Quantile-Quantile (q-q plot) plot är en grafisk metod för att avgöra om en datauppsättning följer en viss sannolikhetsfördelning eller om två dataprov kom från samma befolkning eller inte. Q-Q plots är särskilt användbara för att bedöma om en datauppsättning är normalt fördelade eller om den följer någon annan känd distribution. De används ofta i statistik, dataanalys och kvalitetskontroll för att kontrollera antaganden och identifiera avvikelser från förväntade distributioner.
Kvantiler Och Percentiler
Kvantiler är punkter i en datauppsättning som delar upp data i intervall som innehåller lika sannolikheter eller proportioner av den totala fördelningen. De används ofta för att beskriva spridningen eller distributionen av en datauppsättning. De vanligaste kvantilerna är:
- Median (50:e percentilen) : Medianen är mittvärdet för en datauppsättning när den är ordnad från minsta till största. Den delar upp datasetet i två lika stora halvor.
- Kvartiler (25:e, 50:e och 75:e percentilen) : Kvartiler delar upp datasetet i fyra lika delar. Den första kvartilen (Q1) är det värde under vilket 25 % av datan faller, den andra kvartilen (Q2) är medianen och den tredje kvartilen (Q3) är det värde under vilket 75 % av datan faller.
- Percentiler : Percentiler liknar kvartiler men dela upp datasetet i 100 lika delar. Till exempel är den 90:e percentilen det värde under vilket 90 % av datan faller.
Notera:
- En q-q plot är en plot av kvantilerna i den första datamängden mot kvantilerna i den andra datamängden.
- För referensändamål ritas också en 45 %-linje; För om proverna är från samma population så är punkterna längs denna linje.
Normal distribution:
Normalfördelningen (alias Gaussian distribution Bell-kurva) är en kontinuerlig sannolikhetsfördelning som representerar fördelningen som erhålls från de slumpmässigt genererade reella värdena.
. 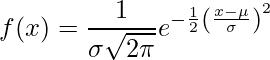

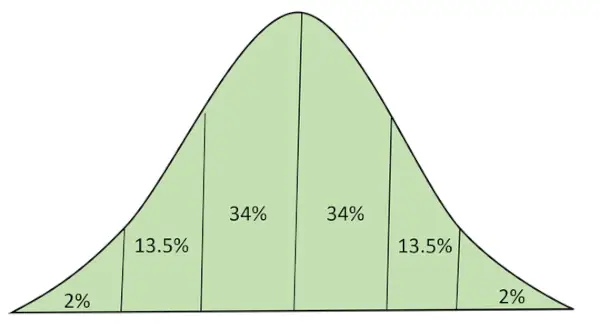
Normalfördelning med area under kurva
Hur man ritar Q-Q plot?
För att rita en Quantile-Quantile (Q-Q) plot kan du följa dessa steg:
- Samla in data : Samla datamängden som du vill skapa Q-Q-plotten för. Se till att uppgifterna är numeriska och representerar ett slumpmässigt urval från populationen av intresse.
- Sortera data : Ordna data i antingen stigande eller fallande ordning. Detta steg är viktigt för att beräkna kvantiler korrekt.
- Välj en teoretisk fördelning : Bestäm den teoretiska fördelning som du vill jämföra din datauppsättning mot. Vanliga val inkluderar normalfördelning, exponentiell distribution eller någon annan distribution som passar dina data väl.
- Beräkna teoretiska kvantiler : Beräkna kvantilerna för den valda teoretiska fördelningen. Till exempel, om du jämför med en normalfördelning, skulle du använda den inversa kumulativa fördelningsfunktionen (CDF) för normalfördelningen för att hitta de förväntade kvantilerna.
- Plotter :
- Plotta de sorterade datauppsättningsvärdena på x-axeln.
- Rita upp motsvarande teoretiska kvantiler på y-axeln.
- Varje datapunkt (x, y) representerar ett par observerade och förväntade värden.
- Anslut datapunkterna för att visuellt inspektera förhållandet mellan datasetet och den teoretiska distributionen.
Tolkning av Q-Q plot
- Om punkterna på diagrammet faller ungefär längs en rät linje, tyder det på att din datauppsättning följer den antagna fördelningen.
- Avvikelser från den räta linjen indikerar avvikelser från den antagna fördelningen, vilket kräver ytterligare utredning.
