Neurala nätverk är beräkningsmodeller som efterliknar den mänskliga hjärnans komplexa funktioner. De neurala nätverken består av sammankopplade noder eller neuroner som bearbetar och lär sig av data, vilket möjliggör uppgifter som mönsterigenkänning och beslutsfattande inom maskininlärning. Artikeln utforskar mer om neurala nätverk, deras funktion, arkitektur och mer.
Innehållsförteckning
c++ int till sträng
- Utveckling av neurala nätverk
- Vad är neurala nätverk?
- Hur fungerar neurala nätverk?
- Att lära sig ett neuralt nätverk
- Typer av neurala nätverk
- Enkel implementering av ett neuralt nätverk
Utveckling av neurala nätverk
Sedan 1940-talet har det skett ett antal anmärkningsvärda framsteg inom området för neurala nätverk:
- 1940-1950-talet: Tidiga koncept
Neurala nätverk började med introduktionen av den första matematiska modellen av artificiella neuroner av McCulloch och Pitts. Men beräkningsbegränsningar gjorde framsteg svåra.
- 1960-1970-tal: Perceptroner
Denna era definieras av Rosenblatts arbete med perceptroner. Perceptroner är enskiktsnätverk vars tillämplighet var begränsad till problem som kunde lösas linjärt separat.
- 1980-talet: Backpropagation and Connectionism
Flerskiktsnätverk träning möjliggjordes av Rumelhart, Hinton och Williams uppfinning av metoden för bakåtförökning. Med sin tonvikt på lärande genom sammankopplade noder, vann konnektionism tilltal.
- 1990-talet: Boom and Winter
Med tillämpningar inom bildidentifiering, ekonomi och andra områden, såg neurala nätverk en boom. Neurala nätverksforskning upplevde dock en vinter på grund av orimliga beräkningskostnader och höga förväntningar.
- 2000-talet: Återuppståndelse och djupt lärande
Större datauppsättningar, innovativa strukturer och förbättrad bearbetningskapacitet sporrade en comeback. Djup lärning har visat fantastisk effektivitet i ett antal discipliner genom att använda flera lager.
- 2010-talet-nu: Deep Learning Dominance
Konvolutionella neurala nätverk (CNN) och återkommande neurala nätverk (RNN), två djupinlärningsarkitekturer, dominerade maskininlärning. Deras kraft demonstrerades av innovationer inom spel, bildigenkänning och naturlig språkbehandling.
Vad är neurala nätverk?
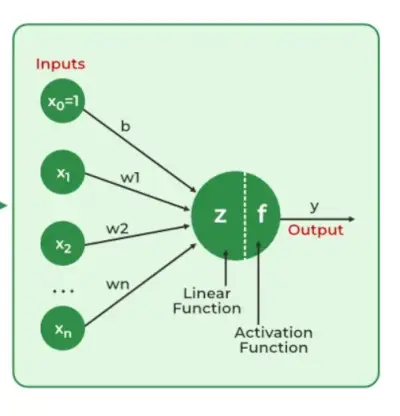
Neurala nätverk extrahera identifierande egenskaper från data, saknar förprogrammerad förståelse. Nätverkskomponenter inkluderar neuroner, anslutningar, vikter, fördomar, fortplantningsfunktioner och en inlärningsregel. Neuroner tar emot insignaler, styrda av trösklar och aktiveringsfunktioner. Anslutningar involverar vikter och fördomar som reglerar informationsöverföring. Inlärning, justering av vikter och fördomar sker i tre steg: indataberäkning, outputgenerering och iterativ förfining som förbättrar nätverkets skicklighet i olika uppgifter.
Dessa inkluderar:
- Det neurala nätverket simuleras av en ny miljö.
- Sedan ändras de fria parametrarna för det neurala nätverket som ett resultat av denna simulering.
- Det neurala nätverket reagerar sedan på ett nytt sätt på miljön på grund av förändringarna i dess fria parametrar.
Vikten av neurala nätverk
Förmågan hos neurala nätverk att identifiera mönster, lösa intrikata pussel och anpassa sig till föränderliga omgivningar är avgörande. Deras förmåga att lära av data har långtgående effekter, allt från revolutionerande teknik som naturlig språkbehandling och självkörande bilar för att automatisera beslutsprocesser och öka effektiviteten i många branscher. Utvecklingen av artificiell intelligens är till stor del beroende av neurala nätverk, som också driver innovation och påverkar teknikens inriktning.
Hur fungerar neurala nätverk?
Låt oss förstå med ett exempel på hur ett neuralt nätverk fungerar:
Överväg ett neuralt nätverk för e-postklassificering. Indatalagret tar funktioner som e-postinnehåll, avsändarinformation och ämne. Dessa ingångar, multiplicerade med justerade vikter, passerar genom dolda lager. Nätverket lär sig genom träning att känna igen mönster som indikerar om ett e-postmeddelande är skräppost eller inte. Utdatalagret, med en binär aktiveringsfunktion, förutsäger om e-postmeddelandet är skräppost (1) eller inte (0). När nätverket iterativt förfinar sina vikter genom backpropagation, blir det skickligt på att skilja mellan spam och legitima e-postmeddelanden, och visar upp det praktiska i neurala nätverk i verkliga tillämpningar som e-postfiltrering.
