BERT, en akronym för dubbelriktade kodarrepresentationer från Transformers , står som en öppen källkod ramverk för maskininlärning designad för riket av naturlig språkbehandling (NLP) . Detta ramverk har sitt ursprung i 2018 och skapades av forskare från Google AI Language. Artikeln syftar till att utforska arkitektur, arbete och tillämpningar av BERT .
Vad är BERT?
BERT (Bidirectional Encoder Representations from Transformers) utnyttjar ett transformatorbaserat neuralt nätverk för att förstå och generera mänskligt språk. BERT använder en encoder-enbart arkitektur. I den ursprungliga Transformatorarkitektur , det finns både kodnings- och avkodarmoduler. Beslutet att använda en kodare-enbart arkitektur i BERT föreslår en primär betoning på att förstå ingångssekvenser snarare än att generera utdatasekvenser.
Dubbelriktad strategi för BERT
Traditionella språkmodeller bearbetar text sekventiellt, antingen från vänster till höger eller höger till vänster. Denna metod begränsar modellens medvetenhet till det omedelbara sammanhanget som föregår målordet. BERT använder ett dubbelriktat tillvägagångssätt som tar hänsyn till både vänster och höger kontext av ord i en mening, istället för att analysera texten sekventiellt, tittar BERT på alla ord i en mening samtidigt.
Exempel: Banken är belägen på _______ av floden.
I en enkelriktad modell skulle förståelsen av blanketten i hög grad bero på de föregående orden, och modellen kan ha svårt att avgöra om banken syftar på en finansiell institution eller sidan av floden.
BERT, som är dubbelriktad, betraktar samtidigt både vänster (banken ligger på) och höger kontext (av floden), vilket möjliggör en mer nyanserad förståelse. Den förstår att det saknade ordet sannolikt är relaterat till bankens geografiska läge, vilket visar den kontextuella rikedom som det dubbelriktade tillvägagångssättet ger.
Förträning och finjustering
BERT-modellen genomgår en process i två steg:
- Förträning i stora mängder omärkt text för att lära dig kontextuella inbäddningar.
- Finjustering av märkt data för specifik NLP uppgifter.
Förutbildning om stora data
- BERT är förtränad på stora mängder omärkt textdata. Modellen lär sig kontextuella inbäddningar, som är representationer av ord som tar hänsyn till deras omgivande sammanhang i en mening.
- BERT ägnar sig åt olika oövervakade förträningsuppgifter. Det kan till exempel lära sig att förutsäga saknade ord i en mening (Masked Language Model eller MLM-uppgift), förstå sambandet mellan två meningar eller förutsäga nästa mening i ett par.
Finjustering av märkta data
- Efter förträningsfasen finjusteras BERT-modellen, utrustad med dess kontextuella inbäddningar, för specifika NLP-uppgifter (natural language processing). Detta steg skräddarsyr modellen för mer riktade tillämpningar genom att anpassa dess allmänna språkförståelse till nyanserna i den specifika uppgiften.
- BERT finjusteras med hjälp av märkta data som är specifika för nedströmsuppgifterna av intresse. Dessa uppgifter kan inkludera sentimentanalys, frågesvar, namngiven enhetserkännande , eller någon annan NLP-applikation. Modellens parametrar justeras för att optimera dess prestanda för de specifika kraven för den aktuella uppgiften.
BERT:s enhetliga arkitektur gör att den kan anpassa sig till olika nedströmsuppgifter med minimala ändringar, vilket gör den till ett mångsidigt och mycket effektivt verktyg i naturlig språkförståelse och bearbetning.
Hur fungerar BERT?
BERT är designat för att generera en språkmodell så endast kodningsmekanismen används. Sekvens av tokens matas till Transformer-kodaren. Dessa tokens bäddas först in i vektorer och bearbetas sedan i det neurala nätverket. Utsignalen är en sekvens av vektorer, som var och en motsvarar en inmatningstoken, som tillhandahåller kontextualiserade representationer.
När man tränar språkmodeller är det en utmaning att definiera ett prediktionsmål. Många modeller förutsäger nästa ord i en sekvens, vilket är ett riktat tillvägagångssätt och kan begränsa kontextinlärning. BERT tar sig an denna utmaning med två innovativa utbildningsstrategier:
- Maskerad språkmodell (MLM)
- Förutsägelse av nästa mening (NSP)
1. Maskerad språkmodell (MLM)
I BERT:s förträningsprocess maskeras en del av orden i varje inmatningssekvens och modellen tränas att förutsäga de ursprungliga värdena för dessa maskerade ord baserat på det sammanhang som de omgivande orden ger.
I enkla termer,
- Maskeringsord: Innan BERT lär sig av meningar döljer den några ord (cirka 15%) och ersätter dem med en speciell symbol, som [MASK].
