Hashkartor är indexerade datastrukturer. En hashkarta använder sig av en hash-funktion för att beräkna ett index med en nyckel i en uppsättning hinkar eller luckor. Dess värde mappas till hinken med motsvarande index. Nyckeln är unik och oföränderlig. Tänk på en hashkarta som ett skåp med lådor med etiketter för de saker som förvaras i dem. Till exempel, lagring av användarinformation – betrakta e-post som nyckeln, och vi kan mappa värden som motsvarar den användaren som förnamn, efternamn etc till en hink.
Hash-funktionen är kärnan i att implementera en hashkarta. Den tar in nyckeln och översätter den till indexet för en hink i hinklistan. Ideal hashing bör producera ett annat index för varje nyckel. Däremot kan kollisioner förekomma. När hash ger ett befintligt index, kan vi helt enkelt använda en hink för flera värden genom att lägga till en lista eller genom att omhasha.
I Python är ordböcker exempel på hashkartor. Vi kommer att se implementeringen av hashkarta från början för att lära oss hur man bygger och anpassar sådana datastrukturer för att optimera sökningen.
Hashkartans design kommer att innehålla följande funktioner:
- set_val(nyckel, värde): Infogar ett nyckel-värdepar i hashkartan. Om värdet redan finns i hashkartan uppdaterar du värdet.
- get_val(nyckel): Returnerar värdet som den angivna nyckeln är mappad till, eller Ingen post hittades om den här kartan inte innehåller någon mappning för nyckeln.
- delete_val(nyckel): Tar bort mappningen för den specifika nyckeln om hashkartan innehåller mappningen för nyckeln.
Nedan följer genomförandet.
Python3
xdxd betydelse
class> HashTable:> ># Create empty bucket list of given size> >def> __init__(>self>, size):> >self>.size>=> size> >self>.hash_table>=> self>.create_buckets()> >def> create_buckets(>self>):> >return> [[]>for> _>in> range>(>self>.size)]> ># Insert values into hash map> >def> set_val(>self>, key, val):> > ># Get the index from the key> ># using hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be inserted> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key to be inserted,> ># Update the key value> ># Otherwise append the new key-value pair to the bucket> >if> found_key:> >bucket[index]>=> (key, val)> >else>:> >bucket.append((key, val))> ># Return searched value with specific key> >def> get_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key being searched> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key being searched,> ># Return the value found> ># Otherwise indicate there was no record found> >if> found_key:> >return> record_val> >else>:> >return> 'No record found'> ># Remove a value with specific key> >def> delete_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be deleted> >if> record_key>=>=> key:> >found_key>=> True> >break> >if> found_key:> >bucket.pop(index)> >return> ># To print the items of hash map> >def> __str__(>self>):> >return> ''.join(>str>(item)>for> item>in> self>.hash_table)> hash_table>=> HashTable(>50>)> # insert some values> hash_table.set_val(>'[email protected]'>,>'some value'>)> print>(hash_table)> print>()> hash_table.set_val(>'[email protected]'>,>'some other value'>)> print>(hash_table)> print>()> # search/access a record with key> print>(hash_table.get_val(>'[email protected]'>))> print>()> # delete or remove a value> hash_table.delete_val(>'[email protected]'>)> print>(hash_table)> |
>
>
Produktion:
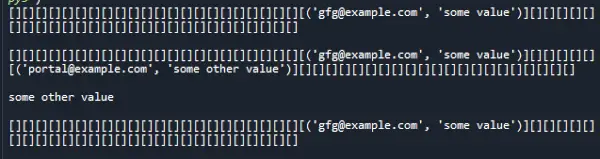
Tidskomplexitet:
Minnesindexåtkomst tar konstant tid och hashning tar konstant tid. Därför är sökkomplexiteten för en hashkarta också konstant tid, det vill säga O(1).
nfa till dfa konvertering
Fördelar med HashMaps
● Snabb slumpmässig minnesåtkomst genom hashfunktioner
● Kan använda negativa och icke-integrala värden för att komma åt värdena.
● Nycklar kan lagras i sorterad ordning och kan därför lätt iterera över kartorna.
Nackdelar med HashMaps
● Kollisioner kan orsaka stora straffavgifter och kan spränga tidskomplexiteten till linjär.
● När antalet nycklar är stort orsakar en enda hashfunktion ofta kollisioner.
Applikationer av HashMaps
● Dessa har applikationer i implementeringar av Cache där minnesplatser mappas till små uppsättningar.
● De används för att indexera tuplar i databashanteringssystem.
● De används också i algoritmer som Rabin Karps mönstermatchning