En process kan vara av två typer:
- Oberoende process.
- Samarbetsprocess.
En oberoende process påverkas inte av exekveringen av andra processer medan en samarbetsprocess kan påverkas av andra exekveringsprocesser. Även om man kan tro att dessa processer, som körs oberoende, kommer att exekvera mycket effektivt, finns det i verkligheten många situationer då samarbetsvillig natur kan användas för att öka beräkningshastigheten, bekvämligheten och modulariteten. Inter-process communication (IPC) är en mekanism som gör att processer kan kommunicera med varandra och synkronisera deras handlingar. Kommunikationen mellan dessa processer kan ses som en metod för samarbete dem emellan. Processer kan kommunicera med varandra genom båda:
- Delat minne
- Meddelandet passerar
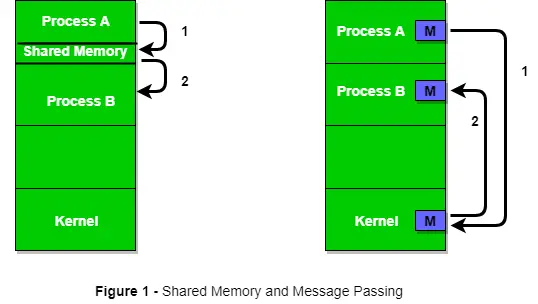
Figur 1 nedan visar en grundläggande struktur för kommunikation mellan processer via metoden med delat minne och via metoden för meddelandeöverföring.
Ett operativsystem kan implementera båda metoderna för kommunikation. Först kommer vi att diskutera de delade minnesmetoderna för kommunikation och sedan skicka meddelanden. Kommunikation mellan processer som använder delat minne kräver att processer delar någon variabel, och det beror helt på hur programmeraren kommer att implementera den. Ett sätt att kommunicera med delat minne kan föreställas så här: Antag att process1 och process2 körs samtidigt och de delar vissa resurser eller använder information från en annan process. Process1 genererar information om vissa beräkningar eller resurser som används och sparar den som en post i delat minne. När process2 behöver använda den delade informationen kommer den att checka in posten som är lagrad i delat minne och notera informationen som genereras av process1 och agera därefter. Processer kan använda delat minne för att extrahera information som en post från en annan process såväl som för att leverera specifik information till andra processer.
Låt oss diskutera ett exempel på kommunikation mellan processer som använder metoden för delat minne.
i) Metod med delat minne
Ex: Producent-Konsument problem
Det finns två processer: producent och konsument. Producenten producerar vissa varor och Konsumenten konsumerar den varan. De två processerna delar ett gemensamt utrymme eller minnesplats känd som en buffert där artikeln som produceras av producenten lagras och från vilken konsumenten konsumerar artikeln vid behov. Det finns två versioner av det här problemet: den första är känd som det obegränsade buffertproblemet där producenten kan fortsätta att producera artiklar och det finns ingen gräns för storleken på bufferten, den andra är känt som det avgränsade buffertproblemet i som Producenten kan producera upp till ett visst antal varor innan den börjar vänta på att Konsumenten ska konsumera den. Vi kommer att diskutera problemet med begränsad buffert. Först kommer producenten och konsumenten att dela något gemensamt minne, sedan kommer producenten att börja producera artiklar. Om det totala producerade föremålet är lika med buffertens storlek, väntar producenten på att få den konsumerad av konsumenten. På samma sätt kommer konsumenten först att kontrollera om varan är tillgänglig. Om ingen vara är tillgänglig kommer konsumenten att vänta på att producenten producerar den. Om det finns artiklar tillgängliga kommer konsumenten att konsumera dem. Pseudokoden som ska demonstreras finns nedan:
Delad data mellan de två processerna
C
#define buff_max 25> #define mod %> >struct> item{> >// different member of the produced data> >// or consumed data> >---------> >}> > >// An array is needed for holding the items.> >// This is the shared place which will be> >// access by both process> >// item shared_buff [ buff_max ];> > >// Two variables which will keep track of> >// the indexes of the items produced by producer> >// and consumer The free index points to> >// the next free index. The full index points to> >// the first full index.> >int> free_index = 0;> >int> full_index = 0;> > |
>
>
Producentens processkod
C
item nextProduced;> > >while>(1){> > >// check if there is no space> >// for production.> >// if so keep waiting.> >while>((free_index+1) mod buff_max == full_index);> > >shared_buff[free_index] = nextProduced;> >free_index = (free_index + 1) mod buff_max;> >}> |
>
>
Konsumentprocesskod
C
item nextConsumed;> > >while>(1){> > >// check if there is an available> >// item for consumption.> >// if not keep on waiting for> >// get them produced.> >while>((free_index == full_index);> > >nextConsumed = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >}> |
>
>
I ovanstående kod kommer producenten att börja producera igen när (free_index+1) mod buff max kommer att vara gratis eftersom om det inte är gratis, innebär detta att det fortfarande finns varor som kan konsumeras av konsumenten så det finns inget behov att producera mer. På samma sätt, om fritt index och fullt index pekar på samma index, innebär detta att det inte finns några varor att konsumera.
