Logistisk regression i R-programmering är en klassificeringsalgoritm som används för att hitta sannolikheten för händelseframgång och händelsemisslyckande. Logistisk regression används när den beroende variabeln är binär(0/1, True/False, Yes/No) till sin natur. Logit-funktionen används som länkfunktion i en binomialfördelning.
En binär utfallsvariabels sannolikhet kan förutsägas med hjälp av den statistiska modelleringstekniken känd som logistisk regression. Det är allmänt använt i många olika branscher, inklusive marknadsföring, finans, samhällsvetenskap och medicinsk forskning.
Den logistiska funktionen, vanligen kallad sigmoidfunktionen, är den grundläggande idén som ligger till grund för logistisk regression. Denna sigmoidfunktion används i logistisk regression för att beskriva korrelationen mellan prediktorvariablerna och sannolikheten för det binära utfallet.

Logistisk regression i R-programmering
Logistisk regression kallas också Binomial logistisk regression . Den är baserad på sigmoidfunktionen där utdata är sannolikhet och indata kan vara från -oändligt till +oändligt.
sträng till json java
Teori
Logistisk regression är också känd som en generaliserad linjär modell. Eftersom det används som en klassificeringsteknik för att förutsäga ett kvalitativt svar, varierar värdet på y från 0 till 1 och kan representeras av följande ekvation:
Logistisk regression i R-programmering
sid är sannolikheten för egenskap av intresse. Oddskvoten definieras som sannolikheten för framgång i jämförelse med sannolikheten för misslyckande. Det är en nyckelrepresentation av logistiska regressionskoefficienter och kan ta värden mellan 0 och oändligt. Oddskvoten 1 är när sannolikheten för framgång är lika med sannolikheten för misslyckande. Oddskvoten 2 är när sannolikheten för framgång är dubbelt så stor som sannolikheten för misslyckande. Oddskvoten på 0,5 är när sannolikheten för misslyckande är dubbelt så stor sannolikhet för framgång.
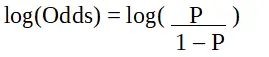
Logistisk regression i R-programmering
Eftersom vi arbetar med en binomialfördelning (beroende variabel) måste vi välja en länkfunktion som är bäst lämpad för denna fördelning.
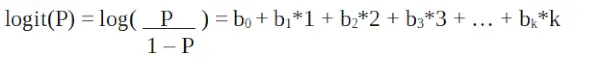
Logistisk regression i R-programmering
Det är en logit funktion . I ekvationen ovan är parentesen vald för att maximera sannolikheten för att observera provvärdena snarare än att minimera summan av kvadratiska fel (som vanlig regression). Logiten är också känd som en logg över odds. Logit-funktionen måste vara linjärt relaterad till de oberoende variablerna. Detta är från ekvation A, där den vänstra sidan är en linjär kombination av x. Detta liknar OLS-antagandet att y är linjärt relaterat till x. Variabler b0, b1, b2 … etc är okända och måste uppskattas på tillgänglig träningsdata. I en logistisk regressionsmodell, multiplicera b1 med en enhet, ändrar logit med b0. P-ändringarna på grund av en ändring på en enhet kommer att bero på multiplicerat värde. Om b1 är positiv kommer P att öka och om b1 är negativ kommer P att minska.
Datauppsättningen
mtcars (motortrend bilvägtest) omfattar bränsleförbrukning, prestanda och 10 aspekter av bildesign för 32 bilar. Den levereras förinstallerad med dplyr paket i R.
R
# Installing the package> install.packages>(>'dplyr'>)> # Loading package> library>(dplyr)> # Summary of dataset in package> summary>(mtcars)> |
>
>
Utföra logistisk regression på en datauppsättning
Logistisk regression implementeras i R med hjälp av glm() genom att träna modellen med hjälp av funktioner eller variabler i datasetet.