Utforska distributionslikhet med Q-Q-plots
Att utforska distributionslikhet med Q-Q-plots är en grundläggande uppgift inom statistik. Att jämföra två datamängder för att avgöra om de kommer från samma distribution är avgörande för olika analytiska ändamål. När antagandet om en gemensam fördelning gäller, kan sammanslagning av datauppsättningar förbättra parameteruppskattningens noggrannhet, till exempel för plats och skala. Q-Q plots, förkortning för quantile-quantile plots, erbjuder en visuell metod för att bedöma distributionslikhet. I dessa plotter plottas kvantiler från en datauppsättning mot kvantiler från en annan. Om punkterna ligger tätt i linje längs en diagonal linje, tyder det på likhet mellan fördelningarna. Avvikelser från denna diagonala linje indikerar skillnader i fördelningsegenskaper.
Medan tester som chi-kvadrat och Kolmogorov-Smirnov tester kan utvärdera övergripande fördelningsskillnader, Q-Q plot ger ett nyanserat perspektiv genom att direkt jämföra kvantiler. Detta gör det möjligt för analytiker att urskilja specifika skillnader, såsom förändringar i plats eller förändringar i skala, vilket kanske inte är uppenbart från enbart formella statistiska tester.
Python-implementering av Q-Q-plot
Python3
import> numpy as np> import> matplotlib.pyplot as plt> import> scipy.stats as stats> # Generate example data> np.random.seed(>0>)> data>=> np.random.normal(loc>=>0>, scale>=>1>, size>=>1000>)> # Create Q-Q plot> stats.probplot(data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Normal Q-Q plot'>)> plt.xlabel(>'Theoretical quantiles'>)> plt.ylabel(>'Ordered Values'>)> plt.grid(>True>)> plt.show()> |
>
>
Produktion:
Q-Q plot
Här, eftersom datapunkterna ungefär följer en rät linje i Q-Q-diagrammet, tyder det på att datasetet överensstämmer med den antagna teoretiska fördelningen, som vi i det här fallet antog vara normalfördelningen.
Fördelar med Q-Q plot
- Flexibel jämförelse : Q-Q plots kan jämföra datamängder av olika storlekar utan kräver samma urvalsstorlek.
- Dimensionslös analys : De är dimensionslösa, vilket gör dem lämpliga att jämföra datauppsättningar med olika enheter eller skalor.
- Visuell tolkning : Ger en tydlig visuell representation av datadistribution jämfört med en teoretisk distribution.
- Känslig för avvikelser : Upptäcker enkelt avvikelser från antagna distributioner, vilket hjälper till att identifiera dataavvikelser.
- Diagnostiskt verktyg : Hjälper till att bedöma fördelningsantaganden, identifiera extremvärden och förstå datamönster.
Tillämpningar av kvantil-kvantil plot
Quantile-Quantile plotten används för följande ändamål:
- Bedöma fördelningsantaganden : Q-Q-plots används ofta för att visuellt inspektera om en datauppsättning följer en specifik sannolikhetsfördelning, såsom normalfördelningen. Genom att jämföra de observerade uppgifternas kvantiler med den antagna fördelningens kvantiler kan avvikelser från den antagna fördelningen upptäckas. Detta är avgörande i många statistiska analyser, där giltigheten av fördelningsantaganden påverkar riktigheten av statistiska slutledningar.
- Upptäcka extremvärden : Outliers är datapunkter som avviker avsevärt från resten av datamängden. Q-Q plots kan hjälpa till att identifiera extremvärden genom att avslöja datapunkter som faller långt från det förväntade mönstret för distributionen. Outliers kan förekomma som punkter som avviker från den förväntade räta linjen i plotten.
- Jämför distributioner : Q-Q plots kan användas för att jämföra två datauppsättningar för att se om de kommer från samma distribution. Detta uppnås genom att plotta kvantilerna för en datauppsättning mot kvantilerna för en annan datauppsättning. Om punkterna faller ungefär längs en rät linje, tyder det på att de två datamängderna är ritade från samma fördelning.
- Att bedöma normalitet : Q-Q plots är särskilt användbara för att bedöma normaliteten hos en datauppsättning. Om datapunkterna i diagrammet tätt följer en rät linje indikerar det att datasetet är ungefär normalfördelat. Avvikelser från linjen tyder på avvikelser från normalitet, vilket kan kräva ytterligare utredning eller icke-parametriska statistiska tekniker.