Arbeta med ett neuralt nätverk
Neurala nätverk är komplexa system som efterliknar vissa funktioner i den mänskliga hjärnans funktion. Den består av ett ingångsskikt, ett eller flera dolda skikt och ett utgångsskikt som består av skikt av artificiella neuroner som är kopplade. De två stegen i den grundläggande processen kallas backpropagation och fortplantning framåt .
Förökning framåt
- Indatalager: Varje funktion i inmatningsskiktet representeras av en nod på nätverket, som tar emot indata.
- Vikter och anslutningar: Vikten av varje neuronal koppling indikerar hur stark kopplingen är. Under hela träningen ändras dessa vikter.
- Dolda lager: Varje gömt lagerneuron bearbetar indata genom att multiplicera dem med vikter, lägga ihop dem och sedan skicka dem genom en aktiveringsfunktion. Genom att göra detta introduceras icke-linjäritet, vilket gör det möjligt för nätverket att känna igen invecklade mönster.
- Produktion: Det slutliga resultatet framställs genom att upprepa processen tills utgångsskiktet nås.
Backpropagation
- Förlustberäkning: Nätverkets utdata utvärderas mot de verkliga målvärdena, och en förlustfunktion används för att beräkna skillnaden. För ett regressionsproblem, Mean Squared Error (MSE) används vanligtvis som kostnadsfunktion.
Förlustfunktion:
- Gradient Descent: Gradientnedstigning används sedan av nätverket för att minska förlusten. För att minska felaktigheten ändras vikterna baserat på derivatan av förlusten med avseende på varje vikt.
- Justera vikter: Vikterna justeras vid varje anslutning genom att tillämpa denna iterativa process, eller tillbakaförökning , bakåt över nätverket.
- Träning: Under träning med olika dataprover görs hela processen med framåtriktad spridning, förlustberäkning och backpropagation iterativt, vilket gör det möjligt för nätverket att anpassa och lära sig mönster från datan.
- Aktiveringsfunktioner: Modellens icke-linjäritet introduceras av aktiveringsfunktioner som likriktad linjär enhet (ReLU) timmar sigmoid . Deras beslut om huruvida de ska avfyra en neuron baseras på hela den viktade inmatningen.

Att lära sig ett neuralt nätverk
1. Lärande med övervakat lärande
I övervakat lärande , det neurala nätverket styrs av en lärare som har tillgång till båda input-output-paren. Nätverket skapar utgångar baserat på ingångar utan att ta hänsyn till omgivningen. Genom att jämföra dessa utsignaler med de av läraren kända önskade utsignalerna genereras en felsignal. För att minska felen ändras nätverkets parametrar iterativt och stoppas när prestandan är på en acceptabel nivå.
2. Lärande med oövervakat lärande
Ekvivalenta utdatavariabler saknas i oövervakat lärande . Dess huvudsakliga mål är att förstå inkommande datas (X) underliggande struktur. Ingen instruktör är närvarande för att ge råd. Modellering av datamönster och relationer är det avsedda resultatet istället. Ord som regression och klassificering är relaterade till övervakat lärande, medan oövervakat lärande är associerat med klustring och association.
välj från flera tabeller sql
3. Lärande med förstärkningsinlärning
Genom interaktion med omgivningen och feedback i form av belöningar eller straff får nätverket kunskap. Att hitta en policy eller strategi som optimerar kumulativa belöningar över tid är målet för nätverket. Denna typ används ofta i spel och beslutsfattande applikationer.
Typer av neurala nätverk
Det finns sju typer av neurala nätverk som kan användas.
- Feedforward-nätverk: A feedforward neurala nätverk är en enkel artificiell neural nätverksarkitektur där data rör sig från input till output i en enda riktning. Den har ingångs-, dolda och utgående lager; återkopplingsslingor saknas. Dess enkla arkitektur gör den lämplig för ett antal tillämpningar, såsom regression och mönsterigenkänning.
- Multilayer Perceptron (MLP): MLP är en typ av frammatningsneurala nätverk med tre eller flera lager, inklusive ett indatalager, ett eller flera dolda lager och ett utdatalager. Den använder icke-linjära aktiveringsfunktioner.
- Convolutional Neural Network (CNN): A Konvolutionellt neuralt nätverk (CNN) är ett specialiserat artificiellt neuralt nätverk designat för bildbehandling. Den använder faltningslager för att automatiskt lära sig hierarkiska funktioner från inmatade bilder, vilket möjliggör effektiv bildigenkänning och klassificering. CNN:er har revolutionerat datorseendet och är centrala i uppgifter som objektdetektering och bildanalys.