R
# Installing the package> # For Logistic regression> install.packages>(>'caTools'>)> # For ROC curve to evaluate model> install.packages>(>'ROCR'>)> > # Loading package> library>(caTools)> library>(ROCR)> |
>
>
Dela upp data
R
# Splitting dataset> split <->sample.split>(mtcars, SplitRatio = 0.8)> split> train_reg <->subset>(mtcars, split ==>'TRUE'>)> test_reg <->subset>(mtcars, split ==>'FALSE'>)> # Training model> logistic_model <->glm>(vs ~ wt + disp,> >data = train_reg,> >family =>'binomial'>)> logistic_model> # Summary> summary>(logistic_model)> |
>
>
Produktion:
Call: glm(formula = vs ~ wt + disp, family = 'binomial', data = train_reg) Deviance Residuals: Min 1Q Median 3Q Max -1.6552 -0.4051 0.4446 0.6180 1.9191 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 1,58781 2,60087 0,610 0,5415 vikt 1,36958 1,60524 0,853 0,3936 disp -0,02969 0,01577 -1,882 0,058 --- Signif. koder: 0 '***' 0,001 '**' 0,01 '*' 0,05 '.' 0,1 ' ' 1 (Spredningsparameter för binomialfamilj tagen till 1) Nullavvikelse: 34,617 på 24 frihetsgrader Kvarstående avvikelse: 20,212 22 frihetsgrader AIC: 26.212 Antal Fisher Scoring iterationer: 6>
- Anrop: Funktionsanropet som används för att passa den logistiska regressionsmodellen visas tillsammans med information om familjen, formeln och data. Avvikelserester: Dessa är avvikelseresterna, som mäter modellens grad av passform. De står för diskrepanser mellan faktiska svar och sannolikhet som förutsägs av den logistiska regressionsmodellen. Koefficienter: Dessa koefficienter i logistisk regression representerar svarsvariabelns logodds eller logit. Standardfelen relaterade till de uppskattade koefficienterna visas i Std. Fel kolumn. Signifikanskoder: Signifikansnivån för varje prediktorvariabel indikeras av signifikanskoderna. Dispersionsparameter: Vid logistisk regression fungerar dispersionsparametern som skalningsparameter för binomialfördelningen. Den är satt till 1 i det här fallet, vilket indikerar att den antagna spridningen är 1. Nollavvikelse: Nollavvikelsen beräknar modellens avvikelse när bara skärningen beaktas. Det symboliserar den avvikelse som skulle bli resultatet av en modell utan prediktorer. Residuell avvikelse: Den kvarvarande avvikelsen beräknar modellens avvikelse efter att prediktorerna har monterats. Det står för den återstående avvikelsen efter att ha tagit hänsyn till prediktorerna. AIC: Akaike Information Criterion (AIC), som står för antalet prediktorer, är en mätare av en modells goda passform. Det straffar mer komplicerade modeller för att förhindra övermontering. Bättre passande modeller indikeras av lägre AIC-värden. Antal iterationer av Fisher-poäng: Antalet iterationer som krävs av Fisher-poängproceduren för att uppskatta modellparametrarna indikeras av antalet iterationer.
Förutsäg testdata baserat på modell
R
försök catch block java
predict_reg <->predict>(logistic_model,> >test_reg, type =>'response'>)> predict_reg> |
>
>
Produktion:
Hornet Sportabout Merc 280C Merc 450SE Chrysler Imperial 0.01226166 0.78972164 0.26380531 0.01544309 AMC Javelin Camaro Z28 Ford Pantera L 0.06104267 0.02807992 0.01107943>
R
# Changing probabilities> predict_reg <->ifelse>(predict_reg>0,5, 1, 0)> # Evaluating model accuracy> # using confusion matrix> table>(test_reg$vs, predict_reg)> missing_classerr <->mean>(predict_reg != test_reg$vs)> print>(>paste>(>'Accuracy ='>, 1 - missing_classerr))> # ROC-AUC Curve> ROCPred <->prediction>(predict_reg, test_reg$vs)> ROCPer <->performance>(ROCPred, measure =>'tpr'>,> >x.measure =>'fpr'>)> auc <->performance>(ROCPred, measure =>'auc'>)> auc <- [email protected][[1]]> auc> # Plotting curve> plot>(ROCPer)> plot>(ROCPer, colorize =>TRUE>,> >print.cutoffs.at =>seq>(0.1, by = 0.1),> >main =>'ROC CURVE'>)> abline>(a = 0, b = 1)> auc <->round>(auc, 4)> legend>(.6, .4, auc, title =>'AUC'>, cex = 1)> |
>
sträng till datum
>
Produktion:
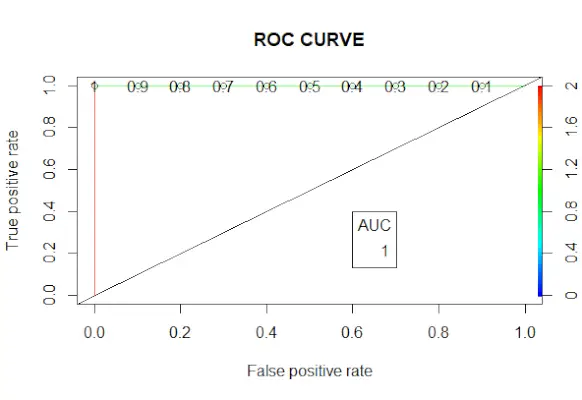
ROC-kurva
Exempel 2:
Vi kan utföra en logistisk regressionsmodell Titanic Dataset i R.