- Gissa dolda ord: BERT:s uppgift är att ta reda på vad dessa dolda ord är genom att titta på orden runt dem. Det är som ett spel att gissa där några ord saknas, och BERT försöker fylla i tomrummen.
- Hur BERT lär sig:
- BERT lägger till ett speciellt lager ovanpå sitt inlärningssystem för att göra dessa gissningar. Den kontrollerar sedan hur nära dess gissningar är de faktiska dolda orden.
- Den gör detta genom att omvandla sina gissningar till sannolikheter och säga, jag tror att det här ordet är X, och jag är så säker på det.
- Särskild uppmärksamhet på dolda ord
- BERT:s huvudfokus under träningen är att få dessa dolda ord rätt. Den bryr sig mindre om att förutsäga de ord som inte är dolda.
- Detta beror på att den verkliga utmaningen är att ta reda på de delar som saknas, och den här strategin hjälper BERT att bli riktigt bra på att förstå ordens betydelse och sammanhang.
I tekniska termer,
- BERT lägger till ett klassificeringsskikt ovanpå utdata från kodaren. Detta lager är avgörande för att förutsäga de maskerade orden.
- Utdatavektorerna från klassificeringsskiktet multipliceras med inbäddningsmatrisen, och omvandlar dem till ordförrådsdimensionen. Detta steg hjälper till att anpassa de förutsagda representationerna med ordförrådsutrymmet.
- Sannolikheten för varje ord i vokabulären beräknas med hjälp av SoftMax aktiveringsfunktion . Detta steg genererar en sannolikhetsfördelning över hela ordförrådet för varje maskerad position.
- Förlustfunktionen som används under träning tar endast hänsyn till förutsägelsen av de maskerade värdena. Modellen straffas för avvikelsen mellan dess förutsägelser och de faktiska värdena för de maskerade orden.
- Modellen konvergerar långsammare än riktningsmodeller. Detta beror på att BERT under träningen endast är angelägen om att förutsäga de maskerade värdena och ignorera förutsägelsen av de icke-maskerade orden. Den ökade sammanhangsmedvetenheten som uppnås genom denna strategi kompenserar för den långsammare konvergensen.
2. Förutsägelse av nästa mening (NSP)
BERT förutsäger om den andra meningen är kopplad till den första. Detta görs genom att omvandla utsignalen från [CLS]-token till en 2×1-formad vektor med hjälp av ett klassificeringsskikt, och sedan beräkna sannolikheten för om den andra meningen följer efter den första med SoftMax.
- I utbildningsprocessen lär sig BERT att förstå förhållandet mellan meningspar och förutsäga om den andra meningen följer den första i originaldokumentet.
- 50 % av inmatningsparen har den andra meningen som den efterföljande meningen i originaldokumentet, och de andra 50 % har en slumpmässigt vald mening.
- För att hjälpa modellen att skilja mellan sammankopplade och frånkopplade meningspar. Inmatningen bearbetas innan modellen går in:
- En [CLS]-token infogas i början av den första meningen, och en [SEP]-token läggs till i slutet av varje mening.
- En inbäddad mening som indikerar mening A eller mening B läggs till varje token.
- En positionsinbäddning indikerar positionen för varje token i sekvensen.
- BERT förutsäger om den andra meningen är kopplad till den första. Detta görs genom att omvandla utdata från [CLS]-token till en 2×1-formad vektor med hjälp av ett klassificeringsskikt, och sedan beräkna sannolikheten för om den andra meningen följer efter den första med SoftMax.
Under träningen av BERT-modellen tränas Masked LM och Next Sentence Prediction tillsammans. Modellen syftar till att minimera den kombinerade förlustfunktionen hos Masked LM och Next Sentence Prediction, vilket leder till en robust språkmodell med förbättrad förmåga att förstå sammanhang i meningar och relationer mellan meningar.
Varför träna Masked LM och Next Sentence Prediction tillsammans?
Maskerad LM hjälper BERT att förstå sammanhanget inom en mening och Förutsägelse av nästa mening hjälper BERT att förstå sambandet eller förhållandet mellan meningspar. Att träna båda strategierna tillsammans säkerställer därför att BERT lär sig en bred och heltäckande förståelse av språk, som fångar både detaljer i meningar och flödet mellan meningar.
BERT arkitekturer
Arkitekturen för BERT är en flerskikts dubbelriktad transformatorkodare som är ganska lik transformatormodellen. En transformatorarkitektur är ett encoder-decoder-nätverk som använder självuppmärksamhet på kodarsidan och uppmärksamhet på dekodersidan.
- BERTBAShar 1 2 lager i Encoder-stacken medan BERTSTORhar 24 lager i Encoder-stacken . Dessa är fler än Transformer-arkitekturen som beskrivs i originaltidningen ( 6 kodarlager ).
