- Redshift är en snabb och kraftfull, fullt hanterad, petabyte-skala datalagertjänst i molnet.
- Kunder kan använda Redshift för bara
- Redshift är en snabb och kraftfull, fullt hanterad, petabyte-skala datalagertjänst i molnet.
- Kunder kan använda Redshift för bara $0,25 per timme utan åtaganden eller förskottskostnader och skala till en petabyte eller mer för $1 000 per terabyte och år.
OLAP
OLAP är en Online analyssystem används av Rödförskjutning .
Exempel på OLAP-transaktion:
Anta att vi vill beräkna nettovinsten för EMEA och Stillahavsområdet för digitalradioprodukten. Detta kräver att man drar ett stort antal poster. Följande är de poster som krävs för att beräkna en nettovinst:
- Summan av sålda radioapparater i EMEA.
- Summan av sålda radioapparater i Stilla havet.
- Enhetskostnad för radio i varje region.
- Försäljningspris för varje radio
- Försäljningspris - styckkostnad
De komplexa frågorna krävs för att hämta posterna ovan. Data Warehousing databaser använder olika typarkitektur både ur ett databasperspektiv och infrastrukturlager.
Rödskiftningskonfiguration
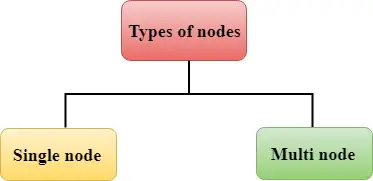
Rödförskjutning består av två typer av noder:
Enskild nod Multi-nod Enskild nod: En enda nod lagrar upp till 160 GB.
Multi-nod: Multi-nod är en nod som består av mer än en nod. Det är av två typer:
Ledarnod
Den hanterar klientanslutningarna och tar emot frågor. En ledarnod tar emot frågorna från klientapplikationerna, analyserar frågorna och utvecklar exekveringsplanerna. Den koordinerar med den parallella exekveringen av dessa planer med beräkningsnoden och kombinerar mellanresultaten för alla noder, och returnerar sedan slutresultatet till klientapplikationen.Beräkna nod
En beräkningsnod exekverar exekveringsplanerna, och sedan skickas mellanresultat till ledarnoden för aggregering innan de skickas tillbaka till klientapplikationen. Den kan ha upp till 128 beräkningsnoder.Låt oss förstå begreppet ledarnod och beräkna noder genom ett exempel.
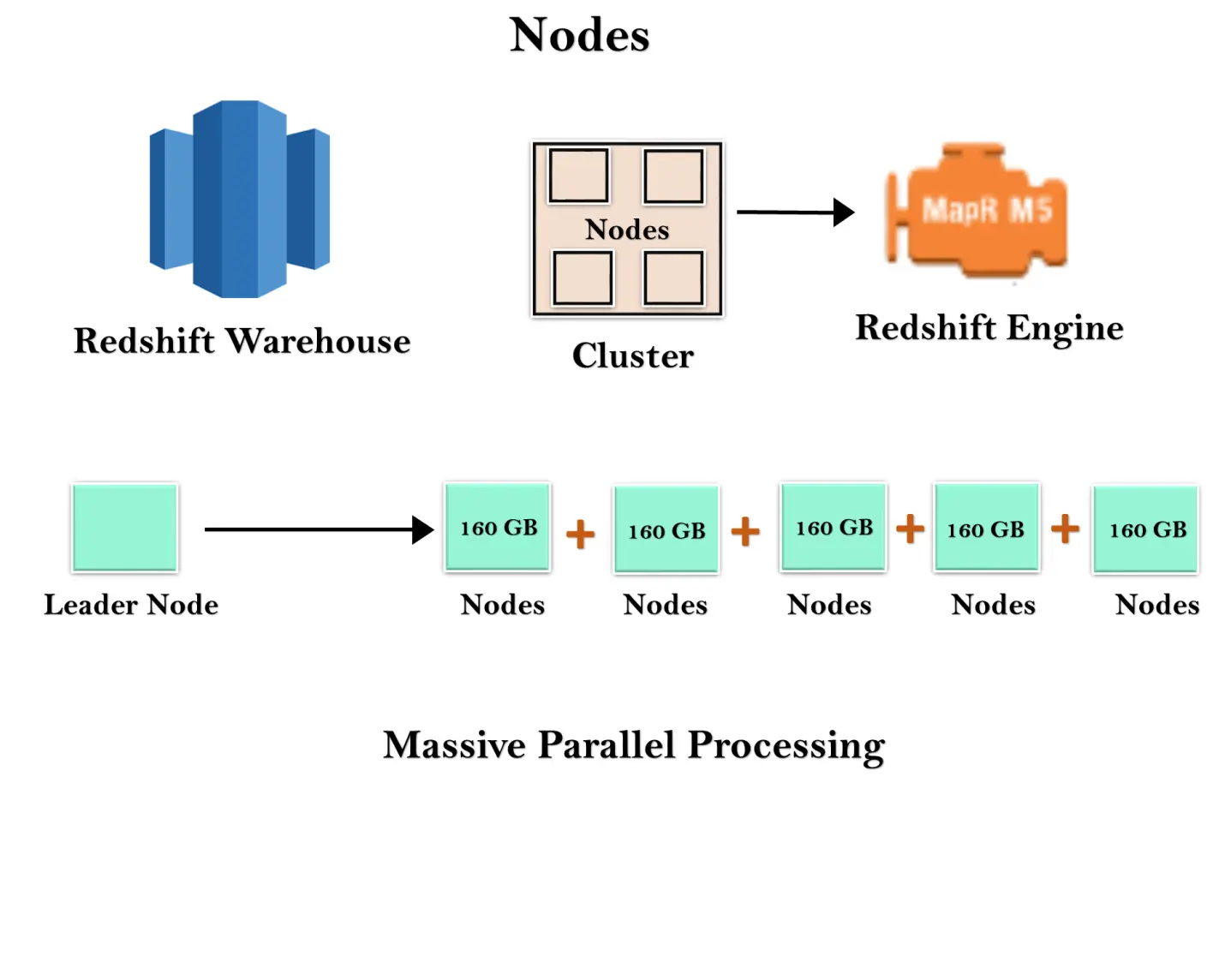
Redshift warehouse är en samling datorresurser som kallas noder, och dessa noder är organiserade i en grupp som kallas ett kluster. Varje kluster körs i en Redshift Engine som innehåller en eller flera databaser.
När du startar en Redshift-instans börjar den med en enda nod på 160 GB. När du vill växa kan du lägga till ytterligare noder för att dra fördel av parallell bearbetning. Du har en ledarnod som hanterar de flera noderna. Leadernod hanterar klientanslutningen såväl som beräkningsnoder. Den lagrar data i beräkningsnoder och utför frågan.
