Denna handledning är en nybörjarvänlig guide för lära sig datastrukturer och algoritmer använder Python. I den här artikeln kommer vi att diskutera de inbyggda datastrukturerna som listor, tupler, ordböcker etc, och några användardefinierade datastrukturer som t.ex. länkade listor , träd , grafer , etc, och traversering samt sök- och sorteringsalgoritmer med hjälp av bra och välförklarade exempel och övningsfrågor.

Listor
Python-listor är ordnade samlingar av data precis som arrayer i andra programmeringsspråk. Det tillåter olika typer av element i listan. Implementeringen av Python List liknar Vectors i C++ eller ArrayList i JAVA. Den kostsamma operationen är att infoga eller ta bort elementet från början av listan eftersom alla element måste flyttas. Insättning och radering i slutet av listan kan också bli kostsamt i det fall det förallokerade minnet blir fullt.
Exempel: Skapa Python List
Python3 List = [1, 2, 3, 'GFG', 2.3] print(List)>
Produktion
[1, 2, 3, 'GFG', 2.3]>
Listelement kan nås av det tilldelade indexet. I python startindex för listan är en sekvens 0 och slutindexet är (om N element finns där) N-1.
Exempel: Python List Operations
Python3 # Creating a List with # the use of multiple values List = ['Geeks', 'For', 'Geeks'] print('
List containing multiple values: ') print(List) # Creating a Multi-Dimensional List # (By Nesting a list inside a List) List2 = [['Geeks', 'For'], ['Geeks']] print('
Multi-Dimensional List: ') print(List2) # accessing a element from the # list using index number print('Accessing element from the list') print(List[0]) print(List[2]) # accessing a element using # negative indexing print('Accessing element using negative indexing') # print the last element of list print(List[-1]) # print the third last element of list print(List[-3])> Produktion
List containing multiple values: ['Geeks', 'For', 'Geeks'] Multi-Dimensional List: [['Geeks', 'For'], ['Geeks']] Accessing element from the list Geeks Geeks Accessing element using negative indexing Geeks Geeks>
Tuple
Python-tuplar liknar listor men Tuples är oföränderlig i naturen, dvs när den väl har skapats kan den inte modifieras. Precis som en lista kan en Tuple också innehålla element av olika slag.
I Python skapas tupler genom att placera en sekvens av värden separerade med 'komma' med eller utan användning av parenteser för gruppering av datasekvensen.
Notera: För att skapa en tupel av ett element måste det finnas ett efterföljande kommatecken. Till exempel kommer (8,) att skapa en tupel som innehåller 8 som element.
Exempel: Python Tuple Operations
Python3 # Creating a Tuple with # the use of Strings Tuple = ('Geeks', 'For') print('
Tuple with the use of String: ') print(Tuple) # Creating a Tuple with # the use of list list1 = [1, 2, 4, 5, 6] print('
Tuple using List: ') Tuple = tuple(list1) # Accessing element using indexing print('First element of tuple') print(Tuple[0]) # Accessing element from last # negative indexing print('
Last element of tuple') print(Tuple[-1]) print('
Third last element of tuple') print(Tuple[-3])> Produktion
Tuple with the use of String: ('Geeks', 'For') Tuple using List: First element of tuple 1 Last element of tuple 6 Third last element of tuple 4> Uppsättning
Python set är en föränderlig samling av data som inte tillåter någon duplicering. Uppsättningar används i princip för att inkludera medlemskapstestning och eliminera dubbla poster. Datastrukturen som används i detta är Hashing, en populär teknik för att utföra infogning, radering och genomgång i O(1) i genomsnitt.
Om flera värden finns på samma indexposition, läggs värdet till den indexpositionen för att bilda en länkad lista. I implementeras CPython-uppsättningar med hjälp av en ordbok med dummyvariabler, där nyckelväsen medlemmarna ställer in med större optimeringar av tidskomplexiteten.
Set Implementering:

Uppsättningar med många operationer på en enda hashtabell:
sträng till int i java

Exempel: Python Set Operations
Python3 # Creating a Set with # a mixed type of values # (Having numbers and strings) Set = set([1, 2, 'Geeks', 4, 'For', 6, 'Geeks']) print('
Set with the use of Mixed Values') print(Set) # Accessing element using # for loop print('
Elements of set: ') for i in Set: print(i, end =' ') print() # Checking the element # using in keyword print('Geeks' in Set)> Produktion
Set with the use of Mixed Values {1, 2, 4, 6, 'For', 'Geeks'} Elements of set: 1 2 4 6 For Geeks True> Frysta set
Frysta set i Python är oföränderliga objekt som endast stöder metoder och operatorer som producerar ett resultat utan att påverka den frysta uppsättningen eller uppsättningarna som de tillämpas på. Även om element i en uppsättning kan ändras när som helst, förblir element i den frysta uppsättningen desamma efter att de skapats.
Exempel: Python Frozen set
Python3 # Same as {'a', 'b','c'} normal_set = set(['a', 'b','c']) print('Normal Set') print(normal_set) # A frozen set frozen_set = frozenset(['e', 'f', 'g']) print('
Frozen Set') print(frozen_set) # Uncommenting below line would cause error as # we are trying to add element to a frozen set # frozen_set.add('h')> Produktion
Normal Set {'a', 'b', 'c'} Frozen Set frozenset({'f', 'g', 'e'})> Sträng
Python strängar är den oföränderliga matrisen av byte som representerar Unicode-tecken. Python har ingen teckendatatyp, ett enda tecken är helt enkelt en sträng med längden 1.
Notera: Eftersom strängar är oföränderliga, kommer modifiering av en sträng att resultera i att en ny kopia skapas.
Exempel: Python Strings Operations
Python3 String = 'Welcome to GeeksForGeeks' print('Creating String: ') print(String) # Printing First character print('
First character of String is: ') print(String[0]) # Printing Last character print('
Last character of String is: ') print(String[-1])> Produktion
Creating String: Welcome to GeeksForGeeks First character of String is: W Last character of String is: s>
Lexikon
Python ordbok är en oordnad samling data som lagrar data i formatet nyckel:värdepar. Det är som hashtabeller på vilket annat språk som helst med tidskomplexiteten O(1). Indexering av Python Dictionary görs med hjälp av nycklar. Dessa är av vilken hashbar typ som helst, dvs ett objekt vars aldrig kan ändras som strängar, siffror, tupler, etc. Vi kan skapa en ordbok genom att använda klammerparenteser ({}) eller ordboksförståelse.
Exempel: Python Dictionary Operations
Python3 # Creating a Dictionary Dict = {'Name': 'Geeks', 1: [1, 2, 3, 4]} print('Creating Dictionary: ') print(Dict) # accessing a element using key print('Accessing a element using key:') print(Dict['Name']) # accessing a element using get() # method print('Accessing a element using get:') print(Dict.get(1)) # creation using Dictionary comprehension myDict = {x: x**2 for x in [1,2,3,4,5]} print(myDict)> Produktion
Creating Dictionary: {'Name': 'Geeks', 1: [1, 2, 3, 4]} Accessing a element using key: Geeks Accessing a element using get: [1, 2, 3, 4] {1: 1, 2: 4, 3: 9, 4: 16, 5: 25}> Matris
En matris är en 2D-array där varje element är av strikt samma storlek. För att skapa en matris kommer vi att använda NumPy-paket .
Exempel: Python NumPy Matrix Operations
Python3 import numpy as np a = np.array([[1,2,3,4],[4,55,1,2], [8,3,20,19],[11,2,22,21]]) m = np.reshape(a,(4, 4)) print(m) # Accessing element print('
Accessing Elements') print(a[1]) print(a[2][0]) # Adding Element m = np.append(m,[[1, 15,13,11]],0) print('
Adding Element') print(m) # Deleting Element m = np.delete(m,[1],0) print('
Deleting Element') print(m)> Produktion
[[ 1 2 3 4] [ 4 55 1 2] [ 8 3 20 19] [11 2 22 21]] Accessing Elements [ 4 55 1 2] 8 Adding Element [[ 1 2 3 4] [ 4 55 1 2] [ 8 3 20 19] [11 2 22 21] [ 1 15 13 11]] Deleting Element [[ 1 2 3 4] [ 8 3 20 19] [11 2 22 21] [ 1 15 13 11]]>
Bytearray
Python Bytearray ger en föränderlig sekvens av heltal i intervallet 0 <= x < 256.
Exempel: Python Bytearray Operations
Python3 # Creating bytearray a = bytearray((12, 8, 25, 2)) print('Creating Bytearray:') print(a) # accessing elements print('
Accessing Elements:', a[1]) # modifying elements a[1] = 3 print('
After Modifying:') print(a) # Appending elements a.append(30) print('
After Adding Elements:') print(a)> Produktion
Creating Bytearray: bytearray(b'x0cx08x19x02') Accessing Elements: 8 After Modifying: bytearray(b'x0cx03x19x02') After Adding Elements: bytearray(b'x0cx03x19x02x1e')>
Länkad lista
A länkad lista är en linjär datastruktur, i vilken elementen inte lagras på sammanhängande minnesplatser. Elementen i en länkad lista är länkade med hjälp av pekare som visas i bilden nedan:

