Maskininlärning är grenen av Artificiell intelligens som fokuserar på att utveckla modeller och algoritmer som låter datorer lära sig av data och förbättra sig från tidigare erfarenheter utan att vara explicit programmerade för varje uppgift. Med enkla ord lär ML systemen att tänka och förstå som människor genom att lära sig av datan.
I den här artikeln kommer vi att utforska de olika typer av maskininlärningsalgoritmer som är viktiga för framtida krav. Maskininlärning är i allmänhet ett träningssystem för att lära av tidigare erfarenheter och förbättra prestanda över tid. Maskininlärning hjälper till att förutsäga enorma mängder data. Det hjälper till att leverera snabba och exakta resultat för att få lönsamma möjligheter.
Typer av maskininlärning
Det finns flera typer av maskininlärning, var och en med speciella egenskaper och tillämpningar. Några av huvudtyperna av maskininlärningsalgoritmer är följande:
- Övervakad maskininlärning
- Maskininlärning utan tillsyn
- Semi-övervakad maskininlärning
- Förstärkningsinlärning
Typer av maskininlärning
1. Övervakad maskininlärning
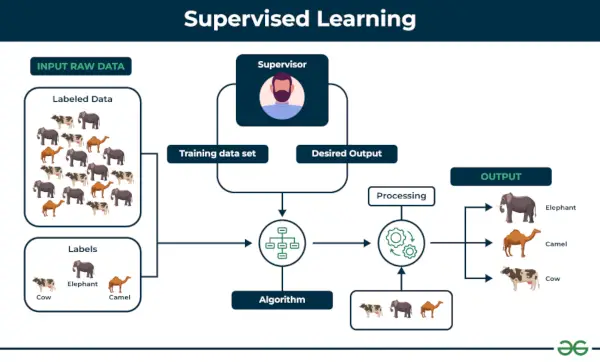
Övervakat lärande definieras som när en modell tränas på en Märkt Dataset . Märkta datamängder har både ingångs- och utdataparametrar. I Övervakat lärande Algoritmer lär sig att kartlägga punkter mellan ingångar och korrekta utgångar. Den har både utbildnings- och valideringsdataset märkta.
Övervakat lärande
Låt oss förstå det med hjälp av ett exempel.
Exempel: Överväg ett scenario där du måste bygga en bildklassificerare för att skilja mellan katter och hundar. Om du matar datauppsättningar av hundar och katter märkta bilder till algoritmen, kommer maskinen att lära sig att klassificera mellan en hund eller en katt från dessa märkta bilder. När vi matar in nya hund- eller kattbilder som den aldrig har sett förut, kommer den att använda de inlärda algoritmerna och förutsäga om det är en hund eller en katt. Detta är hur övervakat lärande fungerar, och detta är särskilt en bildklassificering.
ficklampa installera
Det finns två huvudkategorier av övervakat lärande som nämns nedan:
- Klassificering
- Regression
Klassificering
Klassificering handlar om att förutsäga kategorisk målvariabler, som representerar diskreta klasser eller etiketter. Till exempel att klassificera e-postmeddelanden som spam eller inte spam, eller förutsäga om en patient har en hög risk för hjärtsjukdom. Klassificeringsalgoritmer lär sig att mappa indatafunktionerna till en av de fördefinierade klasserna.
Här är några klassificeringsalgoritmer:
- Logistisk tillbakagång
- Stöd Vector Machine
- Random Forest
- Beslutsträd
- K-Nearest Neighbors (KNN)
- Naiv Bayes
Regression
Regression , å andra sidan, handlar om att förutsäga kontinuerlig målvariabler, som representerar numeriska värden. Till exempel att förutsäga priset på ett hus baserat på dess storlek, läge och bekvämligheter, eller prognostisera försäljningen av en produkt. Regressionsalgoritmer lär sig att mappa indatafunktionerna till ett kontinuerligt numeriskt värde.
Här är några regressionsalgoritmer:
- Linjär regression
- Polynomregression
- Ridge regression
- Lasso regression
- Beslutsträd
- Random Forest
Fördelar med övervakad maskininlärning
- Övervakat lärande modeller kan ha hög noggrannhet när de tränas på märkta data .
- Beslutsprocessen i övervakade lärandemodeller är ofta tolkbar.
- Den kan ofta användas i förtränade modeller vilket sparar tid och resurser vid utveckling av nya modeller från grunden.
Nackdelar med övervakad maskininlärning
- Det har begränsningar i att känna till mönster och kan kämpa med osynliga eller oväntade mönster som inte finns i träningsdatan.