Övergripande C++-implementering:
C++
#include> #include> #include> #include> #define buff_max 25> #define mod %> struct> item {> >// different member of the produced data> >// or consumed data> >// ---------> };> // An array is needed for holding the items.> // This is the shared place which will be> // access by both process> // item shared_buff[buff_max];> // Two variables which will keep track of> // the indexes of the items produced by producer> // and consumer The free index points to> // the next free index. The full index points to> // the first full index.> std::atomic<>int>>free_index(0);> std::atomic<>int>>full_index(0);> std::mutex mtx;> void> producer() {> >item new_item;> >while> (>true>) {> >// Produce the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >// Add the item to the buffer> >while> (((free_index + 1) mod buff_max) == full_index) {> >// Buffer is full, wait for consumer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Add the item to the buffer> >// shared_buff[free_index] = new_item;> >free_index = (free_index + 1) mod buff_max;> >mtx.unlock();> >}> }> void> consumer() {> >item consumed_item;> >while> (>true>) {> >while> (free_index == full_index) {> >// Buffer is empty, wait for producer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Consume the item from the buffer> >// consumed_item = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >mtx.unlock();> >// Consume the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> }> int> main() {> >// Create producer and consumer threads> >std::vectorthread>trådar; threads.emplace_back(producent); threads.emplace_back(konsument); // Vänta tills trådarna avslutas för (auto& tråd : trådar) { thread.join(); } returnera 0; }> |
>
>
konvertera en int till en sträng java
Observera att atomklassen används för att säkerställa att de delade variablerna free_index och full_index uppdateras atomärt. Mutex används för att skydda den kritiska sektionen där den delade bufferten nås. Sleep_for-funktionen används för att simulera produktion och konsumtion av varor.
ii) Metod för att skicka meddelanden
Nu kommer vi att börja vår diskussion om kommunikationen mellan processer via meddelandeförmedling. I denna metod kommunicerar processer med varandra utan att använda någon form av delat minne. Om två processer p1 och p2 vill kommunicera med varandra, fortsätter de enligt följande:
- Upprätta en kommunikationslänk (om en länk redan finns behöver du inte upprätta den igen.)
- Börja utbyta meddelanden med grundläggande primitiver.
Vi behöver minst två primitiver:
– skicka (meddelande, destination) eller skicka (meddelande)
– motta (meddelande, värd) eller motta (meddelande)

Meddelandestorleken kan vara av fast storlek eller av variabel storlek. Om det är av fast storlek är det enkelt för en OS-designer men komplicerat för en programmerare och om det är av variabel storlek är det enkelt för en programmerare men komplicerat för OS-designern. Ett standardmeddelande kan ha två delar: sidhuvud och brödtext.
De huvuddel används för att lagra meddelandetyp, destinations-id, käll-id, meddelandelängd och kontrollinformation. Kontrollinformationen innehåller information som vad man ska göra om buffertutrymmet tar slut, sekvensnummer, prioritet. I allmänhet skickas meddelandet med FIFO-stil.
Meddelande passerar genom kommunikationslänk.
Direkt och indirekt kommunikationslänk
Nu kommer vi att börja vår diskussion om metoderna för att implementera kommunikationslänkar. När du implementerar länken finns det några frågor som måste komma ihåg som:
- Hur upprättas länkar?
- Kan en länk kopplas till fler än två processer?
- Hur många länkar kan det finnas mellan varje par av kommunikationsprocesser?
- Vilken kapacitet har en länk? Är storleken på ett meddelande som länken kan rymma fast eller variabel?
- Är en länk enkelriktad eller dubbelriktad?
En länk har en viss kapacitet som bestämmer antalet meddelanden som tillfälligt kan finnas i den för vilka varje länk har en kö associerad med sig som kan ha noll kapacitet, begränsad kapacitet eller obegränsad kapacitet. I nollkapacitet väntar avsändaren tills mottagaren meddelar avsändaren att den har tagit emot meddelandet. I fall som inte är noll, vet inte en process om ett meddelande har tagits emot eller inte efter sändningsoperationen. För detta måste avsändaren uttryckligen kommunicera med mottagaren. Implementeringen av länken beror på situationen, den kan antingen vara en direkt kommunikationslänk eller en inriktad kommunikationslänk.