En länkad lista representeras av en pekare till den första noden i den länkade listan. Den första noden kallas huvudet. Om den länkade listan är tom är värdet på huvudet NULL. Varje nod i en lista består av minst två delar:
- Data
- Pekare (eller referens) till nästa nod
Exempel: Definiera länkad lista i Python
Python3 # Node class class Node: # Function to initialize the node object def __init__(self, data): self.data = data # Assign data self.next = None # Initialize # next as null # Linked List class class LinkedList: # Function to initialize the Linked # List object def __init__(self): self.head = None>
Låt oss skapa en enkel länkad lista med 3 noder.
Python3 # A simple Python program to introduce a linked list # Node class class Node: # Function to initialise the node object def __init__(self, data): self.data = data # Assign data self.next = None # Initialize next as null # Linked List class contains a Node object class LinkedList: # Function to initialize head def __init__(self): self.head = None # Code execution starts here if __name__=='__main__': # Start with the empty list llist = LinkedList() llist.head = Node(1) second = Node(2) third = Node(3) ''' Three nodes have been created. We have references to these three blocks as head, second and third llist.head second third | | | | | | +----+------+ +----+------+ +----+------+ | 1 | None | | 2 | None | | 3 | None | +----+------+ +----+------+ +----+------+ ''' llist.head.next = second; # Link first node with second ''' Now next of first Node refers to second. So they both are linked. llist.head second third | | | | | | +----+------+ +----+------+ +----+------+ | 1 | o-------->| 2 | null | | 3 | null | +----+------+ +----+------+ +----+------+ ''' second.next = tredje ; # Länka andra nod med tredje nod ''' Nu hänvisar nästa av andra nod till tredje. Så alla tre noderna är länkade. llist.head andra tredje | | | | | | +----+------+ +----+------+ +----+------+ | 1 | o-------->| 2 | o-------->| 3 | null | +----+------+ +----+------+ +----+------+ '''>
Länkad listövergång
I det tidigare programmet har vi skapat en enkel länkad lista med tre noder. Låt oss gå igenom den skapade listan och skriva ut data för varje nod. För genomgång, låt oss skriva en allmän funktion printList() som skriver ut vilken lista som helst.
Python3 # A simple Python program for traversal of a linked list # Node class class Node: # Function to initialise the node object def __init__(self, data): self.data = data # Assign data self.next = None # Initialize next as null # Linked List class contains a Node object class LinkedList: # Function to initialize head def __init__(self): self.head = None # This function prints contents of linked list # starting from head def printList(self): temp = self.head while (temp): print (temp.data) temp = temp.next # Code execution starts here if __name__=='__main__': # Start with the empty list llist = LinkedList() llist.head = Node(1) second = Node(2) third = Node(3) llist.head.next = second; # Link first node with second second.next = third; # Link second node with the third node llist.printList()>
Produktion
1 2 3>
Fler artiklar om länkad lista
- Infogning av länkad lista
- Radering av länkad lista (ta bort en given nyckel)
- Radering av länkad lista (ta bort en nyckel vid en given position)
- Hitta längden på en länkad lista (iterativ och rekursiv)
- Sök efter ett element i en länkad lista (iterativ och rekursiv)
- N:te nod från slutet av en länkad lista
- Omvänd en länkad lista

Funktionerna associerade med stack är:
- tomma() – Returnerar om stacken är tom – Tidskomplexitet: O(1)
- storlek() – Returnerar stackens storlek – Tidskomplexitet: O(1)
- topp() - Returnerar en referens till det översta elementet i stacken – Tidskomplexitet: O(1)
- push(a) – Infogar elementet 'a' överst i stacken – Tidskomplexitet: O(1)
- pop() – Tar bort det översta elementet i stacken – Tidskomplexitet: O(1)
stack = [] # append() function to push # element in the stack stack.append('g') stack.append('f') stack.append('g') print('Initial stack') print(stack) # pop() function to pop # element from stack in # LIFO order print('
Elements popped from stack:') print(stack.pop()) print(stack.pop()) print(stack.pop()) print('
Stack after elements are popped:') print(stack) # uncommenting print(stack.pop()) # will cause an IndexError # as the stack is now empty> Produktion
Initial stack ['g', 'f', 'g'] Elements popped from stack: g f g Stack after elements are popped: []>
Fler artiklar om Stack
- Infix till Postfix-konvertering med Stack
- Prefix till Infix-konvertering
- Prefix till Postfix-konvertering
- Postfix till prefixkonvertering
- Postfix till Infix
- Kontrollera om det finns balanserade parenteser i ett uttryck
- Utvärdering av Postfix Expression
Som en stack, den kö är en linjär datastruktur som lagrar objekt på ett First In First Out (FIFO) sätt. Med en kö tas det senast tillagda objektet bort först. Ett bra exempel på kö är varje kö av konsumenter till en resurs där konsumenten som kom först serveras först.