- Återkommande neuralt nätverk (RNN): En artificiell neural nätverkstyp avsedd för sekventiell databehandling kallas a Återkommande neurala nätverk (RNN). Det är lämpligt för applikationer där kontextuella beroenden är kritiska, såsom tidsserieprediktion och naturlig språkbehandling, eftersom den använder sig av återkopplingsslingor, som gör det möjligt för information att överleva inom nätverket.
- Långt korttidsminne (LSTM): LSTM är en typ av RNN som är designad för att övervinna problemet med försvinnande gradient vid träning av RNN. Den använder minnesceller och grindar för att selektivt läsa, skriva och radera information.
Enkel implementering av ett neuralt nätverk
Python3
import> numpy as np> # array of any amount of numbers. n = m> X>=> np.array([[>1>,>2>,>3>],> >[>3>,>4>,>1>],> >[>2>,>5>,>3>]])> # multiplication> y>=> np.array([[.>5>, .>3>, .>2>]])> # transpose of y> y>=> y.T> # sigma value> sigm>=> 2> # find the delta> delt>=> np.random.random((>3>,>3>))>-> 1> for> j>in> range>(>100>):> > ># find matrix 1. 100 layers.> >m1>=> (y>-> (>1>/>(>1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt))))))>*>((>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))>*>(>1>->(>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))))> ># find matrix 2> >m2>=> m1.dot(delt.T)>*> ((>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> >*> (>1>->(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))))> ># find delta> >delt>=> delt>+> (>1>/>(>1> +> np.exp(>->(np.dot(X, sigm))))).T.dot(m1)> ># find sigma> >sigm>=> sigm>+> (X.T.dot(m2))> # print output from the matrix> print>(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> |
>
>
Produktion:
[[0.99999325 0.99999375 0.99999352] [0.99999988 0.99999989 0.99999988] [1. 1. 1. ]]>
Fördelar med neurala nätverk
Neurala nätverk används ofta i många olika tillämpningar på grund av deras många fördelar:
- Anpassningsförmåga: Neurala nätverk är användbara för aktiviteter där kopplingen mellan input och output är komplex eller inte väldefinierad eftersom de kan anpassa sig till nya situationer och lära av data.
- Mönsterigenkänning: Deras kunskaper i mönsterigenkänning gör dem effektiva i uppgifter som ljud- och bildidentifiering, naturlig språkbehandling och andra intrikata datamönster.
- Parallell bearbetning: Eftersom neurala nätverk är kapabla till parallell bearbetning av naturen kan de bearbeta många jobb samtidigt, vilket snabbar upp och förbättrar effektiviteten i beräkningar.
- Icke-linjäritet: Neurala nätverk kan modellera och förstå komplicerade relationer i data på grund av de icke-linjära aktiveringsfunktionerna som finns i neuroner, som övervinner nackdelarna med linjära modeller.
Nackdelar med neurala nätverk
Neurala nätverk, även om de är kraftfulla, är inte utan nackdelar och svårigheter:
- Beräkningsintensitet: Träning i stora neurala nätverk kan vara en mödosam och beräkningskrävande process som kräver mycket datorkraft.
- Black box Nature: Som black box-modeller utgör neurala nätverk ett problem i viktiga tillämpningar eftersom det är svårt att förstå hur de fattar beslut.
- Överanpassning: Överanpassning är ett fenomen där neurala nätverk överför träningsmaterial till minnet snarare än att identifiera mönster i data. Även om legaliseringsmetoder hjälper till att lindra detta, finns problemet fortfarande kvar.
- Behov av stora datamängder: För effektiv träning behöver neurala nätverk ofta stora, märkta datamängder; annars kan deras prestanda drabbas av ofullständiga eller skeva data.
Vanliga frågor (FAQs)
1. Vad är ett neuralt nätverk?
Ett neuralt nätverk är ett artificiellt system som består av sammankopplade noder (neuroner) som bearbetar information, modellerat efter den mänskliga hjärnans struktur. Det används i maskininlärningsjobb där mönster extraheras från data.
2. Hur fungerar ett neuralt nätverk?
Lager av anslutna neuroner bearbetar data i neurala nätverk. Nätverket bearbetar indata, modifierar vikter under träning och producerar en utdata beroende på mönster som det har upptäckt.
tcp och ip-modell
3. Vilka är de vanligaste typerna av neurala nätverksarkitekturer?
Feedforward neurala nätverk, återkommande neurala nätverk (RNN), konvolutionella neurala nätverk (CNN) och långa korttidsminnesnätverk (LSTM) är exempel på vanliga arkitekturer som var och en är designad för en viss uppgift.
4. Vad är skillnaden mellan övervakat och oövervakat lärande i neurala nätverk?
I övervakat lärande används märkta data för att träna ett neuralt nätverk så att det kan lära sig att mappa indata till matchande utgångar. Oövervakat lärande arbetar med omärkta data och letar efter strukturer eller mönster i datan .
5. Hur hanterar neurala nätverk sekventiell data?
Återkopplingsslingorna som återkommande neurala nätverk (RNN) innehåller gör att de kan bearbeta sekventiell data och, med tiden, fånga beroenden och sammanhang.