- BERT-arkitekturer (BASE och LARGE) har också större feedforward-nätverk (768 respektive 1024 dolda enheter), och fler uppmärksamhetshuvuden (12 respektive 16) än Transformer-arkitekturen föreslog i originaltidningen. Det innehåller 512 dolda enheter och 8 uppmärksamhetshuvuden .
- BERTBASinnehåller 110M parametrar medan BERTSTORhar 340M parametrar.

BERT BASE och BERT LARGE arkitektur.
Denna modell tar CLS token som indata först, sedan följs den av en sekvens av ord som input. Här är CLS en klassificeringstoken. Den skickar sedan indata till ovanstående lager. Varje lager gäller självuppmärksamhet och skickar resultatet genom ett feedforward-nätverk efter att det skickas vidare till nästa kodare. Modellen matar ut en vektor med dold storlek ( 768 för BERT BASE). Om vi vill mata ut en klassificerare från denna modell kan vi ta utdata som motsvarar CLS-token.
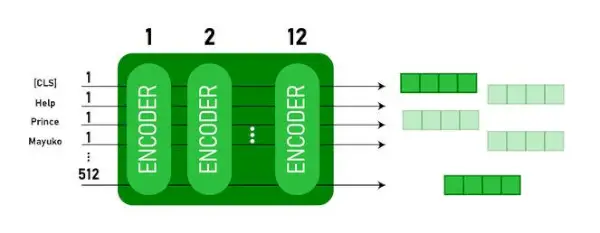
BERT-utgång som inbäddningar
Nu kan denna tränade vektor användas för att utföra ett antal uppgifter såsom klassificering, översättning, etc. Till exempel uppnår papperet fantastiska resultat bara genom att använda ett enda lager Neuralt nätverk på BERT-modellen i klassificeringsuppgiften.
Hur använder man BERT-modellen i NLP?
BERT kan användas för olika naturliga språkbehandlingsuppgifter (NLP) såsom:
1. Klassificeringsuppgift
- BERT kan användas för klassificeringsuppgifter som sentimentanalys , målet är att klassificera texten i olika kategorier (positiv/negativ/neutral), BERT kan användas genom att lägga till ett klassificeringslager överst på transformatorns utdata för [CLS]-token.
- [CLS]-token representerar den aggregerade informationen från hela inmatningssekvensen. Denna sammanslagna representation kan sedan användas som indata för ett klassificeringsskikt för att göra förutsägelser för den specifika uppgiften.
2. Besvara frågor
- I frågesvarsuppgifter, där modellen krävs för att lokalisera och markera svaret inom en given textsekvens, kan BERT tränas för detta ändamål.
- BERT tränas för att svara på frågor genom att lära sig ytterligare två vektorer som markerar början och slutet av svaret. Under träningen förses modellen med frågor och motsvarande stycken, och den lär sig att förutsäga start- och slutpositionerna för svaret i stycket.
3. Named Entity Recognition (NER)
- BERT kan användas för NER, där målet är att identifiera och klassificera enheter (t.ex. Person, Organisation, Datum) i en textsekvens.
- En BERT-baserad NER-modell tränas genom att ta utgångsvektorn för varje token från transformatorn och mata in den i ett klassificeringsskikt. Lagret förutsäger den namngivna entitetsetiketten för varje token, vilket indikerar vilken typ av entitet det representerar.
Hur tokenisera och koda text med BERT?
För att tokenisera och koda text med BERT kommer vi att använda 'transformator'-biblioteket i Python.
Kommando för att installera transformatorer:
!pip install transformers>
- Vi kommer att ladda den förtränade BERT-tokenize med ett fodralt ordförråd med hjälp av BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(text) tokeniserar inmatningstexten och konverterar den till en sekvens av token-ID:n.
- print (Token IDs:, kodning) skriver ut de token-ID:n som erhållits efter kodning.
- tokenizer.convert_ids_to_tokens(kodning) konverterar token-ID:n till deras motsvarande tokens.
- print(Tokens:, tokens) skriver ut de tokens som erhållits efter konvertering av token-ID:n
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Produktion:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> De tokenizer.encode metod lägger till det speciella [CLS] – klassificering och [SEP] – separator tokens i början och slutet av den kodade sekvensen.
Tillämpning av BERT
BERT används för:
- Textrepresentation: BERT används för att generera ordinbäddningar eller representation för ord i en mening.
- Named Entity Recognition (NER) : BERT kan finjusteras för namngivna entitetsigenkänningsuppgifter, där målet är att identifiera enheter som namn på personer, organisationer, platser etc. i en given text.
- Textklassificering: BERT används ofta för textklassificeringsuppgifter, inklusive sentimentanalys, skräppostdetektering och ämneskategorisering. Den har visat utmärkta prestationer när det gäller att förstå och klassificera sammanhanget för textdata.