Operationer associerade med kö är:
- Kö: Lägger till ett objekt i kön. Om kön är full, sägs det vara ett överflödestillstånd – Tidskomplexitet: O(1)
- Följaktligen: Tar bort ett objekt från kön. Föremålen skjuts i samma ordning som de skjuts. Om kön är tom, sägs det vara ett underflödestillstånd – Tidskomplexitet: O(1)
- Främre: Hämta det främre föremålet från kön – Tidskomplexitet: O(1)
- Bak: Hämta det sista föremålet från kön – Tidskomplexitet: O(1)
# Initializing a queue queue = [] # Adding elements to the queue queue.append('g') queue.append('f') queue.append('g') print('Initial queue') print(queue) # Removing elements from the queue print('
Elements dequeued from queue') print(queue.pop(0)) print(queue.pop(0)) print(queue.pop(0)) print('
Queue after removing elements') print(queue) # Uncommenting print(queue.pop(0)) # will raise and IndexError # as the queue is now empty> Produktion
Initial queue ['g', 'f', 'g'] Elements dequeued from queue g f g Queue after removing elements []>
Fler artiklar om Queue
- Implementera kö med stackar
- Implementera Stack med hjälp av köer
- Implementera en stack med en enda kö
Prioriterad kö
Prioriterade köer är abstrakta datastrukturer där varje data/värde i kön har en viss prioritet. Till exempel hos flygbolag kommer bagage med titeln Business eller First-class tidigare än resten. Priority Queue är en förlängning av kön med följande egenskaper.
- Ett element med hög prioritet tas ur kö före ett element med låg prioritet.
- Om två element har samma prioritet serveras de enligt deras ordning i kön.
# A simple implementation of Priority Queue # using Queue. class PriorityQueue(object): def __init__(self): self.queue = [] def __str__(self): return ' '.join([str(i) for i in self.queue]) # for checking if the queue is empty def isEmpty(self): return len(self.queue) == 0 # for inserting an element in the queue def insert(self, data): self.queue.append(data) # for popping an element based on Priority def delete(self): try: max = 0 for i in range(len(self.queue)): if self.queue[i]>self.queue[max]: max = i item = self.queue[max] del self.queue[max] returnera objekt utom IndexError: print() exit() if __name__ == '__main__': myQueue = PriorityQueue( ) myQueue.insert(12) myQueue.insert(1) myQueue.insert(14) myQueue.insert(7) print(myQueue) men inte myQueue.isEmpty(): print(myQueue.delete())>
Produktion
12 1 14 7 14 12 7 1>
Högen
heapq-modul i Python tillhandahåller högdatastrukturen som huvudsakligen används för att representera en prioritetskö. Egenskapen för denna datastruktur är att den alltid ger det minsta elementet (minsta hög) när elementet poppas. Närhelst element trycks eller skjuts upp bibehålls högstrukturen. Heap[0]-elementet returnerar också det minsta elementet varje gång. Det stöder extrahering och infogning av det minsta elementet i O(log n) gånger.
I allmänhet kan heaps vara av två typer:
- Max-Heap: I en Max-Heap måste nyckeln som finns vid rotnoden vara störst bland nycklarna som finns hos alla dess barn. Samma egenskap måste vara rekursivt sann för alla underträd i det binära trädet.
- Min-hög: I en Min-Heap måste nyckeln som finns vid rotnoden vara minimum bland nycklarna som finns hos alla dess barn. Samma egenskap måste vara rekursivt sann för alla underträd i det binära trädet.