- Det kan vara tidskrävande och kostsamt eftersom det är beroende av märkt endast data.
- Det kan leda till dåliga generaliseringar baserat på nya data.
Tillämpningar av övervakat lärande
Övervakat lärande används i en mängd olika tillämpningar, inklusive:
- Bildklassificering : Identifiera objekt, ansikten och andra funktioner i bilder.
- Naturlig språkbehandling: Extrahera information från text, till exempel känslor, enheter och relationer.
- Taligenkänning : Konvertera talat språk till text.
- Rekommendationssystem : Ge personliga rekommendationer till användare.
- Prediktiv analys : Förutsäg resultat, såsom försäljning, kundförlust och aktiekurser.
- Medicinsk diagnos : Upptäck sjukdomar och andra medicinska tillstånd.
- Spårning av bedrägerier : Identifiera bedrägliga transaktioner.
- Autonoma fordon : Känna igen och reagera på föremål i omgivningen.
- Upptäcka skräppost via e-post : Klassificera e-postmeddelanden som spam eller inte spam.
- Kvalitetskontroll i tillverkningen : Inspektera produkter för defekter.
- Kreditpoäng : Bedöm risken för att en låntagare misslyckas med ett lån.
- Spelande : Känn igen karaktärer, analysera spelarbeteende och skapa NPC:er.
- Kundsupport : Automatisera kundsupportuppgifter.
- Väderprognos : Gör förutsägelser för temperatur, nederbörd och andra meteorologiska parametrar.
- Sportanalys : Analysera spelarens prestanda, gör spelförutsägelser och optimera strategier.
2. Maskininlärning utan tillsyn
Oövervakat lärande Oövervakad inlärning är en typ av maskininlärningsteknik där en algoritm upptäcker mönster och samband med hjälp av omärkta data. Till skillnad från övervakat lärande innebär oövervakat lärande inte att förse algoritmen med märkta målutdata. Det primära målet med oövervakat lärande är ofta att upptäcka dolda mönster, likheter eller kluster inom data, som sedan kan användas för olika ändamål, såsom datautforskning, visualisering, dimensionalitetsreduktion med mera.
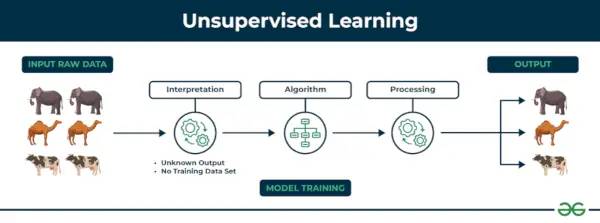
Oövervakat lärande
Låt oss förstå det med hjälp av ett exempel.
Exempel: Tänk på att du har en datauppsättning som innehåller information om de köp du gjort från butiken. Genom klustring kan algoritmen gruppera samma köpbeteende bland dig och andra kunder, vilket avslöjar potentiella kunder utan fördefinierade etiketter. Denna typ av information kan hjälpa företag att få målkunder och identifiera extremvärden.
Det finns två huvudkategorier av oövervakat lärande som nämns nedan:
- Klustring
- Förening
Klustring
Klustring är processen att gruppera datapunkter i kluster baserat på deras likhet. Den här tekniken är användbar för att identifiera mönster och samband i data utan behov av märkta exempel.
Här är några klustringsalgoritmer:
- K-Means Clustering-algoritm
- Algoritm för medelförskjutning
- DBSCAN-algoritm
- Huvudkomponentanalys
- Oberoende komponentanalys
Förening
Association regel lära ing är en teknik för att upptäcka relationer mellan objekt i en datauppsättning. Den identifierar regler som indikerar närvaron av ett föremål, vilket innebär närvaron av ett annat föremål med en specifik sannolikhet.
Här är några algoritmer för inlärning av associationsregel:
- Apriori-algoritm
- Glöd
- FP-tillväxtalgoritm
Fördelar med oövervakad maskininlärning
- Det hjälper till att upptäcka dolda mönster och olika relationer mellan data.
- Används för uppgifter som t.ex kundsegmentering, avvikelsedetektering, och datautforskning .
- Det kräver inte märkta data och minskar ansträngningen för datamärkning.
Nackdelar med oövervakad maskininlärning
- Utan att använda etiketter kan det vara svårt att förutsäga kvaliteten på modellens utdata.
- Klustrets tolkningsbarhet kanske inte är tydlig och kanske inte har meningsfulla tolkningar.
- Den har tekniker som t.ex autokodare och dimensionsreduktion som kan användas för att extrahera meningsfulla funktioner från rådata.
