I den verkliga världen maskininlärning applikationer är det vanligt att ha många relevanta funktioner, men endast en delmängd av dem kan vara observerbara. När man hanterar variabler som ibland är observerbara och ibland inte, är det verkligen möjligt att använda de fall då den variabeln är synlig eller observerad för att lära sig och göra förutsägelser för de fall där den inte är observerbar. Detta tillvägagångssätt kallas ofta för att hantera saknad data. Genom att använda de tillgängliga instanserna där variabeln är observerbar kan maskininlärningsalgoritmer lära sig mönster och relationer från de observerade data. Dessa inlärda mönster kan sedan användas för att förutsäga variabelns värden i fall där den saknas eller inte kan observeras.
Algoritmen förväntningsmaximering kan användas för att hantera situationer där variabler är delvis observerbara. När vissa variabler är observerbara kan vi använda dessa instanser för att lära oss och uppskatta deras värden. Sedan kan vi förutsäga värdena för dessa variabler i fall då det inte är observerbart.
EM-algoritmen föreslogs och namngavs i en nyskapande artikel publicerad 1977 av Arthur Dempster, Nan Laird och Donald Rubin. Deras arbete formaliserade algoritmen och visade dess användbarhet i statistisk modellering och uppskattning.
EM-algoritmen är tillämpbar på latenta variabler, som är variabler som inte är direkt observerbara utan härleds från värdena för andra observerade variabler. Genom att utnyttja den kända allmänna formen av sannolikhetsfördelningen som styr dessa latenta variabler, kan EM-algoritmen förutsäga deras värden.
EM-algoritmen fungerar som grunden för många oövervakade klustringsalgoritmer inom området maskininlärning. Det tillhandahåller ett ramverk för att hitta de lokala parametrarna för maximal sannolikhet för en statistisk modell och härleda latenta variabler i fall där data saknas eller är ofullständig.
Förväntningsmaximering (EM) Algoritm
Algoritmen Expectation-Maximization (EM) är en iterativ optimeringsmetod som kombinerar olika oövervakade maskininlärning algoritmer för att hitta maximal sannolikhet eller maximala posteriora uppskattningar av parametrar i statistiska modeller som involverar icke observerade latenta variabler. EM-algoritmen används ofta för latenta variabelmodeller och kan hantera saknad data. Den består av ett uppskattningssteg (E-steg) och ett maximeringssteg (M-steg), som bildar en iterativ process för att förbättra modellanpassningen.
- I E-steget beräknar algoritmen de latenta variablerna, dvs. förväntan på log-sannolikheten med användning av de aktuella parameteruppskattningarna.
- I M-steget bestämmer algoritmen parametrarna som maximerar den förväntade log-sannolikheten som erhålls i E-steget, och motsvarande modellparametrar uppdateras baserat på de uppskattade latenta variablerna.

Förväntningsmaximering i EM-algoritm
Genom att iterativt upprepa dessa steg försöker EM-algoritmen maximera sannolikheten för de observerade data. Det används vanligtvis för oövervakade inlärningsuppgifter, såsom klustring, där latenta variabler antas och har tillämpningar inom olika områden, inklusive maskininlärning, datorseende och naturlig språkbehandling.
Nyckeltermer i algoritmen för förväntan-maximering (EM).
Några av de vanligaste nyckeltermerna i Expectation-Maximization (EM) Algorithm är följande:
- Latenta variabler: Latenta variabler är oobserverade variabler i statistiska modeller som endast kan härledas indirekt genom deras effekter på observerbara variabler. De kan inte mätas direkt utan kan detekteras genom deras inverkan på de observerbara variablerna. Sannolikhet: Det är sannolikheten att observera givna data givet modellens parametrar. I EM-algoritmen är målet att hitta de parametrar som maximerar sannolikheten. Log-Likelihood: Det är logaritmen för sannolikhetsfunktionen, som mäter passformen mellan de observerade data och modellen. EM-algoritmen strävar efter att maximera log-sannolikheten. Maximum Likelihood Estimation (MLE): MLE är en metod för att uppskatta parametrarna för en statistisk modell genom att hitta de parametervärden som maximerar sannolikhetsfunktionen, vilket mäter hur väl modellen förklarar de observerade data. Posterior sannolikhet: I samband med Bayesiansk slutledning kan EM-algoritmen utökas för att uppskatta de maximala a posteriori (MAP) uppskattningarna, där den posteriora sannolikheten för parametrarna beräknas baserat på den tidigare fördelningen och sannolikhetsfunktionen. Förväntningssteg (E) : E-steget för EM-algoritmen beräknar det förväntade värdet eller den bakre sannolikheten för de latenta variablerna givet de observerade data och aktuella parameteruppskattningar. Det innebär att beräkna sannolikheterna för varje latent variabel för varje datapunkt. Maximering (M) Steg: M-steget för EM-algoritmen uppdaterar parameteruppskattningarna genom att maximera den förväntade log-sannolikheten som erhålls från E-steget. Det handlar om att hitta de parametervärden som optimerar sannolikhetsfunktionen, vanligtvis genom numeriska optimeringsmetoder. Konvergens: Konvergens avser tillståndet när EM-algoritmen har nått en stabil lösning. Det bestäms vanligtvis genom att kontrollera om förändringen i log-sannolikheten eller parameteruppskattningarna faller under en fördefinierad tröskel.
