Logistisk tillbakagång är en övervakad maskininlärningsalgoritm används för klassificeringsuppgifter där målet är att förutsäga sannolikheten att en instans tillhör en given klass eller inte. Logistisk regression är en statistisk algoritm som analyserar sambandet mellan två datafaktorer. Artikeln utforskar grunderna för logistisk regression, dess typer och implementeringar.
Innehållsförteckning
- Vad är logistisk regression?
- Logistisk funktion – Sigmoidfunktion
- Typer av logistisk regression
- Antaganden om logistisk regression
- Hur fungerar logistisk regression?
- Kodimplementering för logistisk regression
- Precision-Recall Tradeoff i logistisk regressionströskelinställning
- Hur utvärderar man logistisk regressionsmodell?
- Skillnader mellan linjär och logistisk regression
Vad är logistisk regression?
Logistisk regression används för binär klassificering där vi använder sigmoid funktion , som tar indata som oberoende variabler och producerar ett sannolikhetsvärde mellan 0 och 1.
Till exempel har vi två klasser klass 0 och klass 1 om värdet på logistikfunktionen för en ingång är större än 0,5 (tröskelvärde) så tillhör den klass 1 annars tillhör den klass 0. Det kallas regression eftersom det är en förlängning av linjär regression men används främst för klassificeringsproblem.
Nyckelord:
- Logistisk regression förutsäger produktionen av en kategoriskt beroende variabel. Därför måste utfallet vara ett kategoriskt eller diskret värde.
- Det kan vara antingen Ja eller Nej, 0 eller 1, sant eller Falskt, etc. men istället för att ge det exakta värdet som 0 och 1, ger det de sannolikhetsvärden som ligger mellan 0 och 1.
- I logistisk regression, istället för att anpassa en regressionslinje, passar vi in en S-formad logistisk funktion, som förutsäger två maximala värden (0 eller 1).
Logistisk funktion – Sigmoidfunktion
- Sigmoidfunktionen är en matematisk funktion som används för att mappa de förutsagda värdena till sannolikheter.
- Den mappar vilket verkligt värde som helst till ett annat värde inom intervallet 0 och 1. Värdet på den logistiska regressionen måste vara mellan 0 och 1, vilket inte kan gå över denna gräns, så det bildar en kurva som S-formen.
- S-formskurvan kallas Sigmoid-funktionen eller logistikfunktionen.
- I logistisk regression använder vi begreppet tröskelvärde, som definierar sannolikheten för antingen 0 eller 1. Som att värden över tröskelvärdet tenderar till 1, och ett värde under tröskelvärdena tenderar till 0.
Typer av logistisk regression
På basis av kategorierna kan logistisk regression klassificeras i tre typer:
- Binom: I binomial logistisk regression kan det bara finnas två möjliga typer av de beroende variablerna, såsom 0 eller 1, Godkänd eller Underkänd, etc.
- Multinomial: I multinomial logistisk regression kan det finnas 3 eller flera möjliga oordnade typer av den beroende variabeln, såsom katt, hund eller får
- Ordinal: I ordinal logistisk regression kan det finnas 3 eller fler möjliga sorterade typer av beroende variabler, såsom låg, medium eller hög.
Antaganden om logistisk regression
Vi kommer att utforska antagandena om logistisk regression eftersom det är viktigt att förstå dessa antaganden för att säkerställa att vi använder lämplig tillämpning av modellen. Antagandet inkluderar:
- Oberoende observationer: Varje observation är oberoende av den andra. vilket betyder att det inte finns någon korrelation mellan några indatavariabler.
- Binära beroende variabler: Det tar antagandet att den beroende variabeln måste vara binär eller dikotom, vilket betyder att den bara kan ta två värden. För mer än två kategorier används SoftMax-funktioner.
- Linjäritetssamband mellan oberoende variabler och logodds: Relationen mellan de oberoende variablerna och logoddsen för den beroende variabeln bör vara linjär.
- Inga extremvärden: Det ska inte finnas några extremvärden i datamängden.
- Stor urvalsstorlek: urvalsstorleken är tillräckligt stor
Terminologier involverade i logistisk regression
Här är några vanliga termer involverade i logistisk regression:
- Oberoende variabler: Indataegenskaperna eller prediktorfaktorerna som tillämpas på den beroende variabelns förutsägelser.