Tillämpningar av oövervakat lärande
Här är några vanliga tillämpningar av oövervakat lärande:
dubbelt länkad lista
- Klustring : Gruppera liknande datapunkter i kluster.
- Anomali upptäckt : Identifiera extremvärden eller anomalier i data.
- Dimensionalitetsreduktion : Minska dimensionaliteten hos data samtidigt som den behåller dess väsentliga information.
- Rekommendationssystem : Föreslå produkter, filmer eller innehåll för användare baserat på deras historiska beteende eller preferenser.
- Ämnesmodellering : Upptäck latenta ämnen i en samling dokument.
- Densitetsuppskattning : Uppskatta datas sannolikhetstäthetsfunktion.
- Bild- och videokomprimering : Minska mängden lagringsutrymme som krävs för multimediainnehåll.
- Dataförbehandling : Hjälp med dataförbearbetningsuppgifter såsom datarensning, imputering av saknade värden och dataskalning.
- Marknadskorgsanalys : Upptäck associationer mellan produkter.
- Genomisk dataanalys : Identifiera mönster eller gruppgener med liknande uttrycksprofiler.
- Bildsegmentering : Segmentera bilder till meningsfulla regioner.
- Gemenskapsupptäckt i sociala nätverk : Identifiera gemenskaper eller grupper av individer med liknande intressen eller kopplingar.
- Analys av kundbeteende : Upptäck mönster och insikter för bättre marknadsföring och produktrekommendationer.
- Innehållsrekommendation : Klassificera och tagga innehåll för att göra det enklare att rekommendera liknande objekt till användare.
- Utforskande dataanalys (EDA) : Utforska data och få insikter innan du definierar specifika uppgifter.
3. Semi-övervakat lärande
Semi-övervakat lärande är en maskininlärningsalgoritm som fungerar mellan övervakad och oövervakad lärande så det använder båda märkta och omärkta data. Det är särskilt användbart när det är kostsamt, tidskrävande eller resurskrävande att få tag på märkta data. Detta tillvägagångssätt är användbart när datasetet är dyrt och tidskrävande. Semi-övervakat lärande väljs när märkt data kräver färdigheter och relevanta resurser för att träna eller lära av det.
Vi använder dessa tekniker när vi har att göra med data som är lite märkta och resten är en stor del av den omärkta. Vi kan använda de oövervakade teknikerna för att förutsäga etiketter och sedan mata dessa etiketter till övervakade tekniker. Denna teknik är mest tillämpbar i fallet med bilddatauppsättningar där vanligtvis inte alla bilder är märkta.
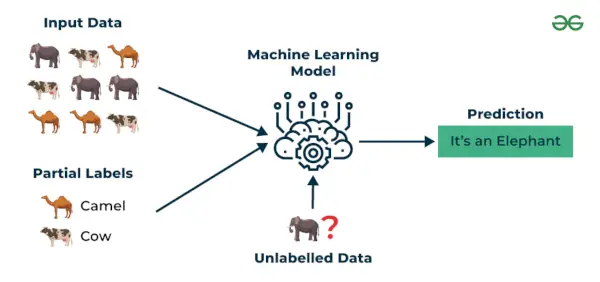
Semi-övervakat lärande
Låt oss förstå det med hjälp av ett exempel.
Exempel : Tänk på att vi bygger en språköversättningsmodell, att ha märkta översättningar för varje meningspar kan vara resurskrävande. Det låter modellerna lära sig av märkta och omärkta meningspar, vilket gör dem mer exakta. Denna teknik har lett till betydande förbättringar av kvaliteten på maskinöversättningstjänster.
Typer av semi-övervakade inlärningsmetoder
Det finns ett antal olika semi-övervakade inlärningsmetoder var och en med sina egna egenskaper. Några av de vanligaste inkluderar:
- Grafbaserad semi-övervakad inlärning: Detta tillvägagångssätt använder en graf för att representera relationerna mellan datapunkterna. Grafen används sedan för att sprida etiketter från de märkta datapunkterna till de omärkta datapunkterna.
- Etikettförökning: Detta tillvägagångssätt sprider iterativt etiketter från de märkta datapunkterna till de omärkta datapunkterna, baserat på likheterna mellan datapunkterna.
- Samträning: Detta tillvägagångssätt tränar två olika maskininlärningsmodeller på olika delmängder av omärkta data. De två modellerna används sedan för att märka varandras förutsägelser.
- Självträning: Detta tillvägagångssätt tränar en maskininlärningsmodell på märkta data och använder sedan modellen för att förutsäga etiketter för omärkta data. Modellen tränas sedan om på märkta data och de förutspådda etiketterna för omärkta data.