Direkt kommunikation länkar implementeras när processerna använder en specifik processidentifierare för kommunikationen, men det är svårt att identifiera avsändaren i förväg.
Till exempel skrivarservern.
Indirekt kommunikation sker via en delad brevlåda (port), som består av en kö av meddelanden. Avsändaren förvarar meddelandet i brevlådan och mottagaren hämtar dem.
Meddelande passerar genom utbyte av meddelanden.
Synkron och asynkron meddelandeöverföring:
En process som är blockerad är en process som väntar på någon händelse, till exempel att en resurs blir tillgänglig eller slutförandet av en I/O-operation. IPC är möjlig mellan processerna på samma dator såväl som på processerna som körs på olika datorer, dvs i nätverksanslutna/distribuerade system. I båda fallen kan processen blockeras eller inte blockeras när ett meddelande skickas eller försöker ta emot ett meddelande, så att meddelandeöverföring kan vara blockerande eller icke-blockerande. Blockering övervägs synkron och blockerar skicka betyder att avsändaren kommer att blockeras tills meddelandet tas emot av mottagaren. Liknande, blockerar mottagning har mottagaren blockerad tills ett meddelande är tillgängligt. Icke-blockering övervägs asynkron och Icke-blockerande skicka har avsändaren skickar meddelandet och fortsätter. På liknande sätt har icke-blockerande mottagning att mottagaren får ett giltigt meddelande eller null. Efter en noggrann analys kan vi komma fram till att för en avsändare är det mer naturligt att vara icke-blockerande efter att meddelandet passerat då det kan finnas behov av att skicka meddelandet till olika processer. Avsändaren förväntar sig dock en bekräftelse från mottagaren om sändningen misslyckas. På liknande sätt är det mer naturligt för en mottagare att blockera efter att ha utfärdat mottagningen eftersom informationen från det mottagna meddelandet kan användas för vidare exekvering. Samtidigt, om meddelandet som skickas fortsätter att misslyckas, måste mottagaren vänta på obestämd tid. Det är därför vi också överväger den andra möjligheten att skicka meddelanden. Det finns i princip tre föredragna kombinationer:
- Blockera skicka och blockera mottagning
- Icke-blockerande sändning och Icke-blockerande mottagning
- Icke-blockerande sändning och Blockerande mottagning (används oftast)
I direktmeddelande passerar , Processen som vill kommunicera måste uttryckligen namnge mottagaren eller avsändaren av kommunikationen.
t.ex. skicka (p1, meddelande) betyder att skicka meddelandet till p1.
Liknande, motta(p2, meddelande) innebär att ta emot meddelandet från p2.
I denna kommunikationsmetod upprättas kommunikationslänken automatiskt, som kan vara antingen enkelriktad eller dubbelriktad, men en länk kan användas mellan ett par av sändare och mottagare och ett par av sändare och mottagare bör inte ha mer än ett par av sändare och mottagare. länkar. Symmetri och asymmetri mellan sändning och mottagning kan också implementeras, dvs. antingen kommer båda processerna att namnge varandra för att skicka och ta emot meddelanden eller bara avsändaren kommer att namnge mottagaren för att skicka meddelandet och det finns inget behov av mottagaren för att namnge avsändaren för tar emot meddelandet. Problemet med denna kommunikationsmetod är att om namnet på en process ändras, kommer denna metod inte att fungera.