R
# Load the dataset> data>(Titanic)> # Convert the table to a data frame> data <->as.data.frame>(Titanic)> # Fit the logistic regression model> model <->glm>(Survived ~ Class + Sex + Age, family = binomial, data = data)> # View the summary of the model> summary>(model)> |
>
>
Produktion:
Call: glm(formula = Survived ~ Class + Sex + Age, family = binomial, data = data) Deviance Residuals: Min 1Q Median 3Q Max -1.177 -1.177 0.000 1.177 1.177 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 4.022e-16 8.660e-01 0 1 Class2nd -9.762e-16 1.000e+00 0 1 Class3rd -4.699e-16 1.000e+00 0 1 ClassCrew -01.511e. 00 0 1 Kön Kvinna -3.140e-16 7.071e-01 0 1 ÅlderVuxen 5.103e-16 7.071e-01 0 1 (Spredningsparameter för binomialfamilj tas till 1) Nollavvikelse: 44.361 på 31 frihetsgrader 31 frihetsgrader: 14 frihetsgrader:14grader. på 26 frihetsgrader AIC: 56.361 Antal Fisher Scoring iterationer: 2>
Rita ROC-kurvan för Titanic-datauppsättningen
R
# Install and load the required packages> install.packages>(>'ROCR'>)> library>(ROCR)> # Fit the logistic regression model> model <->glm>(Survived ~ Class + Sex + Age, family = binomial, data = data)> # Make predictions on the dataset> predictions <->predict>(model, type =>'response'>)> # Create a prediction object for ROCR> prediction_objects <->prediction>(predictions, titanic_df$Survived)> # Create an ROC curve object> roc_object <->performance>(prediction_obj, measure =>'tpr'>, x.measure =>'fpr'>)> # Plot the ROC curve> plot>(roc_object, main =>'ROC Curve'>, col =>'blue'>, lwd = 2)> # Add labels and a legend to the plot> legend>(>'bottomright'>, legend => >paste>(>'AUC ='>,>round>(>performance>(prediction_objects, measure =>'auc'>)> >@y.values[[1]], 2)), col =>'blue'>, lwd = 2)> |
>
>
Produktion:
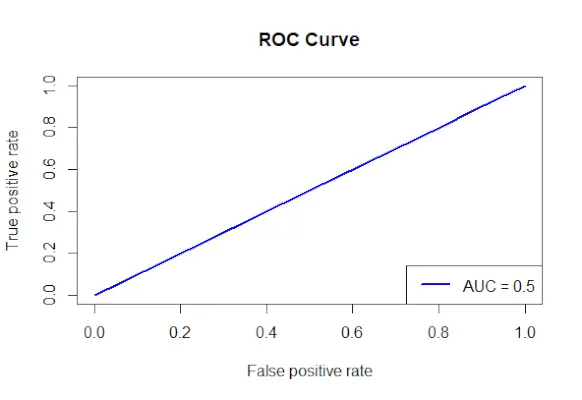
ROC-kurva
- Faktorerna som används för att förutsäga överlevd specificeras, och formeln Överlevd klass + kön + ålder används för att skapa en logistisk regressionsmodell.
- Med funktionen predict() görs förutsägelser på datamängden med hjälp av den anpassade modellen.
- De projicerade sannolikheterna kombineras med de faktiska utfallsvärdena för att bygga ett prediktionsobjekt med hjälp av prediction()-metoden från ROCR-paketet.
- Måttet på den sanna positiva frekvensen (tpr) och x-axelmåttet på den falska positiva frekvensen (fpr) specificeras, och ett ROC-kurvobjekt skapas med funktionen performance() från ROCR-paketet.
- ROC-kurvobjektet (roc_obj), som anger huvudtiteln, färgen och linjebredden, plottas med hjälp av plot()-funktionen.
- Den använder funktionen performance() med measure = auc för att bestämma AUC-värdet (area under kurvan) och lägger till etiketter och en förklaring till plottet.