- Generativa kontradiktoriska nätverk (GAN) : GAN är en typ av djupinlärningsalgoritm som kan användas för att generera syntetisk data. GAN kan användas för att generera omärkta data för semi-övervakad inlärning genom att träna två neurala nätverk, en generator och en diskriminator.
Fördelar med semi-övervakad maskininlärning
- Det leder till bättre generalisering jämfört med övervakat lärande, eftersom det tar både märkta och omärkta data.
- Kan appliceras på ett brett spektrum av data.
Nackdelar med semi-övervakad maskininlärning
- Halvövervakad metoder kan vara mer komplexa att implementera jämfört med andra metoder.
- Det kräver fortfarande en del märkta data som kanske inte alltid är tillgängliga eller lätta att få tag på.
- Omärkta data kan påverka modellens prestanda i enlighet därmed.
Tillämpningar av semi-övervakat lärande
Här är några vanliga tillämpningar av semi-övervakat lärande:
- Bildklassificering och objektigenkänning : Förbättra modellernas noggrannhet genom att kombinera en liten uppsättning märkta bilder med en större uppsättning omärkta bilder.
- Natural Language Processing (NLP) : Förbättra prestandan för språkmodeller och klassificerare genom att kombinera en liten uppsättning märkt textdata med en stor mängd omärkt text.
- Taligenkänning: Förbättra taligenkänningens noggrannhet genom att utnyttja en begränsad mängd transkriberad taldata och en mer omfattande uppsättning omärkt ljud.
- Rekommendationssystem : Förbättra noggrannheten i personliga rekommendationer genom att komplettera en gles uppsättning interaktioner mellan användarobjekt (märkta data) med en mängd omärkta användarbeteendedata.
- Sjukvård och medicinsk bildbehandling : Förbättra medicinsk bildanalys genom att använda en liten uppsättning märkta medicinska bilder tillsammans med en större uppsättning omärkta bilder.
4. Maskininlärning för förstärkning
Maskininlärning för förstärkning Algoritm är en inlärningsmetod som interagerar med omgivningen genom att producera åtgärder och upptäcka fel. Trial, error och fördröjning är de mest relevanta egenskaperna för förstärkningsinlärning. I den här tekniken fortsätter modellen att öka sin prestation med hjälp av belöningsfeedback för att lära sig beteendet eller mönstret. Dessa algoritmer är specifika för ett speciellt problem, t.ex. Google Self Driving car, AlphaGo där en bot tävlar med människor och till och med sig själv för att få bättre och bättre prestationer i Go Game. Varje gång vi matar in data lär de sig och lägger till data till sin kunskap, vilket är träningsdata. Så ju mer den lär sig desto bättre blir den tränad och därmed upplevd.
Här är några av de vanligaste algoritmerna för förstärkningsinlärning:
- Q-learning: Q-learning är en modellfri RL-algoritm som lär sig en Q-funktion, som mappar tillstånd till handlingar. Q-funktionen uppskattar den förväntade belöningen för att vidta en viss åtgärd i ett givet tillstånd.
- SARSA (State-Action-Reward-State-Action): SARSA är en annan modellfri RL-algoritm som lär sig en Q-funktion. Men till skillnad från Q-learning uppdaterar SARSA Q-funktionen för den åtgärd som faktiskt vidtogs, snarare än den optimala åtgärden.
- Djup Q-learning : Deep Q-learning är en kombination av Q-learning och deep learning. Deep Q-learning använder ett neuralt nätverk för att representera Q-funktionen, vilket gör att den kan lära sig komplexa samband mellan tillstånd och handlingar.
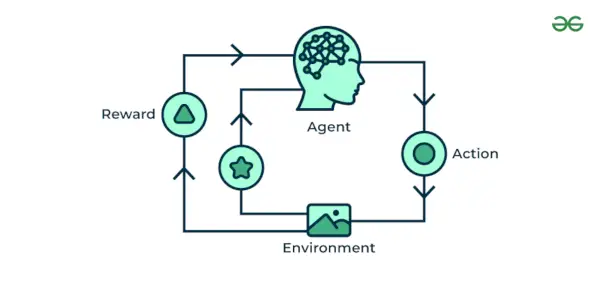
Maskininlärning för förstärkning
Låt oss förstå det med hjälp av exempel.
Exempel: Tänk på att du tränar en AI agent för att spela ett spel som schack. Agenten utforskar olika rörelser och får positiv eller negativ feedback baserat på resultatet. Reinforcement Learning hittar också tillämpningar där de lär sig att utföra uppgifter genom att interagera med sin omgivning.