Varför Redshift är 10 gånger snabbare
Rödskiftning är 10 gånger snabbare på grund av följande skäl:
Kolumndatalagring
Istället för att lagra data som en rad rader, organiserar Amazon Redshift data efter kolumn. Radbaserade system är idealiska för transaktionsbearbetning medan kolumnbaserade system är idealiska för datalagring och analys, där frågor ofta involverar aggregat som utförs över stora datamängder. Eftersom endast kolumnerna som är involverade i frågorna bearbetas och kolumnära data lagras i ett lagringsmedium sekventiellt, kräver kolumnbaserade system färre I/O, vilket förbättrar frågeprestanda.Avancerad komprimering
Kolumnära datalager kan komprimeras mycket mer än radbaserade datalager eftersom liknande data lagras sekventiellt på disken. Amazon Redshift använder flera komprimeringstekniker och kan ofta uppnå betydande komprimering i förhållande till traditionella relationsdatalager.
Amazon Redshift kräver inga index eller materialiserade vyer, så det kräver mindre utrymme än traditionella relationsdatabassystem. När du laddar en data till en tom tabell, samplar Amazon Redshift dina data automatiskt och väljer den mest lämpliga komprimeringstekniken.Massivt parallell bearbetning
Amazon Redshift distribuerar automatiskt data och laddar frågan över olika noder. En Amazon Redshift gör det enkelt att lägga till nya noder till ditt datalager, och detta gör att vi kan uppnå snabbare frågeprestanda när ditt datalager växer.Rödskiftningsfunktioner
Funktioner för Redshift ges nedan:
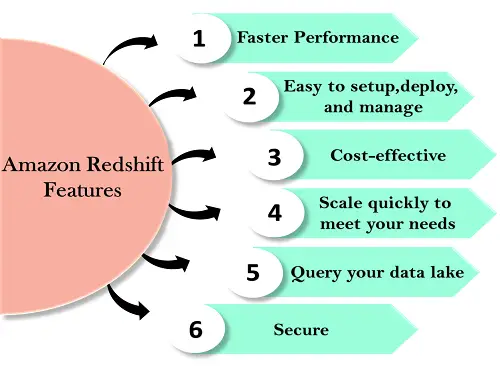
Lätt att installera, distribuera och hantera Automatiserad provisionering
Redshift är enkel att ställa in och använda. Du kan distribuera ett nytt datalager med bara några klick i AWS-konsolen, och Redshift tillhandahåller automatiskt infrastrukturen åt dig. I AWS är alla administrativa uppgifter automatiserade, såsom säkerhetskopiering och replikering, du måste fokusera på din data, inte på administrationen.Automatiserade säkerhetskopieringar
Redshift säkerhetskopierar automatiskt dina data till S3. Du kan också replikera ögonblicksbilderna i S3 i en annan region för eventuell katastrofåterställning.Kostnadseffektiv Inga förskottskostnader, betala när du går
Amazon Redshift är den mest kostnadseffektiva datalagertjänsten eftersom du bara behöver betala för det du använder.