- Beroende variabel: Målvariabeln i en logistisk regressionsmodell, som vi försöker förutsäga.
- Logistisk funktion: Formeln som används för att representera hur de oberoende och beroende variablerna förhåller sig till varandra. Logistikfunktionen omvandlar indatavariablerna till ett sannolikhetsvärde mellan 0 och 1, vilket representerar sannolikheten för att den beroende variabeln är 1 eller 0.
- Odds: Det är förhållandet mellan något som inträffar och något som inte inträffar. det skiljer sig från sannolikhet eftersom sannolikheten är förhållandet mellan något som inträffar och allt som kan tänkas inträffa.
- Log-odds: Log-oddsen, även känd som logit-funktionen, är den naturliga logaritmen för oddsen. Vid logistisk regression modelleras logoddsen för den beroende variabeln som en linjär kombination av de oberoende variablerna och skärningen.
- Koefficient: Den logistiska regressionsmodellens skattade parametrar visar hur de oberoende och beroende variablerna förhåller sig till varandra.
- Genskjuta: En konstant term i den logistiska regressionsmodellen, som representerar logoddsen när alla oberoende variabler är lika med noll.
- Maximal sannolikhetsuppskattning : Metoden som används för att uppskatta koefficienterna för den logistiska regressionsmodellen, vilket maximerar sannolikheten för att observera data givet modellen.
Hur fungerar logistisk regression?
Den logistiska regressionsmodellen transformerar linjär regression funktionskontinuerliga värdeutmatning till kategoriskt värdeutmatning med hjälp av en sigmoid-funktion, som mappar alla verkliga värden av oberoende variabler som matas in till ett värde mellan 0 och 1. Denna funktion är känd som logistikfunktionen.
Låt de oberoende inmatningsfunktionerna vara:
vad är Androids påskägg
och den beroende variabeln är Y som endast har binärt värde, dvs 0 eller 1.
applicera sedan den multilinjära funktionen på indatavariablerna X.
Här
vad vi än diskuterade ovan är linjär regression .
Sigmoid funktion
Nu använder vi sigmoid funktion där ingången blir z och vi hittar sannolikheten mellan 0 och 1. d.v.s. förutspått y.
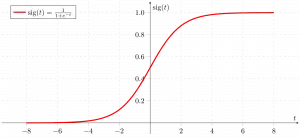
Sigmoid funktion
Som visas ovan konverterar figuren sigmoid-funktionen de kontinuerliga variabla data till sannolikhet dvs mellan 0 och 1.
sigma(z) tenderar mot 1 somz ightarrowinfty sigma(z) tenderar mot 0 somz ightarrow-infty sigma(z) är alltid gränsad mellan 0 och 1
där sannolikheten att vara en klass kan mätas som:
Logistisk regressionsekvation
Det udda är förhållandet mellan något som inträffar och något som inte inträffar. det skiljer sig från sannolikhet eftersom sannolikheten är förhållandet mellan något som inträffar och allt som kan tänkas inträffa. så konstigt blir:
java matte pow
Använder naturlig logga på udda. då blir log udda:
då blir den slutliga logistiska regressionsekvationen:
Sannolikhetsfunktion för logistisk regression
De förutspådda sannolikheterna kommer att vara:
- för y=1 De förutsagda sannolikheterna kommer att vara: p(X;b,w) = p(x)
- för y = 0 De förutsagda sannolikheterna kommer att vara: 1-p(X;b,w) = 1-p(x)
oj koncept
Ta naturliga stockar på båda sidor
Gradient av log-likelihood-funktionen
För att hitta de maximala sannolikhetsuppskattningarna differentierar vi w.r.t.
Kodimplementering för logistisk regression
Binomial logistisk regression:
Målvariabel kan bara ha 2 möjliga typer: 0 eller 1 som kan representera vinst vs förlust, pass vs misslyckande, död vs levande, etc., i detta fall används sigmoidfunktioner, vilket redan diskuterats ovan.
Importera nödvändiga bibliotek baserat på kravet på modell. Denna Python-kod visar hur man använder bröstcancerdataset för att implementera en logistisk regressionsmodell för klassificering.