# importing 'heapq' to implement heap queue import heapq # initializing list li = [5, 7, 9, 1, 3] # using heapify to convert list into heap heapq.heapify(li) # printing created heap print ('The created heap is : ',end='') print (list(li)) # using heappush() to push elements into heap # pushes 4 heapq.heappush(li,4) # printing modified heap print ('The modified heap after push is : ',end='') print (list(li)) # using heappop() to pop smallest element print ('The popped and smallest element is : ',end='') print (heapq.heappop(li))> Produktion
The created heap is : [1, 3, 9, 7, 5] The modified heap after push is : [1, 3, 4, 7, 5, 9] The popped and smallest element is : 1>
Fler artiklar om Heap
- Binär hög
- K’th största element i en array
- K'th minsta/största element i osorterad array
- Sortera en nästan sorterad array
- K-th Största Summa Sammanhängande Subarray
- Minsta summa av två tal bildade av siffror i en matris
Ett träd är en hierarkisk datastruktur som ser ut som bilden nedan -
tree ---- j <-- root / f k / a h z <-- leaves>
Trädets översta nod kallas roten medan de nedersta noderna eller noderna utan barn kallas bladnoder. Noderna som är direkt under en nod kallas dess barn och noderna som är direkt ovanför något kallas dess förälder.
A binärt träd är ett träd vars element kan få nästan två barn. Eftersom varje element i ett binärt träd bara kan ha två barn, brukar vi kalla dem för vänster och höger barn. En binär trädnod innehåller följande delar.
- Data
- Pekare till vänster barn
- Pekare till rätt barn
Exempel: Definiera nodklass
Python3 # A Python class that represents an individual node # in a Binary Tree class Node: def __init__(self,key): self.left = None self.right = None self.val = key>
Låt oss nu skapa ett träd med 4 noder i Python. Låt oss anta att trädstrukturen ser ut som nedan -
tree ---- 1 <-- root / 2 3 / 4>
Exempel: Lägga till data i trädet
Python3 # Python program to introduce Binary Tree # A class that represents an individual node in a # Binary Tree class Node: def __init__(self,key): self.left = None self.right = None self.val = key # create root root = Node(1) ''' following is the tree after above statement 1 / None None''' root.left = Node(2); root.right = Node(3); ''' 2 and 3 become left and right children of 1 1 / 2 3 / / None None None None''' root.left.left = Node(4); '''4 becomes left child of 2 1 / 2 3 / / 4 None None None / None None'''>
Traversal av träd
Träd kan korsas på olika sätt. Följande är de allmänt använda sätten att korsa träd. Låt oss betrakta trädet nedan -
tree ---- 1 <-- root / 2 3 / 4 5>
Depth First Traversals:
- Inordning (vänster, rot, höger): 4 2 5 1 3
- Förbeställning (rot, vänster, höger): 1 2 4 5 3
- Postorder (vänster, höger, rot): 4 5 2 3 1
Algorithm Inorder(träd)
python eller
- Gå igenom det vänstra underträdet, d.v.s. anrop Inorder (vänster-underträd)
- Besök roten.
- Gå igenom det högra underträdet, d.v.s. anrop Inorder (höger-underträdet)
Algoritm förbeställning (träd)
- Besök roten.
- Gå igenom det vänstra underträdet, d.v.s. ring Preorder (vänster-underträd)
- Gå igenom det högra underträdet, d.v.s. anropa Preorder (höger-underträdet)
Algorithm Postorder(tree)
- Gå igenom det vänstra underträdet, d.v.s. anrop Postorder (vänster-underträd)
- Gå igenom det högra underträdet, d.v.s. anrop Postorder (höger-underträdet)
- Besök roten.
# Python program to for tree traversals # A class that represents an individual node in a # Binary Tree class Node: def __init__(self, key): self.left = None self.right = None self.val = key # A function to do inorder tree traversal def printInorder(root): if root: # First recur on left child printInorder(root.left) # then print the data of node print(root.val), # now recur on right child printInorder(root.right) # A function to do postorder tree traversal def printPostorder(root): if root: # First recur on left child printPostorder(root.left) # the recur on right child printPostorder(root.right) # now print the data of node print(root.val), # A function to do preorder tree traversal def printPreorder(root): if root: # First print the data of node print(root.val), # Then recur on left child printPreorder(root.left) # Finally recur on right child printPreorder(root.right) # Driver code root = Node(1) root.left = Node(2) root.right = Node(3) root.left.left = Node(4) root.left.right = Node(5) print('Preorder traversal of binary tree is') printPreorder(root) print('
Inorder traversal of binary tree is') printInorder(root) print('
Postorder traversal of binary tree is') printPostorder(root)> Produktion
Preorder traversal of binary tree is 1 2 4 5 3 Inorder traversal of binary tree is 4 2 5 1 3 Postorder traversal of binary tree is 4 5 2 3 1>
Tidskomplexitet – O(n)
Bredth-First eller Level Order Traversal
Nivåordningsövergång av ett träd är bredd-första traversering för trädet. Nivåordningens genomgång av ovanstående träd är 1 2 3 4 5.
För varje nod besöks först noden och sedan placeras dess undernoder i en FIFO-kö. Nedan är algoritmen för detsamma –
- Skapa en tom kö q
- temp_node = rot /*börja från rot*/
- Loop medan temp_node inte är NULL
- skriv ut temp_node->data.
- Ställ temp_nodes barn (först vänster sedan höger barn) till q
- Ta bort en nod från q
# Python program to print level # order traversal using Queue # A node structure class Node: # A utility function to create a new node def __init__(self ,key): self.data = key self.left = None self.right = None # Iterative Method to print the # height of a binary tree def printLevelOrder(root): # Base Case if root is None: return # Create an empty queue # for level order traversal queue = [] # Enqueue Root and initialize height queue.append(root) while(len(queue)>0): # Skriv ut framför kön och # ta bort den från kö print (queue[0].data) node = queue.pop(0) # Kö vänster underordnad om node.left inte är Ingen: queue.append(node.left ) # Enqueue right child om node.right inte är Ingen: queue.append(node.right) # Drivrutin Program för att testa ovanstående funktion root = Node(1) root.left = Node(2) root.right = Node(3) root.left.left = Nod(4) root.left.right = Nod(5) print ('Nivåordningsgenomgång av binärt träd är -') printLevelOrder(root)> Produktion
Level Order Traversal of binary tree is - 1 2 3 4 5>
Tidskomplexitet: O(n)
Fler artiklar om Binary Tree
- Insättning i ett binärt träd
- Borttagning i ett binärt träd
- Inorder Tree Traversal utan rekursion
- Beställ Tree Traversal utan rekursion och utan stack!
- Skriv ut Postorder genomgång från givna Inorder och Preorder genomgångar
- Hitta efterbeställningsgenomgång av BST från förbeställningsgenomgång
Binärt sökträd är en nodbaserad binär träddatastruktur som har följande egenskaper:
- Det vänstra underträdet i en nod innehåller endast noder med nycklar som är mindre än nodens nyckel.
- Det högra underträdet i en nod innehåller endast noder med nycklar som är större än nodens nyckel.
- Det vänstra och högra underträdet måste också vara ett binärt sökträd.

Ovanstående egenskaper hos det binära sökträdet ger en ordning mellan nycklar så att operationer som sökning, minimum och maximum kan göras snabbt. Om det inte finns någon beställning kan vi behöva jämföra varje nyckel för att söka efter en given nyckel.
Sökande element
- Börja från roten.
- Jämför sökelementet med rot, om det är mindre än rot, återfall för vänster, annars återfall för höger.
- Om elementet att söka hittas någonstans, returnera true, annars returnerar false.
# A utility function to search a given key in BST def search(root,key): # Base Cases: root is null or key is present at root if root is None or root.val == key: return root # Key is greater than root's key if root.val < key: return search(root.right,key) # Key is smaller than root's key return search(root.left,key)>
Insättning av nyckel
- Börja från roten.
- Jämför infogningselementet med rot, om det är mindre än rot, återfall för vänster, annars återfall för höger.
- När du har nått slutet sätter du bara in den noden till vänster (om mindre än strömmen) annars till höger.
# Python program to demonstrate # insert operation in binary search tree # A utility class that represents # an individual node in a BST class Node: def __init__(self, key): self.left = None self.right = None self.val = key # A utility function to insert # a new node with the given key def insert(root, key): if root is None: return Node(key) else: if root.val == key: return root elif root.val < key: root.right = insert(root.right, key) else: root.left = insert(root.left, key) return root # A utility function to do inorder tree traversal def inorder(root): if root: inorder(root.left) print(root.val) inorder(root.right) # Driver program to test the above functions # Let us create the following BST # 50 # / # 30 70 # / / # 20 40 60 80 r = Node(50) r = insert(r, 30) r = insert(r, 20) r = insert(r, 40) r = insert(r, 70) r = insert(r, 60) r = insert(r, 80) # Print inorder traversal of the BST inorder(r)>
Produktion
20 30 40 50 60 70 80>
Fler artiklar om Binary Search Tree
- Binärt sökträd – Delete Key
- Konstruera BST från given förbeställnings-traversal | Set 1
- Konvertering av binärt träd till binärt sökträd
- Hitta noden med lägsta värde i ett binärt sökträd
- Ett program för att kontrollera om ett binärt träd är BST eller inte
A Graf är en olinjär datastruktur som består av noder och kanter. Noderna kallas ibland även för hörn och kanterna är linjer eller bågar som förbinder två valfria noder i grafen. Mer formellt kan en graf definieras som en graf som består av en ändlig uppsättning av hörn (eller noder) och en uppsättning kanter som förbinder ett par noder.