Hur algoritm för förväntningsmaximering (EM) fungerar:
Kärnan i Expectation-Maximization-algoritmen är att använda tillgängliga observerade data i datamängden för att uppskatta de saknade data och sedan använda dessa data för att uppdatera parametrarnas värden. Låt oss förstå EM-algoritmen i detalj.
EM Algoritm Flödesschema
- Initiering:
- Inledningsvis beaktas en uppsättning initialvärden för parametrarna. En uppsättning ofullständiga observerade data ges till systemet med antagandet att de observerade data kommer från en specifik modell.
- Beräkna den bakre sannolikheten eller ansvaret för varje latent variabel givet de observerade data och aktuella parameteruppskattningar.
- Uppskatta de saknade eller ofullständiga datavärdena med hjälp av de aktuella parameteruppskattningarna.
- Beräkna loggsannolikheten för de observerade data baserat på aktuella parameteruppskattningar och uppskattade saknade data.
- Uppdatera parametrarna för modellen genom att maximera den förväntade fullständiga dataloggsannolikheten som erhålls från E-steget.
- Detta involverar vanligtvis att lösa optimeringsproblem för att hitta de parametervärden som maximerar log-sannolikheten.
- Den specifika optimeringsteknik som används beror på problemets natur och vilken modell som används.
- Kontrollera om det är konvergens genom att jämföra förändringen i log-sannolikhet eller parametervärdena mellan iterationer.
- Om förändringen är under en fördefinierad tröskel, stoppa och betrakta algoritmen som konvergerad.
- Annars, gå tillbaka till E-steget och upprepa processen tills konvergens uppnås.
Förväntningsmaximeringsalgoritm Steg för steg Implementering
Importera nödvändiga bibliotek
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> scipy.stats>import> norm> |
jvm
>
>
Generera en datauppsättning med två gaussiska komponenter
Python3
# Generate a dataset with two Gaussian components> mu1, sigma1>=> 2>,>1> mu2, sigma2>=> ->1>,>0.8> X1>=> np.random.normal(mu1, sigma1, size>=>200>)> X2>=> np.random.normal(mu2, sigma2, size>=>600>)> X>=> np.concatenate([X1, X2])> # Plot the density estimation using seaborn> sns.kdeplot(X)> plt.xlabel(>'X'>)> plt.ylabel(>'Density'>)> plt.title(>'Density Estimation of X'>)> plt.show()> |
rullhjulet fungerar inte
>
>
Produktion :
Densitet Plot
Initiera parametrar
Python3
# Initialize parameters> mu1_hat, sigma1_hat>=> np.mean(X1), np.std(X1)> mu2_hat, sigma2_hat>=> np.mean(X2), np.std(X2)> pi1_hat, pi2_hat>=> len>(X1)>/> len>(X),>len>(X2)>/> len>(X)> |
>
>
Utför EM-algoritm
- Itererar för det angivna antalet epoker (20 i detta fall).
- I varje epok beräknar E-steget ansvar (gammavärden) genom att utvärdera Gauss sannolikhetstätheter för varje komponent och vikta dem med motsvarande proportioner.