I Indirekt meddelande passerar , processer använder postlådor (även kallade portar) för att skicka och ta emot meddelanden. Varje brevlåda har ett unikt ID och processer kan bara kommunicera om de delar en brevlåda. Länk upprättas endast om processer delar en gemensam brevlåda och en enda länk kan associeras med många processer. Varje par av processer kan dela flera kommunikationslänkar och dessa länkar kan vara enkelriktade eller dubbelriktade. Anta att två processer vill kommunicera genom indirekt meddelandeöverföring, de nödvändiga åtgärderna är: skapa en brevlåda, använd denna brevlåda för att skicka och ta emot meddelanden, förstör sedan brevlådan. Standardprimitiven som används är: skicka ett meddelande) vilket innebär att skicka meddelandet till brevlåda A. Det primitiva för att ta emot meddelandet fungerar också på samma sätt t.ex. mottaget (A, meddelande) . Det finns ett problem med den här postlådeimplementeringen. Anta att det finns fler än två processer som delar samma brevlåda och anta att processen p1 skickar ett meddelande till brevlådan, vilken process kommer att vara mottagaren? Detta kan lösas genom att antingen genomdriva att endast två processer kan dela en enda brevlåda eller genomdriva att endast en process tillåts utföra mottagningen vid en given tidpunkt eller välja valfri process slumpmässigt och meddela avsändaren om mottagaren. En brevlåda kan göras privat för ett enda avsändare/mottagarpar och kan även delas mellan flera avsändare/mottagarpar. Port är en implementering av en sådan brevlåda som kan ha flera avsändare och en enda mottagare. Den används i klient/serverapplikationer (i detta fall är servern mottagaren). Porten ägs av mottagningsprocessen och skapas av OS på begäran av mottagarprocessen och kan förstöras antingen på begäran av samma mottagarprocessor när mottagaren avslutar sig själv. Att genomdriva att endast en process tillåts för att utföra mottagningen kan göras med hjälp av konceptet ömsesidig uteslutning. Mutex brevlåda skapas som delas av n process. Avsändaren är icke-blockerande och skickar meddelandet. Den första processen som exekverar mottagningen kommer in i det kritiska avsnittet och alla andra processer kommer att blockeras och väntar.
Låt oss nu diskutera producent-konsumentproblemet med hjälp av konceptet att skicka meddelanden. Producenten placerar varor (inuti meddelanden) i brevlådan och konsumenten kan konsumera en vara när minst ett meddelande finns i brevlådan. Koden ges nedan:
Producentkod
C
void> Producer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Consumer, &m);> >item = produce();> >build_message(&m , item ) ;> >send(Consumer, &m);> >}> >}> |
>
>
Konsumentkod
C
void> Consumer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Producer, &m);> >item = extracted_item();> >send(Producer, &m);> >consume_item(item);> >}> >}> |
>
>
Exempel på IPC-system
- Posix : använder delat minnesmetod.
- Mach : använder meddelandeöverföring
- Windows XP: använder meddelandeöverföring med lokala proceduranrop
Kommunikation i klient/serverarkitektur:
Det finns olika mekanismer:
- Rör
- Uttag
- Remote Procedural Calls (RPC)
Ovanstående tre metoder kommer att diskuteras i senare artiklar eftersom alla är ganska konceptuella och förtjänar sina egna separata artiklar.
Referenser:
- Operativsystemkoncept av Galvin et al.
- Föreläsningsanteckningar/ppt av Ariel J. Frank, Bar-Ilan University
Inter-process communication (IPC) är den mekanism genom vilken processer eller trådar kan kommunicera och utbyta data med varandra på en dator eller över ett nätverk. IPC är en viktig aspekt av moderna operativsystem, eftersom det gör det möjligt för olika processer att arbeta tillsammans och dela resurser, vilket leder till ökad effektivitet och flexibilitet.
Fördelar med IPC:
- Gör det möjligt för processer att kommunicera med varandra och dela resurser, vilket leder till ökad effektivitet och flexibilitet.
- Underlättar samordning mellan flera processer, vilket leder till bättre övergripande systemprestanda.
- Möjliggör skapandet av distribuerade system som kan sträcka sig över flera datorer eller nätverk.
- Kan användas för att implementera olika synkroniserings- och kommunikationsprotokoll, såsom semaforer, rör och uttag.
Nackdelar med IPC:
- Ökar systemets komplexitet, vilket gör det svårare att designa, implementera och felsöka.
- Kan införa säkerhetsbrister, eftersom processer kan komma åt eller ändra data som tillhör andra processer.
- Kräver noggrann hantering av systemresurser, såsom minne och CPU-tid, för att säkerställa att IPC-operationer inte försämrar systemets övergripande prestanda.
Kan leda till datainkonsekvenser om flera processer försöker komma åt eller ändra samma data samtidigt. - Sammantaget överväger fördelarna med IPC nackdelarna, eftersom det är en nödvändig mekanism för moderna operativsystem och gör det möjligt för processer att samarbeta och dela resurser på ett flexibelt och effektivt sätt. Man måste dock vara försiktig med att designa och implementera IPC-system noggrant för att undvika potentiella säkerhetsbrister och prestandaproblem.
Mer referens:
http://nptel.ac.in/courses/106108101/pdf/Lecture_Notes/Mod%207_LN.pdf
https://www.youtube.com/watch?v=lcRqHwIn5Dk