Typer av förstärkningsmaskininlärning
Det finns två huvudtyper av förstärkningsinlärning:
Positiv förstärkning
- Belönar agenten för att han vidtar en önskad åtgärd.
- Uppmuntrar agenten att upprepa beteendet.
- Exempel: Att ge en godbit till en hund för sittande, ge en poäng i ett spel för ett korrekt svar.
Negativ förstärkning
- Tar bort en oönskad stimulans för att uppmuntra ett önskat beteende.
- Avskräcker agenten från att upprepa beteendet.
- Exempel: Stänga av en hög ljudsignal när en spak trycks ned, undvika en straff genom att slutföra en uppgift.
Fördelar med förstärkningsmaskininlärning
- Den har ett autonomt beslutsfattande som är väl lämpat för uppgifter och som kan lära sig att fatta en sekvens av beslut, som robotik och spel.
- Denna teknik är att föredra för att uppnå långsiktiga resultat som är mycket svåra att uppnå.
- Det används för att lösa komplexa problem som inte kan lösas med konventionella tekniker.
Nackdelar med förstärkningsmaskininlärning
- Utbildningsförstärkning Lärmedel kan vara beräkningsmässigt dyra och tidskrävande.
- Förstärkningsinlärning är inte att föredra framför att lösa enkla problem.
- Det kräver mycket data och mycket beräkning, vilket gör det opraktiskt och kostsamt.
Tillämpningar av förstärkningsmaskininlärning
Här är några tillämpningar av förstärkningsinlärning:
- Spela : RL kan lära agenter att spela spel, även komplexa.
- Robotik : RL kan lära robotar att utföra uppgifter autonomt.
- Autonoma fordon : RL kan hjälpa självkörande bilar att navigera och fatta beslut.
- Rekommendationssystem : RL kan förbättra rekommendationsalgoritmer genom att lära sig användarpreferenser.
- Sjukvård : RL kan användas för att optimera behandlingsplaner och läkemedelsupptäckt.
- Natural Language Processing (NLP) : RL kan användas i dialogsystem och chatbots.
- Finans och handel : RL kan användas för algoritmisk handel.
- Supply Chain och lagerhantering : RL kan användas för att optimera driften i leveranskedjan.
- Energihushållning : RL kan användas för att optimera energiförbrukningen.
- AI-spel : RL kan användas för att skapa mer intelligenta och adaptiva NPC:er i videospel.
- Adaptiva personliga assistenter : RL kan användas för att förbättra personliga assistenter.
- Virtual Reality (VR) och Augmented Reality (AR): RL kan användas för att skapa uppslukande och interaktiva upplevelser.
- Industriell kontroll : RL kan användas för att optimera industriella processer.
- Utbildning : RL kan användas för att skapa adaptiva lärsystem.
- Lantbruk : RL kan användas för att optimera jordbruksdriften.
Måste kolla, vår detaljerade artikel om : Machine Learning Algoritmer
vad min skärmstorlek
Slutsats
Sammanfattningsvis tjänar varje typ av maskininlärning sitt eget syfte och bidrar till den övergripande rollen i utvecklingen av förbättrade dataförutsägelsemöjligheter, och den har potential att förändra olika branscher som t.ex. Datavetenskap . Det hjälper till att hantera massiv dataproduktion och hantering av datamängder.
Typer av maskininlärning – vanliga frågor
1. Vilka är utmaningarna i handledat lärande?
Några av utmaningarna i övervakat lärande inkluderar främst att ta itu med klassobalanser, märkta data av hög kvalitet och undvika överanpassning där modeller presterar dåligt på realtidsdata.
2. Var kan vi tillämpa handledat lärande?
Övervakad inlärning används ofta för uppgifter som att analysera skräppost, bildigenkänning och sentimentanalys.
3. Hur ser framtiden för maskininlärning ut?
Maskininlärning som en framtidsutsikt kan fungera inom områden som väder- eller klimatanalys, sjukvårdssystem och autonom modellering.
4. Vilka är de olika typerna av maskininlärning?
Det finns tre huvudtyper av maskininlärning:
- Övervakat lärande
- Oövervakat lärande
- Förstärkningsinlärning
5. Vilka är de vanligaste maskininlärningsalgoritmerna?
Några av de vanligaste maskininlärningsalgoritmerna inkluderar:
- Linjär regression
- Logistisk tillbakagång
- Stöd för vektormaskiner (SVM)
- K-närmaste grannar (KNN)
- Beslutsträd
- Slumpmässiga skogar
- Artificiellt nervsystem