Dess kostnader börjar med 0,25 USD per timme utan åtagande och inga förhandskostnader och kan skalas ut till 250 USD per terabyte och år.
Amazon Redshift är den enda datalagertjänsten som erbjuder On Demand-priser utan förskottskostnader, och den erbjuder även reserverad instansprissättning som sparar upp till 75 % genom att tillhandahålla 1-3 års löptid.Välj din nodtyp.
Du kan välja någon av de två noderna för att optimera rödförskjutningen.Tät beräkningsnod
Tät beräkningsnod kan skapa ett högpresterande datalager genom att använda snabba processorer, en stor mängd RAM-minne och solid-state-diskar.Tät lagringsnod
Om du vill minska kostnaderna kan du använda tät lagringsnod. Det skapar ett kostnadseffektivt datalager genom att använda en större hårddisk.Skala snabbt för att möta dina behov. Petabyte-skala datalager
Amazon Redshift skalar automatiskt upp eller ner noderna efter behovsändringarna. Med bara några klick i AWS-konsolen eller ett enda API-anrop kan du enkelt ändra antalet noder i ett datalager.Exabyte-skala datasjöanalys
Det är en funktion i Redshift som låter dig köra frågorna mot exabyte av data i Amazon S3. Amazon S3 är en säker och kostnadseffektiv data för att lagra obegränsad data i ett öppet format.Gränslös samtidighet
Det är en funktion av Redshift innebär att flera frågor kan komma åt samma data i Amazon S3. Det låter dig köra frågorna över flera noder oavsett hur komplex en fråga är eller mängden data.Fråga din datasjö
Amazon Redshift är det enda datalagret som används för att fråga Amazon S3-datasjön utan att ladda data. Detta ger flexibilitet genom att lagra data som ofta används i Redshift och ostrukturerad eller sällsynt data i Amazon S3.Säkra
Med ett par parameterinställningar kan du ställa in Redshift att använda SSL för att säkra din data. Du kan också aktivera kryptering, all data som skrivs till disken kommer att krypteras.Snabbare prestanda
Amazon Redshift tillhandahåller kolumnär datalagring, komprimering och parallell bearbetning för att minska mängden I/O som behövs för att utföra frågor. Detta förbättrar frågeprestanda.
OLAP
OLAP är en Online analyssystem används av Rödförskjutning .
Exempel på OLAP-transaktion:
Anta att vi vill beräkna nettovinsten för EMEA och Stillahavsområdet för digitalradioprodukten. Detta kräver att man drar ett stort antal poster. Följande är de poster som krävs för att beräkna en nettovinst:
- Summan av sålda radioapparater i EMEA.
- Summan av sålda radioapparater i Stilla havet.
- Enhetskostnad för radio i varje region.
- Försäljningspris för varje radio
- Försäljningspris - styckkostnad
De komplexa frågorna krävs för att hämta posterna ovan. Data Warehousing databaser använder olika typarkitektur både ur ett databasperspektiv och infrastrukturlager.
Rödskiftningskonfiguration

Rödförskjutning består av två typer av noder:
Enskild nod: En enda nod lagrar upp till 160 GB.
Multi-nod: Multi-nod är en nod som består av mer än en nod. Det är av två typer:
Den hanterar klientanslutningarna och tar emot frågor. En ledarnod tar emot frågorna från klientapplikationerna, analyserar frågorna och utvecklar exekveringsplanerna. Den koordinerar med den parallella exekveringen av dessa planer med beräkningsnoden och kombinerar mellanresultaten för alla noder, och returnerar sedan slutresultatet till klientapplikationen.
En beräkningsnod exekverar exekveringsplanerna, och sedan skickas mellanresultat till ledarnoden för aggregering innan de skickas tillbaka till klientapplikationen. Den kan ha upp till 128 beräkningsnoder.
Låt oss förstå begreppet ledarnod och beräkna noder genom ett exempel.