Python3 # import the necessary libraries from sklearn.datasets import load_breast_cancer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # load the breast cancer dataset X, y = load_breast_cancer(return_X_y=True) # split the train and test dataset X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=23) # LogisticRegression clf = LogisticRegression(random_state=0) clf.fit(X_train, y_train) # Prediction y_pred = clf.predict(X_test) acc = accuracy_score(y_test, y_pred) print('Logistic Regression model accuracy (in %):', acc*100)> Produktion :
Logistisk regressionsmodell noggrannhet (i %): 95,6140350877193
Multinomial logistisk regression:
Målvariabel kan ha 3 eller fler möjliga typer som inte är ordnade (d.v.s. typer har ingen kvantitativ betydelse) som sjukdom A vs sjukdom B vs sjukdom C.
I det här fallet används softmax-funktionen istället för sigmoid-funktionen. Softmax funktion för K-klasser kommer att vara:
Här, K representerar antalet element i vektorn z, och i, j itererar över alla element i vektorn.
Då blir sannolikheten för klass c:
I Multinomial Logistic Regression kan utdatavariabeln ha mer än två möjliga diskreta utgångar . Tänk på sifferdatauppsättningen.
Python3 from sklearn.model_selection import train_test_split from sklearn import datasets, linear_model, metrics # load the digit dataset digits = datasets.load_digits() # defining feature matrix(X) and response vector(y) X = digits.data y = digits.target # splitting X and y into training and testing sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1) # create logistic regression object reg = linear_model.LogisticRegression() # train the model using the training sets reg.fit(X_train, y_train) # making predictions on the testing set y_pred = reg.predict(X_test) # comparing actual response values (y_test) # with predicted response values (y_pred) print('Logistic Regression model accuracy(in %):', metrics.accuracy_score(y_test, y_pred)*100)> Produktion:
Logistisk regressionsmodell noggrannhet (i %): 96,52294853963839
Hur utvärderar man logistisk regressionsmodell?
Vi kan utvärdera den logistiska regressionsmodellen med hjälp av följande mått:
- Noggrannhet: Noggrannhet ger andelen korrekt klassificerade instanser.
Accuracy = frac{True , Positives + True , Negatives}{Total}
- Precision: Precision fokuserar på riktigheten av positiva förutsägelser.
Precision = frac{True , Positives }{True, Positives + False , Positives}
- Återkallelse (känslighet eller sann positiv frekvens): Återkallelse mäter andelen korrekt förutsagda positiva instanser bland alla faktiska positiva instanser.
Recall = frac{ True , Positives}{True, Positives + False , Negatives}
- F1-poäng: F1 poäng är det harmoniska medelvärdet för precision och återkallelse.
F1 , Score = 2 * frac{Precision * Recall}{Precision + Recall}
- Område under mottagarens funktionskarakteristiska kurva (AUC-ROC): ROC-kurvan plottar den sanna positiva frekvensen mot den falska positiva frekvensen vid olika trösklar. AUC-ROC mäter arean under denna kurva, vilket ger ett aggregerat mått på en modells prestanda över olika klassificeringströsklar.
- Area Under the Precision-Recall Curve (AUC-PR): I likhet med AUC-ROC, AUC-PR mäter området under precisions-återkallningskurvan, vilket ger en sammanfattning av en modells prestanda över olika precisions-återkallningsavvägningar.
Precision-Recall Tradeoff i logistisk regressionströskelinställning
Logistisk regression blir en klassificeringsteknik först när en beslutströskel tas in i bilden. Inställningen av tröskelvärdet är en mycket viktig aspekt av logistisk regression och är beroende av själva klassificeringsproblemet.
Beslutet om värdet på tröskelvärdet påverkas till stor del av värdena på precision och återkallelse. Helst vill vi att både precision och återkallelse ska vara 1, men så är sällan fallet.