I grafen ovan är uppsättningen av hörn V = {0,1,2,3,4} och uppsättningen av kanter E = {01, 12, 23, 34, 04, 14, 13}. Följande två är de mest använda representationerna av en graf.
- Adjacency matris
- Adjacency List
Adjacency matris
Adjacency Matrix är en 2D-matris med storleken V x V där V är antalet hörn i en graf. Låt 2D-matrisen vara adj[][], en lucka adj[i][j] = 1 indikerar att det finns en kant från vertex i till vertex j. Närliggande matris för en oriktad graf är alltid symmetrisk. Adjacency Matrix används också för att representera viktade grafer. Om adj[i][j] = w, så finns det en kant från vertex i till vertex j med vikt w.
Python3 # A simple representation of graph using Adjacency Matrix class Graph: def __init__(self,numvertex): self.adjMatrix = [[-1]*numvertex for x in range(numvertex)] self.numvertex = numvertex self.vertices = {} self.verticeslist =[0]*numvertex def set_vertex(self,vtx,id): if 0<=vtx<=self.numvertex: self.vertices[id] = vtx self.verticeslist[vtx] = id def set_edge(self,frm,to,cost=0): frm = self.vertices[frm] to = self.vertices[to] self.adjMatrix[frm][to] = cost # for directed graph do not add this self.adjMatrix[to][frm] = cost def get_vertex(self): return self.verticeslist def get_edges(self): edges=[] for i in range (self.numvertex): for j in range (self.numvertex): if (self.adjMatrix[i][j]!=-1): edges.append((self.verticeslist[i],self.verticeslist[j],self.adjMatrix[i][j])) return edges def get_matrix(self): return self.adjMatrix G =Graph(6) G.set_vertex(0,'a') G.set_vertex(1,'b') G.set_vertex(2,'c') G.set_vertex(3,'d') G.set_vertex(4,'e') G.set_vertex(5,'f') G.set_edge('a','e',10) G.set_edge('a','c',20) G.set_edge('c','b',30) G.set_edge('b','e',40) G.set_edge('e','d',50) G.set_edge('f','e',60) print('Vertices of Graph') print(G.get_vertex()) print('Edges of Graph') print(G.get_edges()) print('Adjacency Matrix of Graph') print(G.get_matrix())> Produktion
Vertices of Graph
['a', 'b', 'c', 'd', 'e', 'f']
Kanter av graf
[('a', 'c', 20), ('a', 'e', 10), ('b', 'c', 30), ('b', 'e', 40), ( 'c', 'a', 20), ('c', 'b', 30), ('d', 'e', 50), ('e', 'a', 10), ('e ', 'b', 40), ('e', 'd', 50), ('e', 'f', 60), ('f', 'e', 60)]
Adjacency Matrix of Graph
[[-1, -1, 20, -1, 10, -1], [-1, -1, 30, -1, 40, -1], [20, 30, -1, -1, -1 , -1], [-1, -1, -1, -1, 50, -1], [10, 40, -1, 50, -1, 60], [-1, -1, -1, -1, 60, -1]]
Adjacency List
En rad listor används. Storleken på arrayen är lika med antalet hörn. Låt arrayen vara en array[]. En inmatningsmatris[i] representerar listan över hörn som gränsar till det i:te hörnet. Denna representation kan också användas för att representera en viktad graf. Kanternas vikter kan representeras som listor med par. Följande är granskningslistan representation av grafen ovan.

# A class to represent the adjacency list of the node class AdjNode: def __init__(self, data): self.vertex = data self.next = None # A class to represent a graph. A graph # is the list of the adjacency lists. # Size of the array will be the no. of the # vertices 'V' class Graph: def __init__(self, vertices): self.V = vertices self.graph = [None] * self.V # Function to add an edge in an undirected graph def add_edge(self, src, dest): # Adding the node to the source node node = AdjNode(dest) node.next = self.graph[src] self.graph[src] = node # Adding the source node to the destination as # it is the undirected graph node = AdjNode(src) node.next = self.graph[dest] self.graph[dest] = node # Function to print the graph def print_graph(self): for i in range(self.V): print('Adjacency list of vertex {}
head'.format(i), end='') temp = self.graph[i] while temp: print(' ->{}'.format(temp.vertex), end='') temp = temp.next print('
') # Drivrutinsprogram till ovanstående grafklass om __name__ == '__main__' : V = 5 graph = Graph(V) graph.add_edge(0, 1) graph.add_edge(0, 4) graph.add_edge(1, 2) graph.add_edge(1, 3) graph.add_edge(1, 4) graph.add_edge(2, 3) graph.add_edge(3, 4) graph.print_graph()> Produktion
Adjacency list of vertex 0 head ->4 -> 1 Adjacency list av vertex 1 head -> 4 -> 3 -> 2 -> 0 Adjacency list of vertex 2 head -> 3 -> 1 Adjacency list of vertex 3 head -> 4 -> 2 -> 1 Adjacency lista över vertex 4 huvud -> 3 -> 1 -> 0>
Genomgång av graf
Breadth-First Search eller BFS
Bredth-First Traversal för en graf liknar Breadth-First Traversal av ett träd. Den enda haken här är att till skillnad från träd kan grafer innehålla cykler, så vi kan komma till samma nod igen. För att undvika att bearbeta en nod mer än en gång använder vi en boolesk besökt array. För enkelhetens skull antas det att alla hörn är nåbara från startpunkten.
Till exempel, i följande graf, börjar vi traversering från vertex 2. När vi kommer till vertex 0 letar vi efter alla intilliggande hörn av den. 2 är också en angränsande hörn på 0. Om vi inte markerar besökta hörn, kommer 2 att bearbetas igen och det blir en icke-avslutande process. En Breadth-First Traversal av följande graf är 2, 0, 3, 1.