Redshift warehouse är en samling datorresurser som kallas noder, och dessa noder är organiserade i en grupp som kallas ett kluster. Varje kluster körs i en Redshift Engine som innehåller en eller flera databaser.
När du startar en Redshift-instans börjar den med en enda nod på 160 GB. När du vill växa kan du lägga till ytterligare noder för att dra fördel av parallell bearbetning. Du har en ledarnod som hanterar de flera noderna. Leadernod hanterar klientanslutningen såväl som beräkningsnoder. Den lagrar data i beräkningsnoder och utför frågan.
Varför Redshift är 10 gånger snabbare
Rödskiftning är 10 gånger snabbare på grund av följande skäl:
Istället för att lagra data som en rad rader, organiserar Amazon Redshift data efter kolumn. Radbaserade system är idealiska för transaktionsbearbetning medan kolumnbaserade system är idealiska för datalagring och analys, där frågor ofta involverar aggregat som utförs över stora datamängder. Eftersom endast kolumnerna som är involverade i frågorna bearbetas och kolumnära data lagras i ett lagringsmedium sekventiellt, kräver kolumnbaserade system färre I/O, vilket förbättrar frågeprestanda.
Kolumnära datalager kan komprimeras mycket mer än radbaserade datalager eftersom liknande data lagras sekventiellt på disken. Amazon Redshift använder flera komprimeringstekniker och kan ofta uppnå betydande komprimering i förhållande till traditionella relationsdatalager.
Amazon Redshift kräver inga index eller materialiserade vyer, så det kräver mindre utrymme än traditionella relationsdatabassystem. När du laddar en data till en tom tabell, samplar Amazon Redshift dina data automatiskt och väljer den mest lämpliga komprimeringstekniken.
Amazon Redshift distribuerar automatiskt data och laddar frågan över olika noder. En Amazon Redshift gör det enkelt att lägga till nya noder till ditt datalager, och detta gör att vi kan uppnå snabbare frågeprestanda när ditt datalager växer.
Rödskiftningsfunktioner
Funktioner för Redshift ges nedan:
topologier

Redshift är enkel att ställa in och använda. Du kan distribuera ett nytt datalager med bara några klick i AWS-konsolen, och Redshift tillhandahåller automatiskt infrastrukturen åt dig. I AWS är alla administrativa uppgifter automatiserade, såsom säkerhetskopiering och replikering, du måste fokusera på din data, inte på administrationen.
Redshift säkerhetskopierar automatiskt dina data till S3. Du kan också replikera ögonblicksbilderna i S3 i en annan region för eventuell katastrofåterställning.
Amazon Redshift är den mest kostnadseffektiva datalagertjänsten eftersom du bara behöver betala för det du använder.
Dess kostnader börjar med 0,25 USD per timme utan åtagande och inga förhandskostnader och kan skalas ut till 250 USD per terabyte och år.
Amazon Redshift är den enda datalagertjänsten som erbjuder On Demand-priser utan förskottskostnader, och den erbjuder även reserverad instansprissättning som sparar upp till 75 % genom att tillhandahålla 1-3 års löptid.
Du kan välja någon av de två noderna för att optimera rödförskjutningen.
Tät beräkningsnod kan skapa ett högpresterande datalager genom att använda snabba processorer, en stor mängd RAM-minne och solid-state-diskar.
Om du vill minska kostnaderna kan du använda tät lagringsnod. Det skapar ett kostnadseffektivt datalager genom att använda en större hårddisk.
Amazon Redshift skalar automatiskt upp eller ner noderna efter behovsändringarna. Med bara några klick i AWS-konsolen eller ett enda API-anrop kan du enkelt ändra antalet noder i ett datalager.
Det är en funktion i Redshift som låter dig köra frågorna mot exabyte av data i Amazon S3. Amazon S3 är en säker och kostnadseffektiv data för att lagra obegränsad data i ett öppet format.
Det är en funktion av Redshift innebär att flera frågor kan komma åt samma data i Amazon S3. Det låter dig köra frågorna över flera noder oavsett hur komplex en fråga är eller mängden data.
Amazon Redshift är det enda datalagret som används för att fråga Amazon S3-datasjön utan att ladda data. Detta ger flexibilitet genom att lagra data som ofta används i Redshift och ostrukturerad eller sällsynt data i Amazon S3.
Med ett par parameterinställningar kan du ställa in Redshift att använda SSL för att säkra din data. Du kan också aktivera kryptering, all data som skrivs till disken kommer att krypteras.
Amazon Redshift tillhandahåller kolumnär datalagring, komprimering och parallell bearbetning för att minska mängden I/O som behövs för att utföra frågor. Detta förbättrar frågeprestanda.