- Frågesvarssystem: BERT har tillämpats på frågesvarssystem, där modellen tränas för att förstå sammanhanget för en fråga och ge relevanta svar. Detta är särskilt användbart för uppgifter som läsförståelse.
- Maskinöversättning: BERT:s kontextuella inbäddningar kan utnyttjas för att förbättra maskinöversättningssystem. Modellen fångar språkets nyanser som är avgörande för korrekt översättning.
- Textsammanfattning: BERT kan användas för abstrakt textsammanfattning, där modellen genererar kortfattade och meningsfulla sammanfattningar av längre texter genom att förstå sammanhang och semantik.
- Konversations-AI: BERT är anställd i att bygga konversations-AI-system, såsom chatbots, virtuella assistenter och dialogsystem. Dess förmåga att förstå sammanhang gör den effektiv för att förstå och generera naturliga språksvar.
- Semantisk likhet: BERT-inbäddningar kan användas för att mäta semantisk likhet mellan meningar eller dokument. Detta är värdefullt i uppgifter som dubblettdetektering, parafrasidentifiering och informationshämtning.
BERT vs GPT
Skillnaden mellan BERT och GPT är följande:
| BERT | GPT | |
|---|---|---|
| Arkitektur | BERT är designat för inlärning av dubbelriktad representation. Den använder ett maskerat språkmodellmål, där det förutsäger saknade ord i en mening baserat på både vänster och höger kontext. | GPT, å andra sidan, är designad för generativ språkmodellering. Den förutsäger nästa ord i en mening med tanke på föregående sammanhang, med hjälp av en enkelriktad autoregressiv metod. |
| Mål för förutbildningen | BERT är förtränad med hjälp av ett maskerat språkmodellmål och nästa meningsprediktion. Det fokuserar på att fånga dubbelriktat sammanhang och förstå relationer mellan ord i en mening. | GPT är förutbildad för att förutsäga nästa ord i en mening, vilket uppmuntrar modellen att lära sig en sammanhängande representation av språk och generera kontextuellt relevanta sekvenser. |
| Kontextförståelse | BERT är effektivt för uppgifter som kräver en djup förståelse av sammanhang och relationer inom en mening, såsom textklassificering, namngiven enhetsigenkänning och frågesvar. | GPT är starkt för att generera sammanhängande och kontextuellt relevant text. Det används ofta i kreativa uppgifter, dialogsystem och uppgifter som kräver generering av naturliga språksekvenser. |
| Uppgiftstyper och användningsfall
| Används ofta i uppgifter som textklassificering, namngiven enhetsigenkänning, sentimentanalys och frågesvar. | Tillämpas på uppgifter som textgenerering, dialogsystem, sammanfattning och kreativt skrivande. |
| Finjustering vs Få-Shot Learning | BERT finjusteras ofta på specifika nedströmsuppgifter med märkta data för att anpassa sina förutbildade representationer till den aktuella uppgiften. | GPT är designat för att utföra få-shot-inlärning, där det kan generaliseras till nya uppgifter med minimal uppgiftsspecifik träningsdata. |
Kolla också:
- Sentimentklassificering med BERT
- Hur genererar man Word-inbäddning med BERT?
- BART-modell för automatisk textkomplettering i NLP
- Toxic Comment Klassificering med BERT
- Förutsägelse av nästa mening med BERT
Vanliga frågor (FAQs)
F. Vad används BERT till?
BERT används för att utföra NLP-uppgifter som textrepresentation, namngiven enhetsigenkänning, textklassificering, Q&A-system, maskinöversättning, textsammanfattning och mer.
F. Vilka är fördelarna med BERT-modellen?
BERT-språkmodellen sticker ut genom sin omfattande förutbildning i flera språk, och erbjuder en bred språklig täckning jämfört med andra modeller. Detta gör BERT särskilt fördelaktigt för icke-engelskbaserade projekt, eftersom det ger robusta kontextuella representationer och semantisk förståelse över en mängd olika språk, vilket förbättrar dess mångsidighet i flerspråkiga applikationer.
F. Hur fungerar BERT för sentimentanalys?
BERT utmärker sig i sentimentanalys genom att utnyttja sin dubbelriktade representationsinlärning för att fånga kontextuella nyanser, semantiska betydelser och syntaktiska strukturer inom en given text. Detta gör det möjligt för BERT att förstå sentimentet uttryckt i en mening genom att överväga relationerna mellan ord, vilket resulterar i mycket effektiva sentimentanalysresultat.
android versioner
F. Är Google baserat på BERT?
BERT och RankBrain är komponenter i Googles sökalgoritm för att bearbeta frågor och webbsidors innehåll för att få bättre förståelse för att förbättra sökresultaten.