- M-steget uppdaterar parametrarna genom att beräkna det viktade medelvärdet och standardavvikelsen för varje komponent
Python3
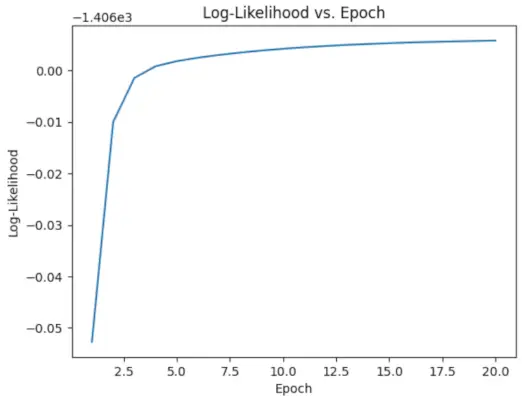
# Perform EM algorithm for 20 epochs> num_epochs>=> 20> log_likelihoods>=> []> for> epoch>in> range>(num_epochs):> ># E-step: Compute responsibilities> >gamma1>=> pi1_hat>*> norm.pdf(X, mu1_hat, sigma1_hat)> >gamma2>=> pi2_hat>*> norm.pdf(X, mu2_hat, sigma2_hat)> >total>=> gamma1>+> gamma2> >gamma1>/>=> total> >gamma2>/>=> total> > ># M-step: Update parameters> >mu1_hat>=> np.>sum>(gamma1>*> X)>/> np.>sum>(gamma1)> >mu2_hat>=> np.>sum>(gamma2>*> X)>/> np.>sum>(gamma2)> >sigma1_hat>=> np.sqrt(np.>sum>(gamma1>*> (X>-> mu1_hat)>*>*>2>)>/> np.>sum>(gamma1))> >sigma2_hat>=> np.sqrt(np.>sum>(gamma2>*> (X>-> mu2_hat)>*>*>2>)>/> np.>sum>(gamma2))> >pi1_hat>=> np.mean(gamma1)> >pi2_hat>=> np.mean(gamma2)> > ># Compute log-likelihood> >log_likelihood>=> np.>sum>(np.log(pi1_hat>*> norm.pdf(X, mu1_hat, sigma1_hat)> >+> pi2_hat>*> norm.pdf(X, mu2_hat, sigma2_hat)))> >log_likelihoods.append(log_likelihood)> # Plot log-likelihood values over epochs> plt.plot(>range>(>1>, num_epochs>+>1>), log_likelihoods)> plt.xlabel(>'Epoch'>)> plt.ylabel(>'Log-Likelihood'>)> plt.title(>'Log-Likelihood vs. Epoch'>)> plt.show()> |
>
>
Produktion :
instansierar java
Epok vs Log-sannolikhet
Rita den slutliga uppskattade densiteten
Python3
# Plot the final estimated density> X_sorted>=> np.sort(X)> density_estimation>=> pi1_hat>*>norm.pdf(X_sorted,> >mu1_hat,> >sigma1_hat)>+> pi2_hat>*> norm.pdf(X_sorted,> >mu2_hat,> >sigma2_hat)> plt.plot(X_sorted, gaussian_kde(X_sorted)(X_sorted), color>=>'green'>, linewidth>=>2>)> plt.plot(X_sorted, density_estimation, color>=>'red'>, linewidth>=>2>)> plt.xlabel(>'X'>)> plt.ylabel(>'Density'>)> plt.title(>'Density Estimation of X'>)> plt.legend([>'Kernel Density Estimation'>,>'Mixture Density'>])> plt.show()> |
>
>
Produktion :
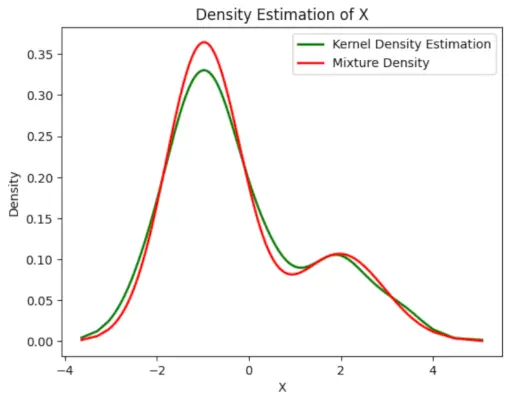
Beräknad densitet
Tillämpningar av EM algoritm
- Den kan användas för att fylla i de saknade uppgifterna i ett prov.
- Det kan användas som grund för oövervakat lärande av kluster.
- Den kan användas för att uppskatta parametrarna för Hidden Markov Model (HMM).
- Den kan användas för att upptäcka värden på latenta variabler.
Fördelar med EM-algoritm
- Det är alltid garanterat att sannolikheten ökar med varje iteration.
- E-steget och M-steget är ofta ganska lätta för många problem när det gäller implementering.
- Lösningar på M-stegen finns ofta i sluten form.
Nackdelar med EM-algoritm
- Den har långsam konvergens.
- Det gör endast konvergens till det lokala optima.
- Det kräver både sannolikheterna, framåt och bakåt (numerisk optimering kräver bara sannolikhet framåt).