# Python3 Program to print BFS traversal # from a given source vertex. BFS(int s) # traverses vertices reachable from s. from collections import defaultdict # This class represents a directed graph # using adjacency list representation class Graph: # Constructor def __init__(self): # default dictionary to store graph self.graph = defaultdict(list) # function to add an edge to graph def addEdge(self,u,v): self.graph[u].append(v) # Function to print a BFS of graph def BFS(self, s): # Mark all the vertices as not visited visited = [False] * (max(self.graph) + 1) # Create a queue for BFS queue = [] # Mark the source node as # visited and enqueue it queue.append(s) visited[s] = True while queue: # Dequeue a vertex from # queue and print it s = queue.pop(0) print (s, end = ' ') # Get all adjacent vertices of the # dequeued vertex s. If a adjacent # has not been visited, then mark it # visited and enqueue it for i in self.graph[s]: if visited[i] == False: queue.append(i) visited[i] = True # Driver code # Create a graph given in # the above diagram g = Graph() g.addEdge(0, 1) g.addEdge(0, 2) g.addEdge(1, 2) g.addEdge(2, 0) g.addEdge(2, 3) g.addEdge(3, 3) print ('Following is Breadth First Traversal' ' (starting from vertex 2)') g.BFS(2)> Produktion
Following is Breadth First Traversal (starting from vertex 2) 2 0 3 1>
Tidskomplexitet: O(V+E) där V är antalet hörn i grafen och E är antalet kanter i grafen.
Depth First Search eller DFS
Depth First Traversal för en graf liknar Depth First Traversal av ett träd. Den enda haken här är att till skillnad från träd kan grafer innehålla cykler, en nod kan besökas två gånger. För att undvika att bearbeta en nod mer än en gång, använd en boolesk besökt array.
Algoritm:
- Skapa en rekursiv funktion som tar nodens index och en besökt array.
- Markera den aktuella noden som besökt och skriv ut noden.
- Gå igenom alla intilliggande och omarkerade noder och anrop den rekursiva funktionen med indexet för den intilliggande noden.
# Python3 program to print DFS traversal # from a given graph from collections import defaultdict # This class represents a directed graph using # adjacency list representation class Graph: # Constructor def __init__(self): # default dictionary to store graph self.graph = defaultdict(list) # function to add an edge to graph def addEdge(self, u, v): self.graph[u].append(v) # A function used by DFS def DFSUtil(self, v, visited): # Mark the current node as visited # and print it visited.add(v) print(v, end=' ') # Recur for all the vertices # adjacent to this vertex for neighbour in self.graph[v]: if neighbour not in visited: self.DFSUtil(neighbour, visited) # The function to do DFS traversal. It uses # recursive DFSUtil() def DFS(self, v): # Create a set to store visited vertices visited = set() # Call the recursive helper function # to print DFS traversal self.DFSUtil(v, visited) # Driver code # Create a graph given # in the above diagram g = Graph() g.addEdge(0, 1) g.addEdge(0, 2) g.addEdge(1, 2) g.addEdge(2, 0) g.addEdge(2, 3) g.addEdge(3, 3) print('Following is DFS from (starting from vertex 2)') g.DFS(2)> Produktion
Following is DFS from (starting from vertex 2) 2 0 1 3>
Fler artiklar om graf
- Grafiska representationer med hjälp av set och hash
- Hitta Mother Vertex i en graf
- Iterativt djup första sökning
- Räkna antalet noder på given nivå i ett träd med hjälp av BFS
- Räkna alla möjliga vägar mellan två hörn
Processen där en funktion anropar sig själv direkt eller indirekt kallas rekursion och motsvarande funktion kallas a rekursiv funktion . Med hjälp av de rekursiva algoritmerna kan vissa problem lösas ganska enkelt. Exempel på sådana problem är Towers of Hanoi (TOH), Inorder/Preorder/Postorder Tree Traversals, DFS of Graph, etc.
Vad är bastillståndet vid rekursion?
I det rekursiva programmet ges lösningen på basfallet och lösningen av det större problemet uttrycks i termer av mindre problem.
def fact(n): # base case if (n <= 1) return 1 else return n*fact(n-1)>
I exemplet ovan definieras basfallet för n <= 1 och ett större värde på tal kan lösas genom att konvertera till ett mindre tills basfallet uppnås.
Hur tilldelas minne till olika funktionsanrop vid rekursion?
När någon funktion anropas från main(), allokeras minnet till den i stacken. En rekursiv funktion anropar sig själv, minnet för en anropad funktion allokeras ovanpå minnet som är allokerat till den anropande funktionen och en annan kopia av lokala variabler skapas för varje funktionsanrop. När basfallet uppnås returnerar funktionen sitt värde till den funktion som den anropas av och minnet avallokeras och processen fortsätter.
Låt oss ta exemplet på hur rekursion fungerar genom att ta en enkel funktion.
Python3 # A Python 3 program to # demonstrate working of # recursion def printFun(test): if (test < 1): return else: print(test, end=' ') printFun(test-1) # statement 2 print(test, end=' ') return # Driver Code test = 3 printFun(test)>
Produktion
3 2 1 1 2 3>
Minnesstacken har visats i diagrammet nedan.
Fler artiklar om Rekursion
- Rekursion
- Rekursion i Python
- Övningsfrågor för rekursion | Set 1
- Övningsfrågor för rekursion | Set 2
- Övningsfrågor för rekursion | Set 3
- Övningsfrågor för rekursion | Set 4
- Övningsfrågor för rekursion | Set 5
- Övningsfrågor för rekursion | Set 6
- Övningsfrågor för rekursion | Set 7
>>> Mer
Dynamisk programmering
Dynamisk programmering är främst en optimering över vanlig rekursion. Varhelst vi ser en rekursiv lösning som har upprepade anrop för samma ingångar, kan vi optimera den med hjälp av dynamisk programmering. Tanken är att helt enkelt lagra resultaten av delproblem, så att vi inte behöver räkna om dem vid behov senare. Denna enkla optimering reducerar tidskomplexiteten från exponentiell till polynom. Om vi till exempel skriver enkel rekursiv lösning för Fibonacci-tal får vi exponentiell tidskomplexitet och om vi optimerar den genom att lagra lösningar av delproblem minskar tidskomplexiteten till linjär.

Tabulering vs Memoisering
Det finns två olika sätt att lagra värdena så att värdena för ett delproblem kan återanvändas. Här kommer att diskutera två mönster för att lösa dynamiska programmeringsproblem (DP):
- Tabulering: Botten upp
- Memoisering: Top Down
Tabulering
Som namnet i sig antyder börjar man nerifrån och samlar på sig svar till toppen. Låt oss diskutera i termer av statsövergång.
Låt oss beskriva ett tillstånd för vårt DP-problem som är dp[x] med dp[0] som bastillstånd och dp[n] som vårt destinationstillstånd. Så vi måste hitta värdet för destinationstillstånd, dvs dp[n].
Om vi börjar vår övergång från vårt bastillstånd, dvs dp[0] och följer vår tillståndsövergångsrelation för att nå vårt destinationstillstånd dp[n], kallar vi det Bottom-Up-metoden eftersom det är ganska tydligt att vi började vår övergång från bottenbastillståndet och nådde det översta önskade tillståndet.
Nu, varför kallar vi det tabuleringsmetod?
För att veta detta, låt oss först skriva lite kod för att beräkna faktorialen för ett tal med hjälp av bottom-up-metoden. Återigen, som vår allmänna procedur för att lösa en DP, definierar vi först ett tillstånd. I det här fallet definierar vi ett tillstånd som dp[x], där dp[x] är att hitta faktorn för x.
Nu är det ganska uppenbart att dp[x+1] = dp[x] * (x+1)
# Tabulated version to find factorial x. dp = [0]*MAXN # base case dp[0] = 1; for i in range(n+1): dp[i] = dp[i-1] * i>
Memoisering
Återigen, låt oss beskriva det i termer av tillståndsövergång. Om vi behöver hitta värdet för något tillstånd säg dp[n] och istället för att utgå från bastillståndet som dp[0] frågar vi vårt svar från de stater som kan nå destinationstillståndet dp[n] efter tillståndsövergången förhållande, då är det top-down-modet för DP.
Här börjar vi vår resa från den översta destinationsstaten och beräknar dess svar genom att räkna in värdena för tillstånd som kan nå destinationsstaten, tills vi når det lägsta bastillståndet.
Återigen, låt oss skriva koden för det faktoriella problemet uppifrån och ner
# Memoized version to find factorial x. # To speed up we store the values # of calculated states # initialized to -1 dp[0]*MAXN # return fact x! def solve(x): if (x==0) return 1 if (dp[x]!=-1) return dp[x] return (dp[x] = x * solve(x-1))>