I fallet med en Avvägning mellan precision och återkallelse , använder vi följande argument för att besluta om tröskeln:
- Låg precision/högt återkallande: I applikationer där vi vill minska antalet falska negativa utan att nödvändigtvis minska antalet falska positiva, väljer vi ett beslutsvärde som har ett lågt värde på Precision eller ett högt värde på Recall. I en ansökan om cancerdiagnostik vill vi till exempel inte att någon drabbad patient ska klassificeras som icke-drabbad utan att särskilt uppmärksamma om patienten felaktigt får diagnosen cancer. Detta beror på att frånvaron av cancer kan upptäckas av ytterligare medicinska sjukdomar, men förekomsten av sjukdomen kan inte upptäckas hos en redan avvisad kandidat.
- Hög precision/lågt återkallande: I applikationer där vi vill minska antalet falska positiva utan att nödvändigtvis minska antalet falska negativa, väljer vi ett beslutsvärde som har ett högt värde på Precision eller ett lågt värde på Recall. Om vi till exempel klassificerar kunder om de kommer att reagera positivt eller negativt på en personlig annons, vill vi vara helt säkra på att kunden kommer att reagera positivt på annonsen, eftersom en negativ reaktion annars kan leda till en förlust av potentiell försäljning från kund.
Skillnader mellan linjär och logistisk regression
Skillnaden mellan linjär regression och logistisk regression är att linjär regression är det kontinuerliga värdet som kan vara vad som helst medan logistisk regression förutsäger sannolikheten att en instans tillhör en given klass eller inte.
imessage-spel på Android
Linjär regression | Logistisk tillbakagång |
|---|---|
Linjär regression används för att förutsäga den kontinuerliga beroende variabeln med hjälp av en given uppsättning oberoende variabler. | Logistisk regression används för att förutsäga den kategoriskt beroende variabeln med hjälp av en given uppsättning oberoende variabler. |
Linjär regression används för att lösa regressionsproblem. | Det används för att lösa klassificeringsproblem. |
I detta förutsäger vi värdet av kontinuerliga variabler | I detta förutsäger vi värden på kategoriska variabler |
I denna hittar vi bäst passform linje. | I denna hittar vi S-kurva. |
Minsta kvadratuppskattningsmetod används för uppskattning av noggrannhet. | Maximal likelihood-uppskattningsmetod används för uppskattning av noggrannhet. |
Utgången måste vara kontinuerligt värde, såsom pris, ålder, etc. | Utdata måste vara kategoriskt värde som 0 eller 1, Ja eller nej, etc. konvertering av int till sträng i java |
Det krävde linjärt samband mellan beroende och oberoende variabler. | Det krävde inte linjärt samband. |
Det kan finnas kolinearitet mellan de oberoende variablerna. | Det bör inte finnas kolinearitet mellan oberoende variabler. |
Logistisk regression – Vanliga frågor (FAQs)
Vad är logistisk regression i maskininlärning?
Logistisk regression är en statistisk metod för att utveckla maskininlärningsmodeller med binärt beroende variabler, dvs binära. Logistisk regression är en statistisk teknik som används för att beskriva data och sambandet mellan en beroende variabel och en eller flera oberoende variabler.
Vilka är de tre typerna av logistisk regression?
Logistisk regression klassificeras i tre typer: binär, multinomial och ordinal. De skiljer sig åt i utförande såväl som teori. Binär regression handlar om två möjliga utfall: ja eller nej. Multinomial logistisk regression används när det finns tre eller fler värden.
Varför används logistisk regression för klassificeringsproblem?
Logistisk regression är lättare att implementera, tolka och träna. Den klassificerar okända poster mycket snabbt. När datasetet är linjärt separerbart fungerar det bra. Modellkoefficienter kan tolkas som indikatorer av funktionsviktighet.
Vad skiljer logistisk regression från linjär regression?
Medan linjär regression används för att förutsäga kontinuerliga utfall, används logistisk regression för att förutsäga sannolikheten för att en observation faller inom en specifik kategori. Logistic Regression använder en S-formad logistisk funktion för att kartlägga förutsagda värden mellan 0 och 1.
Vilken roll spelar logistikfunktionen i logistisk regression?
Logistisk regression förlitar sig på den logistiska funktionen för att omvandla resultatet till ett sannolikhetspoäng. Denna poäng representerar sannolikheten att en observation tillhör en viss klass. Den S-formade kurvan hjälper till att tröskelvärda och kategorisera data i binära utfall.