- Modellvalidering : Inom områden som ekonometri och maskininlärning används Q-Q-plots för att validera prediktiva modeller. Genom att jämföra kvantilerna av observerade svar med de kvantiler som förutspås av en modell, kan man bedöma hur väl modellen passar data. Avvikelser från det förväntade mönstret kan indikera områden där modellen behöver förbättras.
- Kvalitetskontroll : Q-Q plots används i kvalitetskontrollprocesser för att övervaka fördelningen av uppmätta eller observerade värden över tid eller över olika batcher. Avvikelser från förväntade mönster i handlingen kan signalera förändringar i de underliggande processerna, vilket föranleder ytterligare utredning.
Typer av Q-Q-plots
Det finns flera typer av Q-Q-plots som vanligtvis används i statistik och dataanalys, var och en lämpad för olika scenarier eller syften:
- Normal distribution : En symmetrisk fördelning där Q-Q-diagrammet skulle visa punkter ungefär längs en diagonal linje om data följer en normalfördelning.
- Höger-snedfördelning : En fördelning där Q-Q-diagrammet skulle visa ett mönster där de observerade kvantilerna avviker från den raka linjen mot den övre änden, vilket indikerar en längre svans på höger sida.
- Vänstersnedfördelning : En fördelning där Q-Q-diagrammet skulle uppvisa ett mönster där de observerade kvantilerna avviker från den raka linjen mot den nedre änden, vilket indikerar en längre svans på vänster sida.
- Underspridd distribution : En fördelning där Q-Q-diagrammet skulle visa observerade kvantiler klustrade tätare runt den diagonala linjen jämfört med de teoretiska kvantilerna, vilket tyder på lägre varians.
- Överspridd distribution : En fördelning där Q-Q-diagrammet skulle visa observerade kvantiler mer utspridda eller avvikande från den diagonala linjen, vilket indikerar högre varians eller dispersion jämfört med den teoretiska fördelningen.
Python3
import> numpy as np> import> matplotlib.pyplot as plt> import> scipy.stats as stats> # Generate a random sample from a normal distribution> normal_data>=> np.random.normal(loc>=>0>, scale>=>1>, size>=>1000>)> # Generate a random sample from a right-skewed distribution (exponential distribution)> right_skewed_data>=> np.random.exponential(scale>=>1>, size>=>1000>)> # Generate a random sample from a left-skewed distribution (negative exponential distribution)> left_skewed_data>=> ->np.random.exponential(scale>=>1>, size>=>1000>)> # Generate a random sample from an under-dispersed distribution (truncated normal distribution)> under_dispersed_data>=> np.random.normal(loc>=>0>, scale>=>0.5>, size>=>1000>)> under_dispersed_data>=> under_dispersed_data[(under_dispersed_data>>->1>) & (under_dispersed_data <>1>)]># Truncate> # Generate a random sample from an over-dispersed distribution (mixture of normals)> over_dispersed_data>=> np.concatenate((np.random.normal(loc>=>->2>, scale>=>1>, size>=>500>),> >np.random.normal(loc>=>2>, scale>=>1>, size>=>500>)))> # Create Q-Q plots> plt.figure(figsize>=>(>15>,>10>))> plt.subplot(>2>,>3>,>1>)> stats.probplot(normal_data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Q-Q Plot - Normal Distribution'>)> plt.subplot(>2>,>3>,>2>)> stats.probplot(right_skewed_data, dist>=>'expon'>, plot>=>plt)> plt.title(>'Q-Q Plot - Right-skewed Distribution'>)> plt.subplot(>2>,>3>,>3>)> stats.probplot(left_skewed_data, dist>=>'expon'>, plot>=>plt)> plt.title(>'Q-Q Plot - Left-skewed Distribution'>)> plt.subplot(>2>,>3>,>4>)> stats.probplot(under_dispersed_data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Q-Q Plot - Under-dispersed Distribution'>)> plt.subplot(>2>,>3>,>5>)> stats.probplot(over_dispersed_data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Q-Q Plot - Over-dispersed Distribution'>)> plt.tight_layout()> plt.show()> |
>
>
Produktion:
Q-Q plot för olika distributioner
skådespelare zeenat aman