Fler artiklar om dynamisk programmering
- Optimal underbyggnadsfastighet
- Egenskap för överlappande delproblem
- Fibonacci-siffror
- Delmängd med summan delbar med m
- Maximal Summa ökande efterföljd
- Längsta gemensamma delsträng
Sökalgoritmer
Linjär sökning
- Börja från elementet längst till vänster i arr[] och en efter en jämför x med varje element i arr[]
- Om x matchar ett element, returnera indexet.
- Om x inte matchar något av elementen, returnera -1.

# Python3 code to linearly search x in arr[]. # If x is present then return its location, # otherwise return -1 def search(arr, n, x): for i in range(0, n): if (arr[i] == x): return i return -1 # Driver Code arr = [2, 3, 4, 10, 40] x = 10 n = len(arr) # Function call result = search(arr, n, x) if(result == -1): print('Element is not present in array') else: print('Element is present at index', result)> Produktion
Element is present at index 3>
Tidskomplexiteten för ovanstående algoritm är O(n).
För mer information, se Linjär sökning .
Binär sökning
Sök efter en sorterad matris genom att upprepade gånger dela sökintervallet på mitten. Börja med ett intervall som täcker hela arrayen. Om värdet på söknyckeln är mindre än objektet i mitten av intervallet, begränsa intervallet till den nedre halvan. Annars, smala av den till den övre halvan. Kontrollera upprepade gånger tills värdet hittas eller intervallet är tomt.

# Python3 Program for recursive binary search. # Returns index of x in arr if present, else -1 def binarySearch (arr, l, r, x): # Check base case if r>= l: mid = l + (r - l) // 2 # Om elementet finns i mitten om arr[mid] == x: return mid # Om elementet är mindre än mitten, så kan # bara finnas närvarande i vänster undergrupp elif arr[mid]> x: return binarySearch(arr, l, mid-1, x) # Annars kan elementet bara finnas # i höger underarray annars: return binarySearch(arr, mid + 1, r, x ) else: # Element finns inte i arrayreturen -1 # Driver Code arr = [ 2, 3, 4, 10, 40 ] x = 10 # Funktionsanropsresultat = binarySearch(arr, 0, len(arr)-1 , x) om resultat != -1: skriv ut ('Element finns vid index % d' % resultat) annars: skriv ut ('Element finns inte i array')> Produktion
Element is present at index 3>
Tidskomplexiteten för ovanstående algoritm är O(log(n)).
För mer information, se Binär sökning .
Sorteringsalgoritmer
Urval Sortera
De urval sortera algoritmen sorterar en array genom att upprepade gånger hitta minimielementet (med tanke på stigande ordning) från osorterad del och sätta det i början. I varje iteration av urvalssortering, plockas minimielementet (med tanke på stigande ordning) från den osorterade subarrayen och flyttas till den sorterade subarrayen.
Flödesschema över urvalssorten:
# Python program for implementation of Selection # Sort import sys A = [64, 25, 12, 22, 11] # Traverse through all array elements for i in range(len(A)): # Find the minimum element in remaining # unsorted array min_idx = i for j in range(i+1, len(A)): if A[min_idx]>A[j]: min_idx = j # Byt ut det minsta elementet som hittades med # det första elementet A[i], A[min_idx] = A[min_idx], A[i] # Drivrutinskod för att testa ovanför utskrift ('Sorterad array ') för i inom intervallet(len(A)): print('%d' %A[i]),> Produktion
Sorted array 11 12 22 25 64>
Tidskomplexitet: På2) eftersom det finns två kapslade slingor.
Hjälputrymme: O(1)
Bubblesort
Bubblesort är den enklaste sorteringsalgoritmen som fungerar genom att upprepade gånger byta de intilliggande elementen om de är i fel ordning.
Illustration:

# Python program for implementation of Bubble Sort def bubbleSort(arr): n = len(arr) # Traverse through all array elements for i in range(n): # Last i elements are already in place for j in range(0, n-i-1): # traverse the array from 0 to n-i-1 # Swap if the element found is greater # than the next element if arr[j]>arr[j+1] : arr[j], arr[j+1] = arr[j+1], arr[j] # Förarkod att testa över arr = [64, 34, 25, 12, 22, 11 , 90] bubbleSort(arr) print ('Sorterad array är:') för i inom intervallet(len(arr)): print ('%d' %arr[i]),> Produktion
Sorted array is: 11 12 22 25 34 64 90>
Tidskomplexitet: På2)
Insättningssortering
För att sortera en matris av storlek n i stigande ordning med hjälp av insättningssort :
- Iterera från arr[1] till arr[n] över arrayen.
- Jämför det nuvarande elementet (nyckeln) med dess föregångare.
- Om nyckelelementet är mindre än dess föregångare, jämför det med elementen tidigare. Flytta de större elementen en position upp för att göra plats för det utbytta elementet.
Illustration:

# Python program for implementation of Insertion Sort # Function to do insertion sort def insertionSort(arr): # Traverse through 1 to len(arr) for i in range(1, len(arr)): key = arr[i] # Move elements of arr[0..i-1], that are # greater than key, to one position ahead # of their current position j = i-1 while j>= 0 och tangent< arr[j] : arr[j + 1] = arr[j] j -= 1 arr[j + 1] = key # Driver code to test above arr = [12, 11, 13, 5, 6] insertionSort(arr) for i in range(len(arr)): print ('% d' % arr[i])> Produktion
5 6 11 12 13>
Tidskomplexitet: På2))
heltal jämfört med java
Sammanfoga sortering
Som QuickSort, Sammanfoga sortering är en Divide and Conquer-algoritm. Den delar upp inmatningsmatrisen i två halvor, kallar sig för de två halvorna och slår sedan samman de två sorterade halvorna. Merge()-funktionen används för att slå samman två halvor. Sammanfogningen (arr, l, m, r) är en nyckelprocess som antar att arr[l..m] och arr[m+1..r] sorteras och slår samman de två sorterade sub-arrayerna till en.
MergeSort(arr[], l, r) If r>l 1. Hitta mittpunkten för att dela upp arrayen i två halvor: mitten m = l+ (r-l)/2 2. Anrop sammanfogningSortera för första halvan: Anrop sammanfogningsSortera(arr, l, m) 3. Anrop sammanfogningSortera för andra halvan: Anrop mergeSort(arr, m+1, r) 4. Slå samman de två halvorna sorterade i steg 2 och 3: Ring merge(arr, l, m, r)>
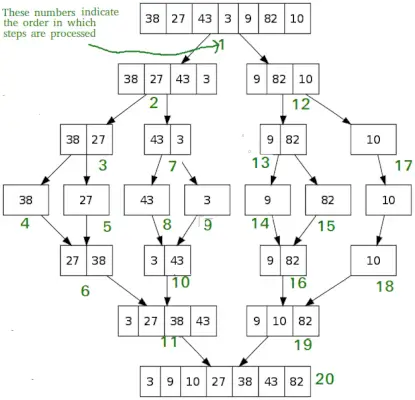
# Python program for implementation of MergeSort def mergeSort(arr): if len(arr)>1: # Hitta mitten av arrayen mid = len(arr)//2 # Dela arrayelementen L = arr[:mid] # i 2 halvor R = arr[mid:] # Sortering av den första halvan mergeSort(L) # Sortera den andra halvan mergeSort(R) i = j = k = 0 # Kopiera data till temporära arrayer L[] och R[] medan i< len(L) and j < len(R): if L[i] < R[j]: arr[k] = L[i] i += 1 else: arr[k] = R[j] j += 1 k += 1 # Checking if any element was left while i < len(L): arr[k] = L[i] i += 1 k += 1 while j < len(R): arr[k] = R[j] j += 1 k += 1 # Code to print the list def printList(arr): for i in range(len(arr)): print(arr[i], end=' ') print() # Driver Code if __name__ == '__main__': arr = [12, 11, 13, 5, 6, 7] print('Given array is', end='
') printList(arr) mergeSort(arr) print('Sorted array is: ', end='
') printList(arr)> Produktion
Given array is 12 11 13 5 6 7 Sorted array is: 5 6 7 11 12 13>
Tidskomplexitet: O(n(logn))
QuickSort
Som Merge Sort, QuickSort är en Divide and Conquer-algoritm. Den väljer ett element som pivot och partitionerar den givna arrayen runt den valda pivoten. Det finns många olika versioner av quickSort som väljer pivot på olika sätt.
Välj alltid det första elementet som pivot.
- Välj alltid det sista elementet som pivot (implementerat nedan)
- Välj ett slumpmässigt element som pivot.
- Välj median som pivot.
Nyckelprocessen i quickSort är partition(). Mål för partitioner är, givet en array och ett element x i array som pivot, sätta x i sin korrekta position i sorterad array och sätta alla mindre element (mindre än x) före x, och sätta alla större element (större än x) efter x. Allt detta bör göras i linjär tid.
/* low -->Startindex, hög --> Slutindex */ quickSort(arr[], låg, hög) { if (låg { /* pi är partitioneringsindex, arr[pi] är nu på rätt plats */ pi = partition(arr, low, high); quickSort(arr, low, pi - 1); // Before pi quickSort(arr, pi + 1, high } } 
Partitionsalgoritm
Det kan finnas många sätt att göra partition, följande pseudokod använder metoden som anges i CLRS bok. Logiken är enkel, vi utgår från elementet längst till vänster och håller reda på index för mindre (eller lika med) element som i. Om vi hittar ett mindre element när vi korsar, byter vi aktuellt element med arr[i]. Annars ignorerar vi nuvarande element.
# Python3 implementation of QuickSort # This Function handles sorting part of quick sort # start and end points to first and last element of # an array respectively def partition(start, end, array): # Initializing pivot's index to start pivot_index = start pivot = array[pivot_index] # This loop runs till start pointer crosses # end pointer, and when it does we swap the # pivot with element on end pointer while start < end: # Increment the start pointer till it finds an # element greater than pivot while start < len(array) and array[start] <= pivot: start += 1 # Decrement the end pointer till it finds an # element less than pivot while array[end]>pivot: end -= 1 # Om start och slut inte har korsat varandra, # byt siffror på start och slut if(start< end): array[start], array[end] = array[end], array[start] # Swap pivot element with element on end pointer. # This puts pivot on its correct sorted place. array[end], array[pivot_index] = array[pivot_index], array[end] # Returning end pointer to divide the array into 2 return end # The main function that implements QuickSort def quick_sort(start, end, array): if (start < end): # p is partitioning index, array[p] # is at right place p = partition(start, end, array) # Sort elements before partition # and after partition quick_sort(start, p - 1, array) quick_sort(p + 1, end, array) # Driver code array = [ 10, 7, 8, 9, 1, 5 ] quick_sort(0, len(array) - 1, array) print(f'Sorted array: {array}')>
Produktion Sorted array: [1, 5, 7, 8, 9, 10]>
Tidskomplexitet: O(n(logn))
ShellSort
ShellSort är främst en variant av Insertion Sort. Vid insättningssortering flyttar vi element endast en position framåt. När ett element ska flyttas långt fram är många rörelser inblandade. Tanken med shellSort är att tillåta utbyte av avlägsna föremål. I shellSort gör vi arrayen h-sorterad för ett stort värde på h. Vi fortsätter att minska värdet på h tills det blir 1. En array sägs vara h-sorterad om alla underlistor av varje hthelementet är sorterat.
Python3 # Python3 program for implementation of Shell Sort def shellSort(arr): gap = len(arr) // 2 # initialize the gap while gap>0: i = 0 j = gap # kontrollera arrayen från vänster till höger # till det sista möjliga indexet för j medan j< len(arr): if arr[i]>arr[j]: arr[i],arr[j] = arr[j],arr[i] i += 1 j += 1 # nu, vi tittar tillbaka från i:t index till vänster # vi byter ut värdena som är inte i rätt ordning. k = i medan k - gap> -1: om arr[k - gap]> arr[k]: arr[k-gap],arr[k] = arr[k],arr[k-gap] k -= 1 lucka //= 2 # drivrutin för att kontrollera koden arr2 = [12, 34, 54, 2, 3] print('input array:',arr2) shellSort(arr2) print('sorted array', arr2)>
Produktion input array: [12, 34, 54, 2, 3] sorted array [2, 3, 12, 34, 54]>
Tidskomplexitet: På2).
