra klasser till den negativa klassen.
- Träna den binära klassificeraren för varje klass mot resten av klasserna.
Beräkna AUC-ROC för varje klass:
- Här plottar vi ROC-kurvan för den givna klassen mot resten.
- Rita ROC-kurvorna för varje klass på samma graf. Varje kurva representerar diskrimineringsprestandan för modellen för en specifik klass.
- Undersök AUC-poängen för varje klass. En högre AUC-poäng indikerar bättre diskriminering för just den klassen.
Implementering av AUC-ROC i Multiclass Classification
Importera bibliotek
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Programmet skapar artificiell multiklassdata, delar upp den i tränings- och testuppsättningar och använder sedan One-vs-Restclassifier teknik för att träna klassificerare för både Random Forest och Logistic Regression. Slutligen plottar den de två modellernas ROC-kurvor i flera klasser för att visa hur väl de skiljer mellan olika klasser.
Generera data och dela upp
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Tre klasser och tjugo funktioner utgör den syntetiska multiklassdata som produceras av koden. Efter etikettbinarisering delas data upp i tränings- och testset i förhållandet 80-20.
Träningsmodeller
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Programmet tränar två multiklassmodeller: en Random Forest-modell med 100 estimatorer och en Logistic Regression-modell med One-vs-Rest-metoden . Med träningsuppsättningen av data är båda modellerna utrustade.
Plotta AUC-ROC-kurvan
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Produktion:

Random Forest och Logistic Regression-modellernas ROC-kurvor och AUC-poäng beräknas av koden för varje klass. ROC-kurvorna med flera klasser plottas sedan och visar diskrimineringsprestandan för varje klass och har en linje som representerar slumpmässig gissning. Den resulterande plotten erbjuder en grafisk utvärdering av modellernas klassificeringsprestanda.
Slutsats
Inom maskininlärning bedöms prestandan hos binära klassificeringsmodeller med hjälp av ett avgörande mått som kallas Area Under the Receiver Operating Characteristic (AUC-ROC). Över olika beslutströsklar visar det hur känslighet och specificitet avvägs. Större diskriminering mellan positiva och negativa instanser uppvisas vanligtvis av en modell med ett högre AUC-poäng. Medan 0,5 anger slump, representerar 1 felfri prestanda. Modelloptimering och val underlättas av den användbara informationen som AUC-ROC-kurvan erbjuder om en modells förmåga att skilja mellan klasser. När man arbetar med obalanserade datamängder eller applikationer där falska positiva och falska negativa har olika kostnader, är det särskilt användbart som en heltäckande åtgärd.
Vanliga frågor om AUC ROC Curve i maskininlärning
1. Vad är AUC-ROC-kurvan?
För olika klassificeringströsklar representeras avvägningen mellan sann positiv frekvens (känslighet) och falsk positiv frekvens (specificitet) grafiskt av AUC-ROC-kurvan.
2. Hur ser en perfekt AUC-ROC-kurva ut?
Ett område på 1 på en idealisk AUC-ROC-kurva skulle innebära att modellen uppnår optimal sensitivitet och specificitet vid alla trösklar.
3. Vad betyder ett AUC-värde på 0,5?
AUC på 0,5 indikerar att modellens prestanda är jämförbar med slumpmässig slump. Det tyder på bristande särskiljningsförmåga.
4. Kan AUC-ROC användas för multiklassklassificering?
AUC-ROC tillämpas ofta på frågor som involverar binär klassificering. Variationer såsom makrogenomsnittet eller mikrogenomsnittet AUC kan tas i beaktande för multiklassklassificering.
5. Hur är AUC-ROC-kurvan användbar vid modellutvärdering?
En modells förmåga att skilja mellan klasser sammanfattas heltäckande av AUC-ROC-kurvan. När du arbetar med obalanserade datauppsättningar är det särskilt användbart.